Abstract
To anticipate how a person would act in the future, it is essential to understand the human intention since it guides the subject towards a certain action. In this paper, we propose a hierarchical architecture which assumes a sequence of human action (low-level) can be driven from the human intention (high-level). Based on this, we deal with long-term action anticipation task in egocentric videos. Our framework first extracts this low- and high-level human information over the observed human actions in a video through a Hierarchical Multi-task Multi-Layer Perceptrons Mixer (H3M). Then, we constrain the uncertainty of the future through an Intention-Conditioned Variational Auto-Encoder (I-CVAE) that generates multiple stable predictions of the next actions that the observed human might perform. By leveraging human intention as high-level information, we claim that our model is able to anticipate more time-consistent actions in the long-term, thus improving the results over the baseline in Ego4D dataset. This work results in the state-of-the-art for Long-Term Anticipation (LTA) task in Ego4D by providing more plausible anticipated sequences, improving the anticipation scores of nouns and actions. Our work ranked first in both CVPR@2022 and ECCV@2022 Ego4D LTA Challenge.

How does it work?
reextracted features for N observed videos are fed to our Hierarchical Multitask MLP Mixer model (H3M) to obtain low-level action labels and high-level intention. Results are fed into our Intention-Conditioned Variational AutoEncoder (I-CVAE) that anticipates subsequent Z actions.
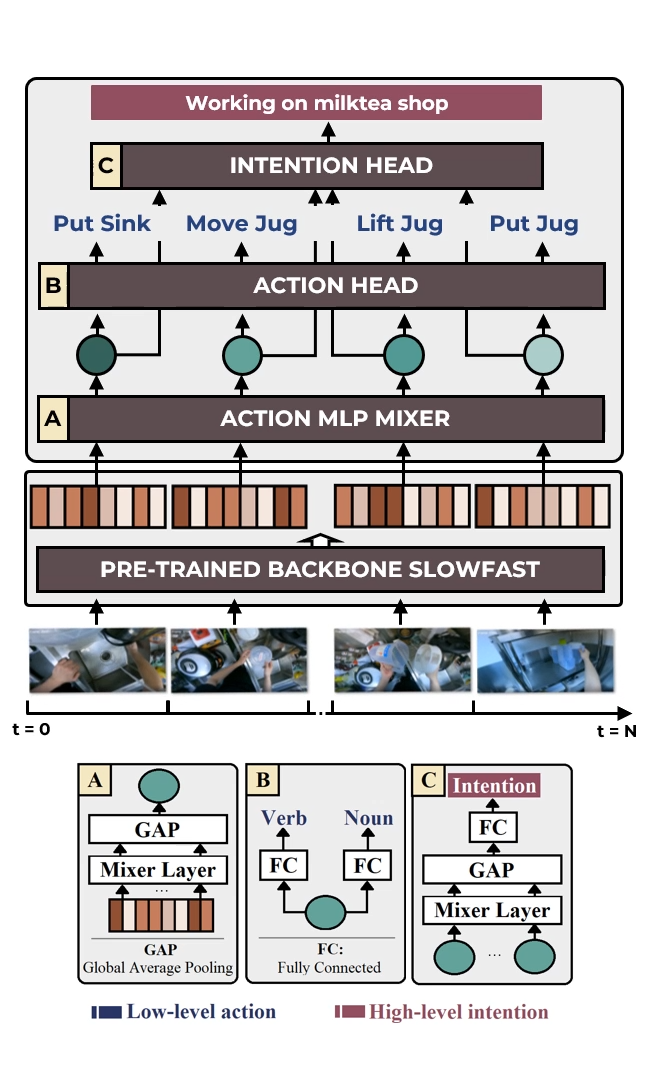
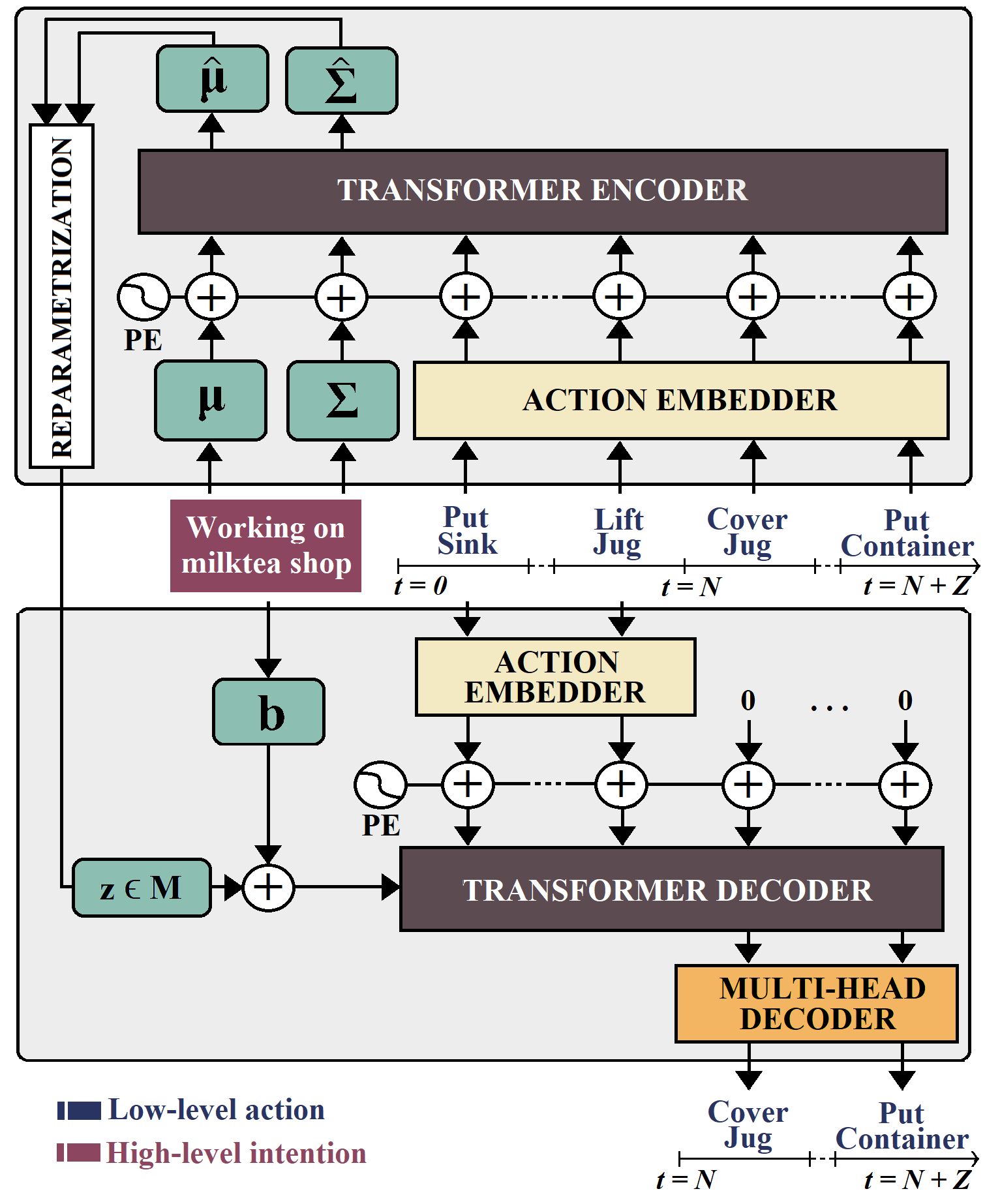
Results
The task of long-term action anticipation (LTA) consists on anticipating the future actions of a human given the observation of its past. Our model efficiently exploits the human intention as a condition to increase the confidence of our model for LTA. Experiments demonstrate that conditioning the model through the human intention has a direct effect when improving realistic anticipation. We tackle this LTA task in the largest egocentric dataset available, Ego4D, and showcase that our approach outperforms state-of-the-art in the Ego4D LTA task, mainly when forecasting nouns and actions. Our work ranked first in both CVPR@2022 and ECCV@2022 Ego4D LTA Challenge.



BibTeX
@InProceedings{Mascaro_2023_WACV,
author = {Mascaro, Esteve Valls and Ahn, Hyemin and Lee, Dongheui},
title = {Intention-Conditioned Long-Term Human Egocentric Action Anticipation},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {January},
year = {2023},
pages = {6048-6057}
}