Abstract
The synthesis of human motion has traditionally been addressed through task-dependent models that focus on specific challenges, such as predicting future motions or filling in intermediate poses conditioned on known key-poses. In this paper, we present a novel task-independent model called MASK-M, which can effectively address these challenges using a unified architecture. Our model obtains comparable or better performance than the state-of-the-art in each field. Inspired by Vision Transformers (ViTs), our MASK-M model decomposes a human pose into body parts to leverage the spatio-temporal relationships existing in human motion. Moreover, we reformulate various pose-conditioned motion synthesis tasks as a reconstruction problem with different masking patterns given as input. By explicitly informing our model about the masked joints, our MASK-M becomes more robust to occlusions. Experimental results show that our model successfully forecasts human motion on the Human3.6M dataset. Moreover, it achieves state-of-the-art results in motion inbetweening on the LaFAN1 dataset, particularly in long transition periods.
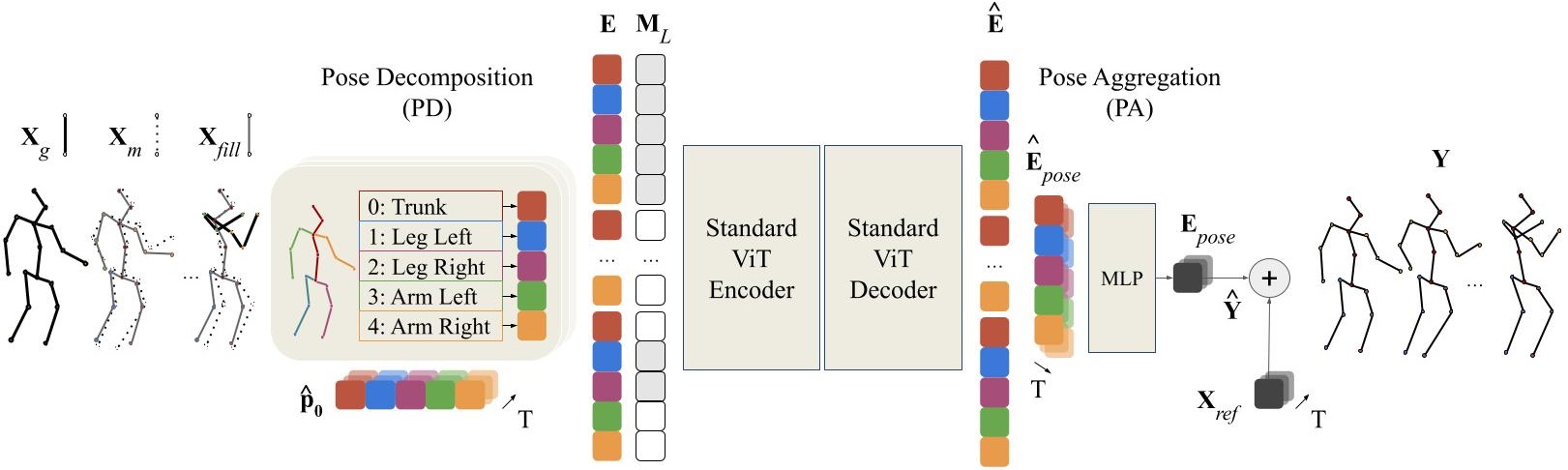
How does it work?
Let a human motion X and its respective binary mask M. We first interpolate Xg to obtain Xfill and provide consistency to the input. Then, our Pose Decomposition module (PD) deconstructs each human pose pt into a sequence of patches p̂t, which we project and flatten to a sequence of tokens E. We add the embmix to E to inform the transformer-based encoder and decoder about the masked tokens and the spatio-temporal structure. Our ViT-based encoder and decoder reconstruct the patch-based sequence of tokens. Our Pose Aggregation module (PA) regroups the decoded tokens into poses using an MLP layer. Finally, each pose is projected back to the joint representations and summed to our reference motion Xref.
Human Motion In-betweening
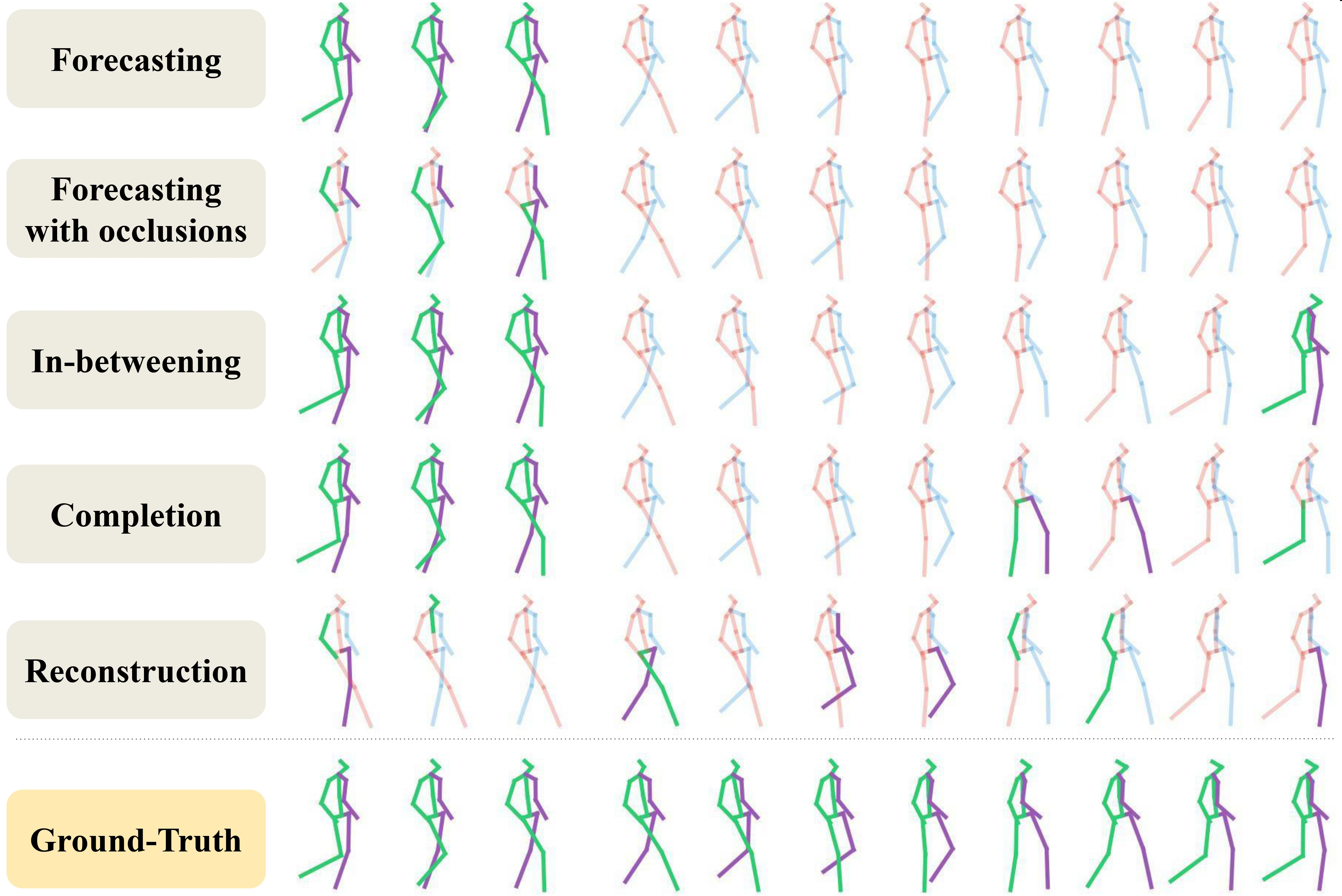
In this task, the model is given a sequence of past poses and a future target pose and the goal is to fill in the motion between these key poses. We evaluate our UNIMASK-M model for motion inbetweening in the LaFAN1 dataset and demonstrate that our model outperforms the current state-of-the-art, performing better for longer transitions thanks to our masked autoencoder strategy.
“Running, stopping and going back”
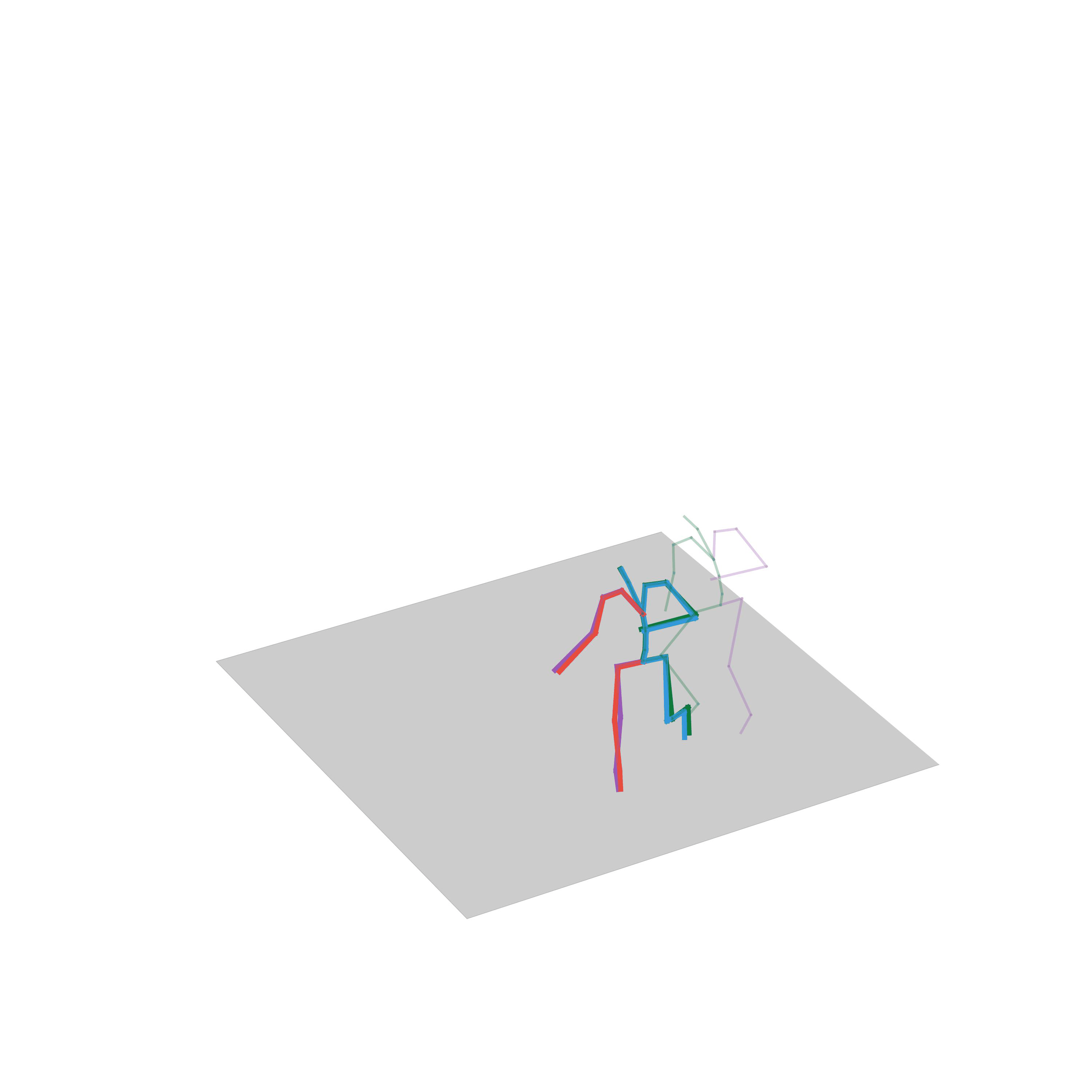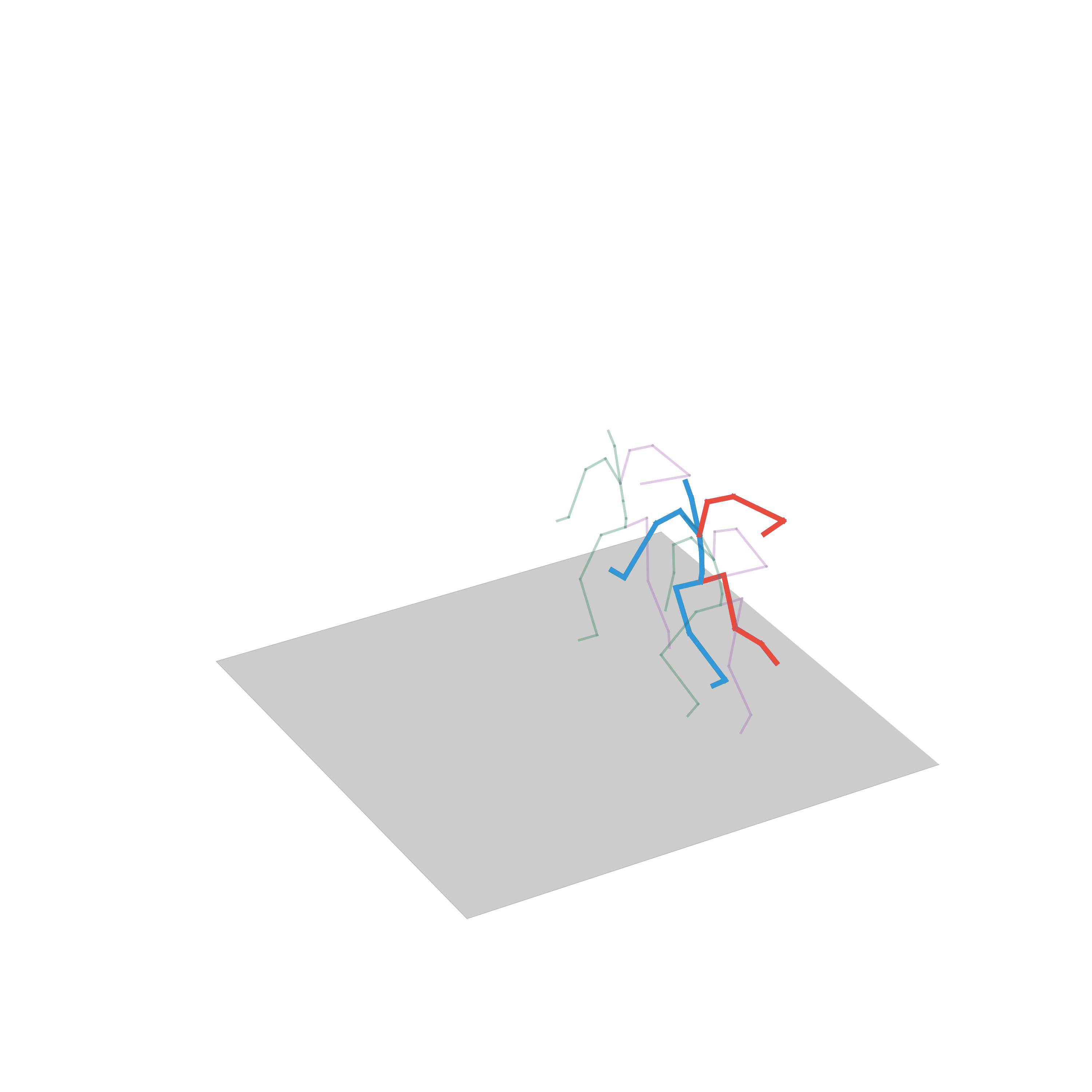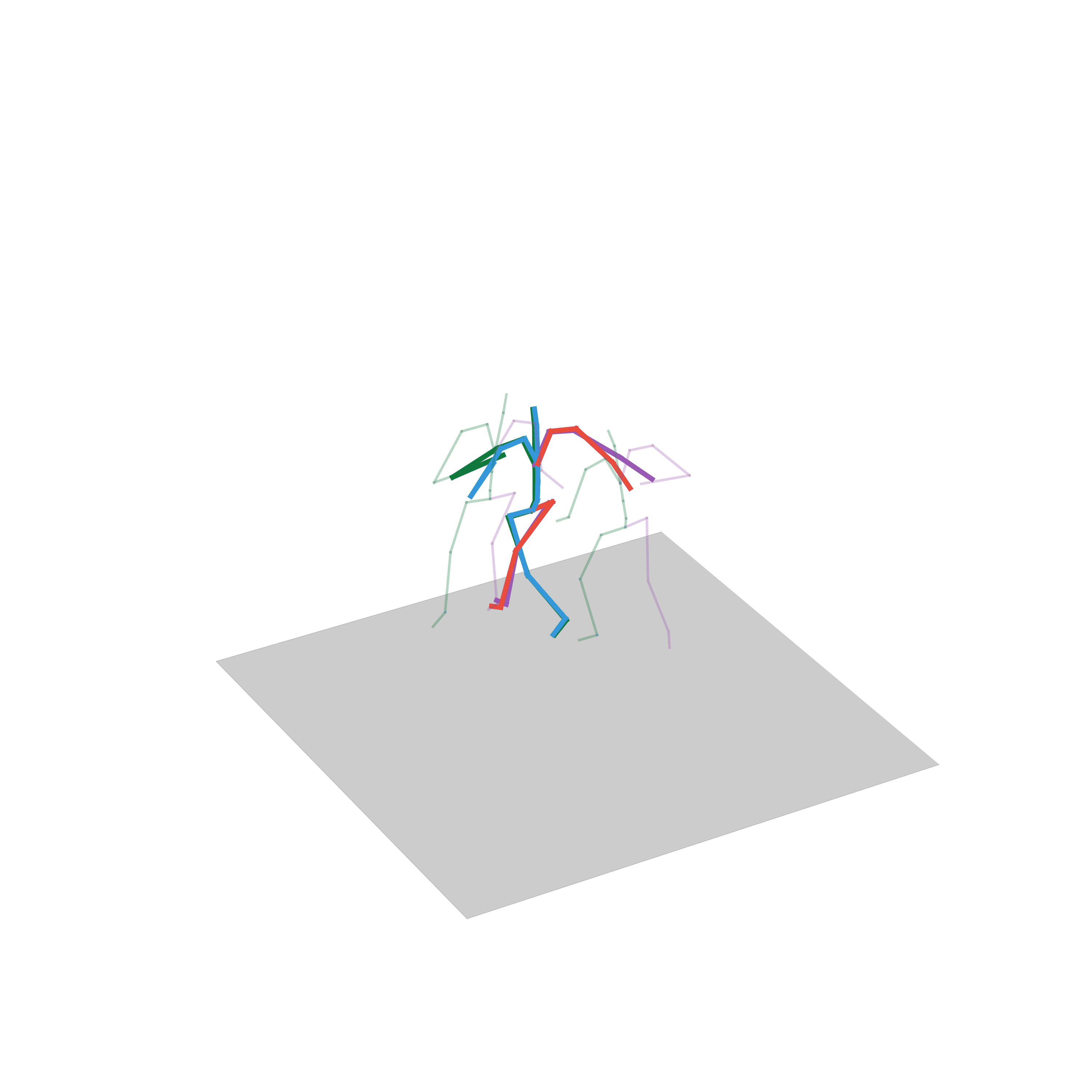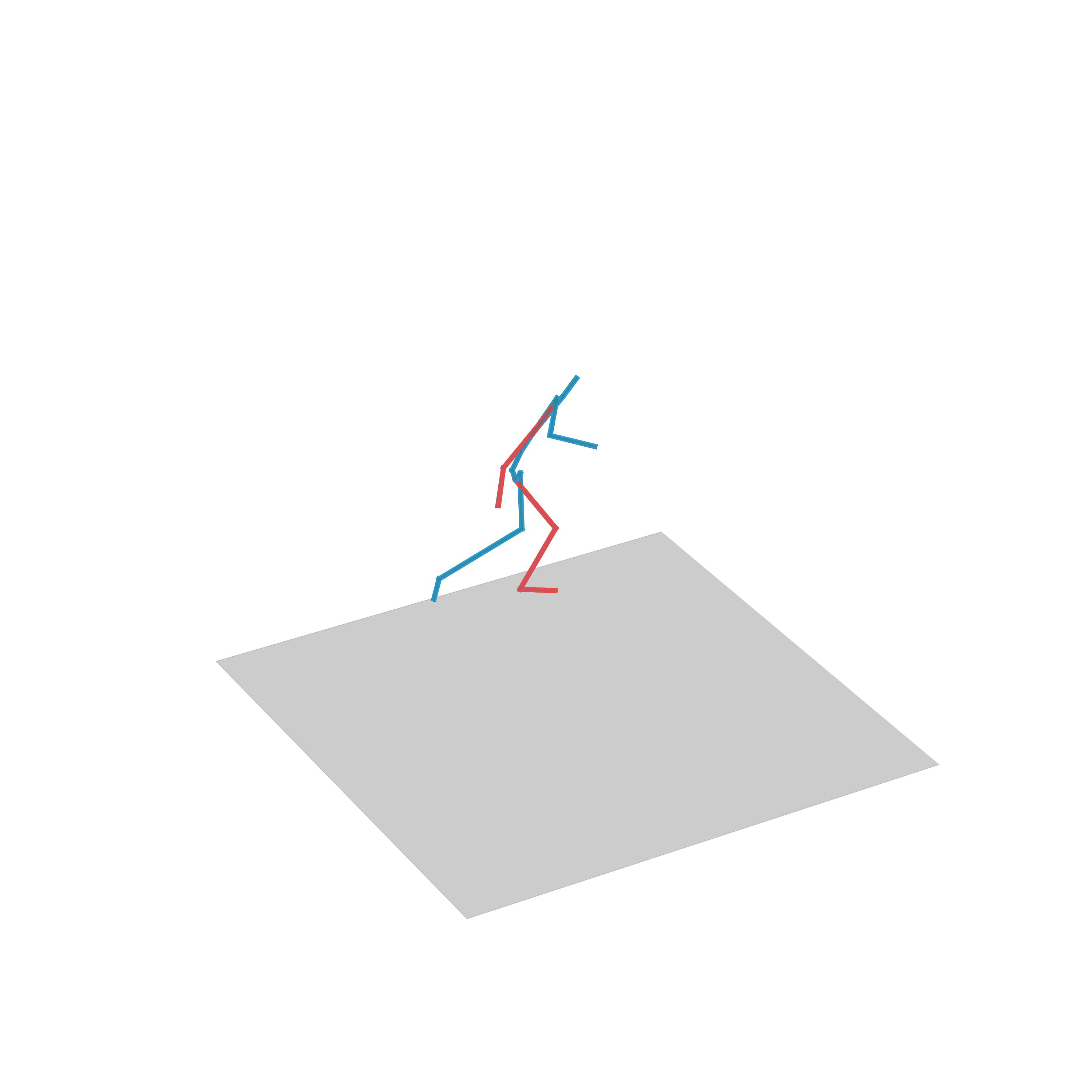
“Walk backwards and forwards”
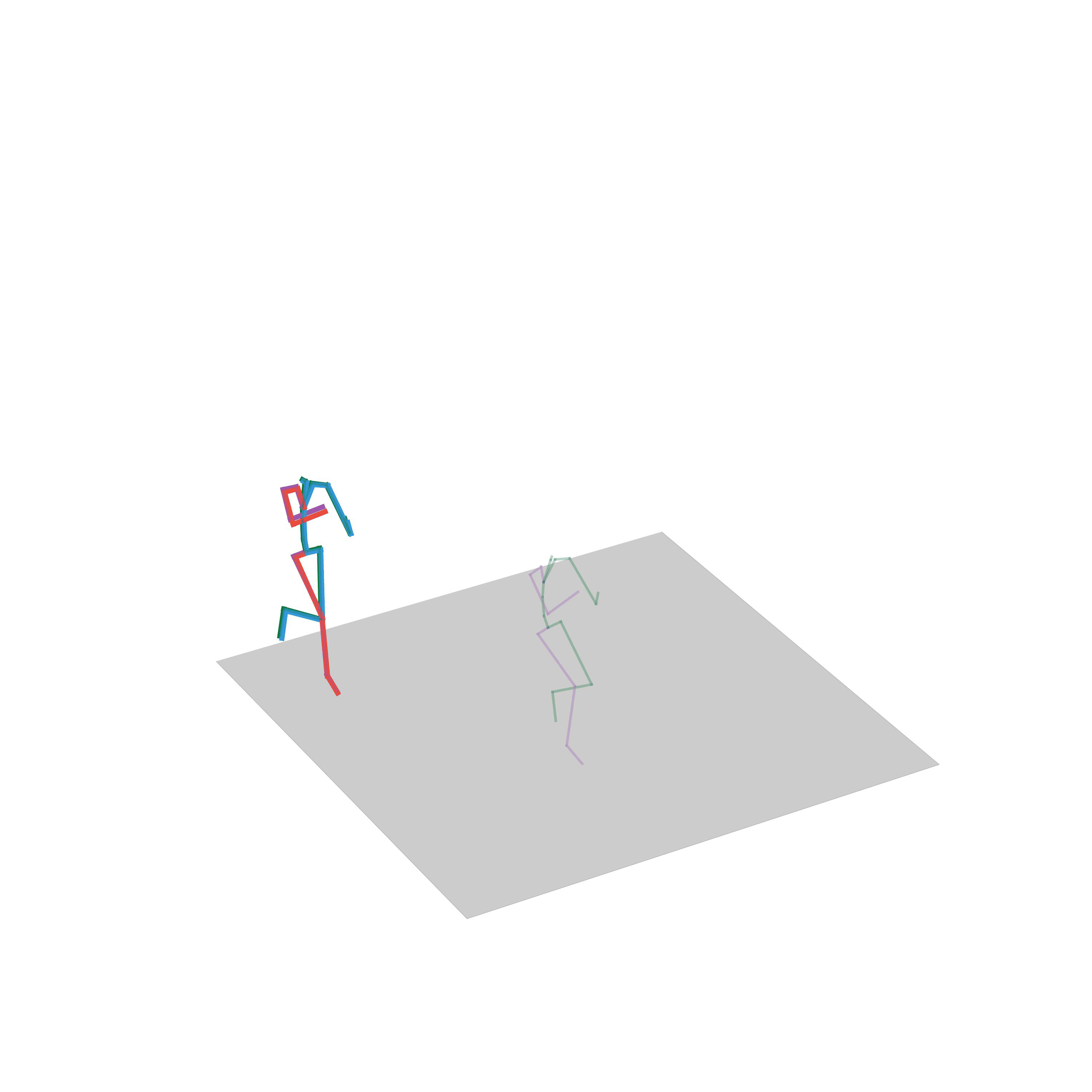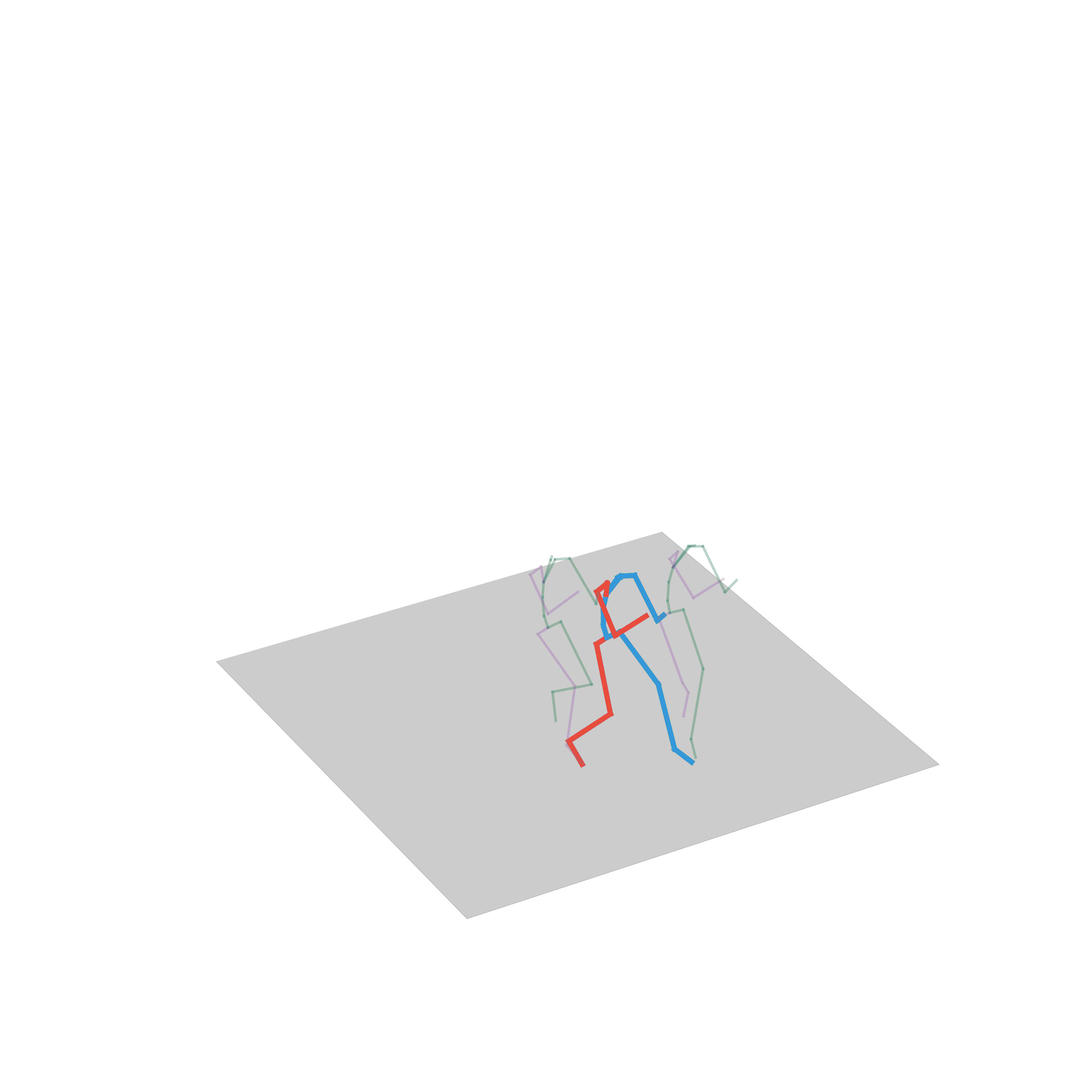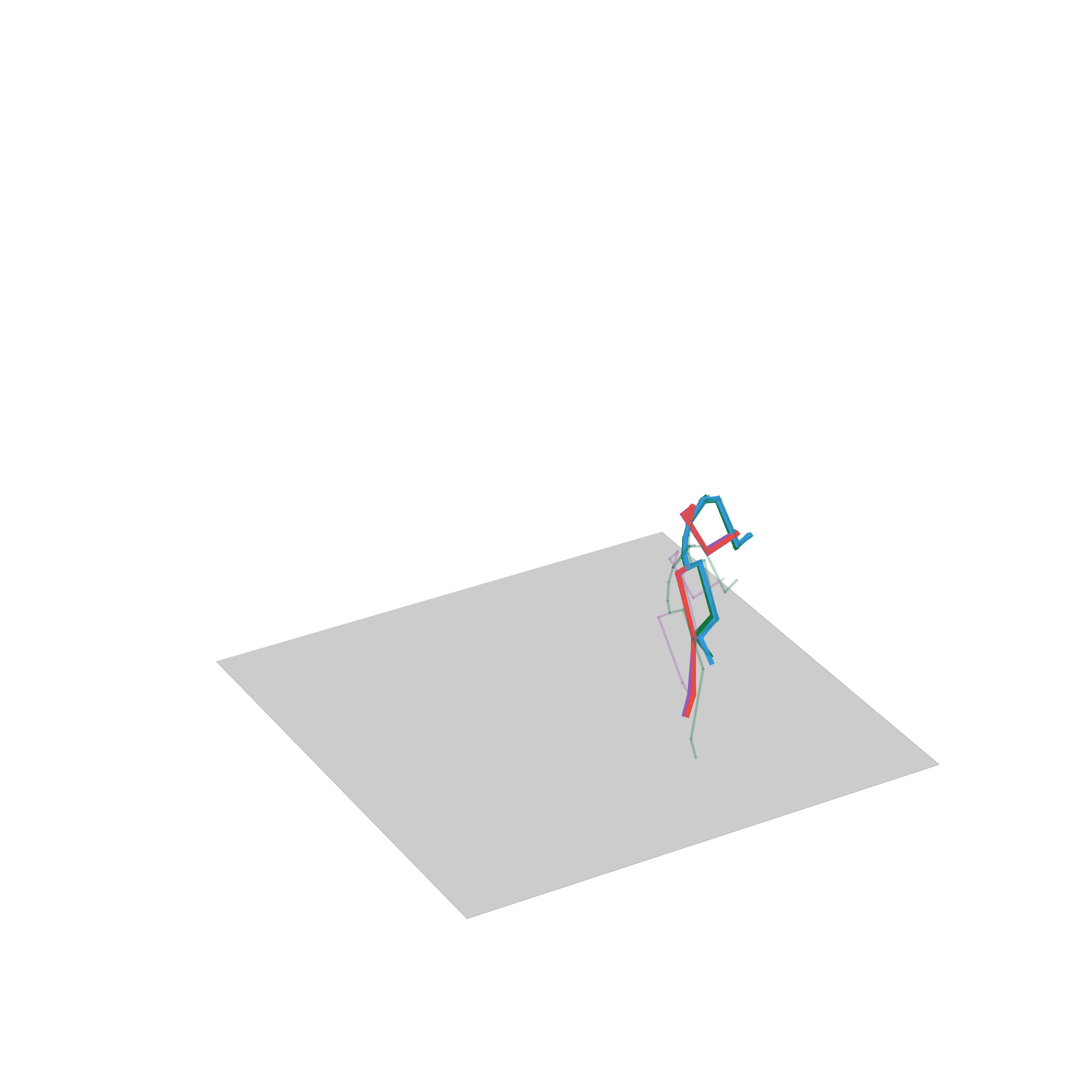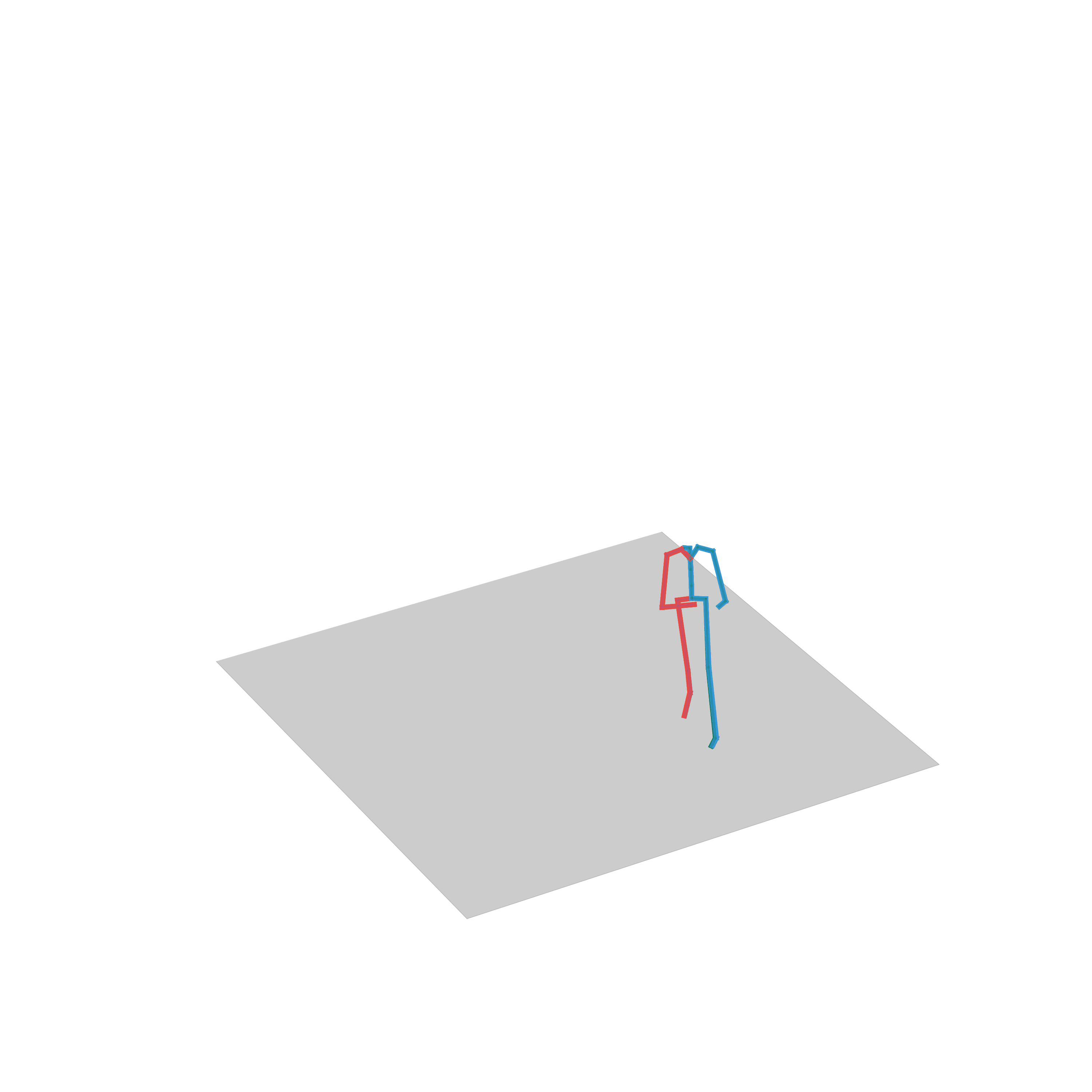
“Avoiding obstacles”
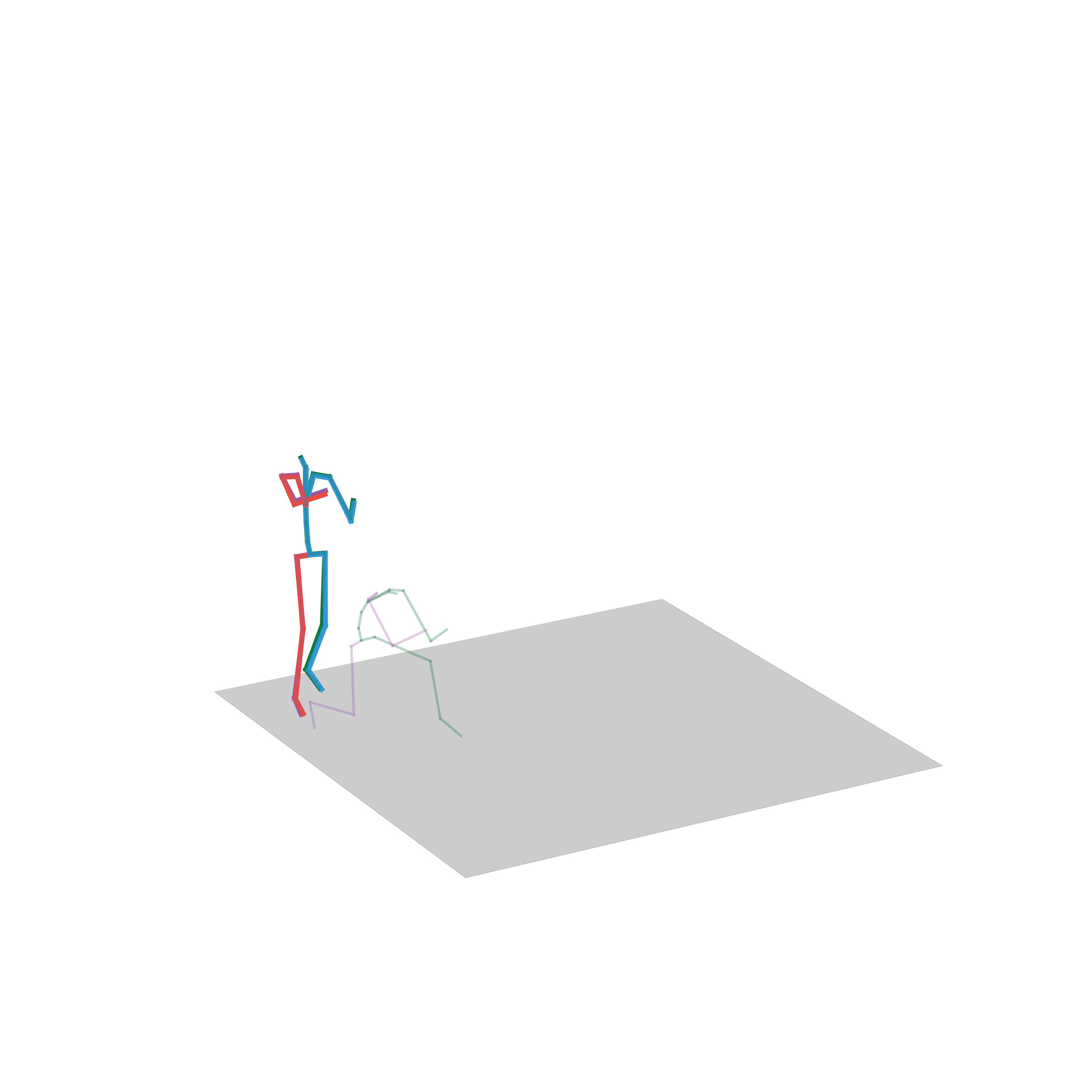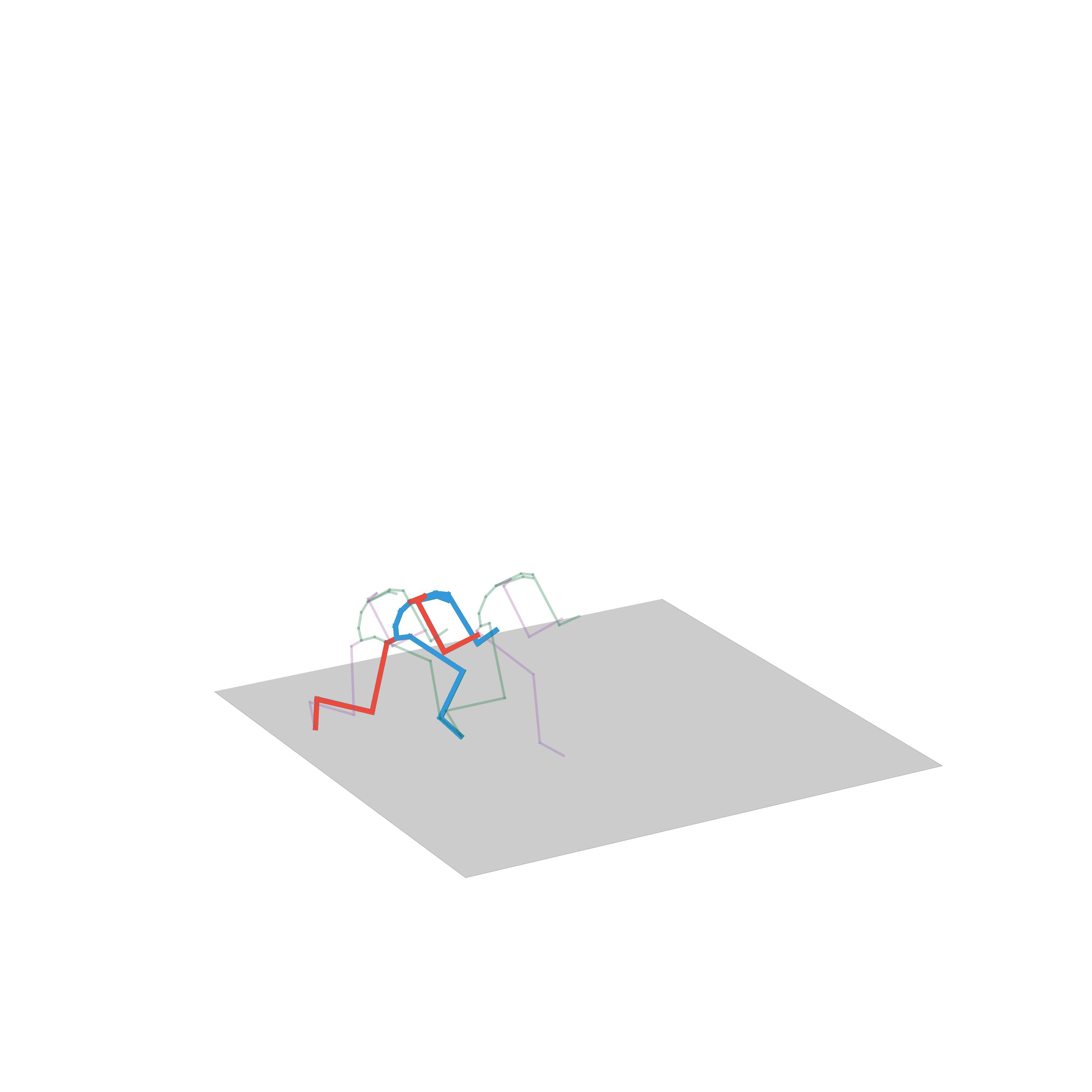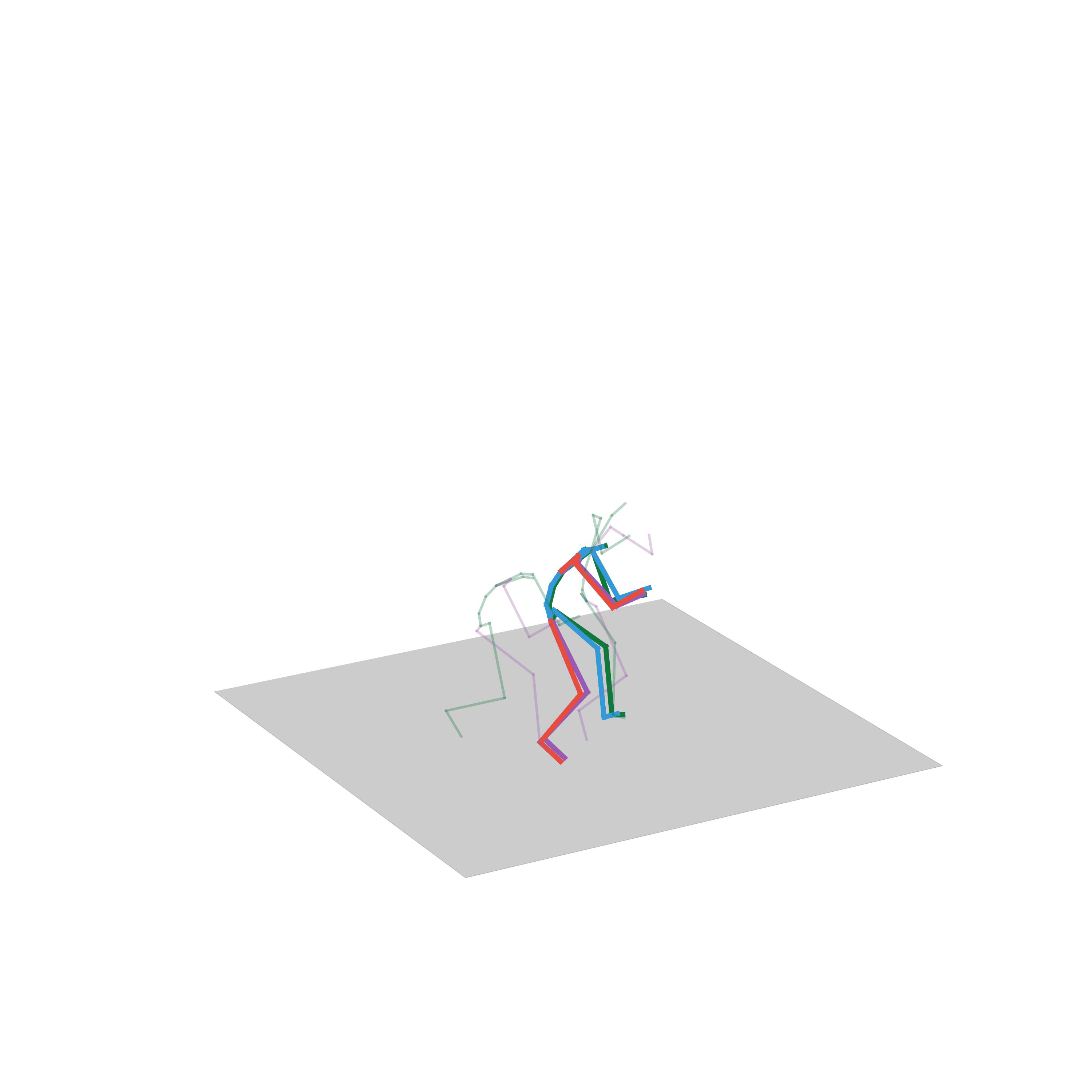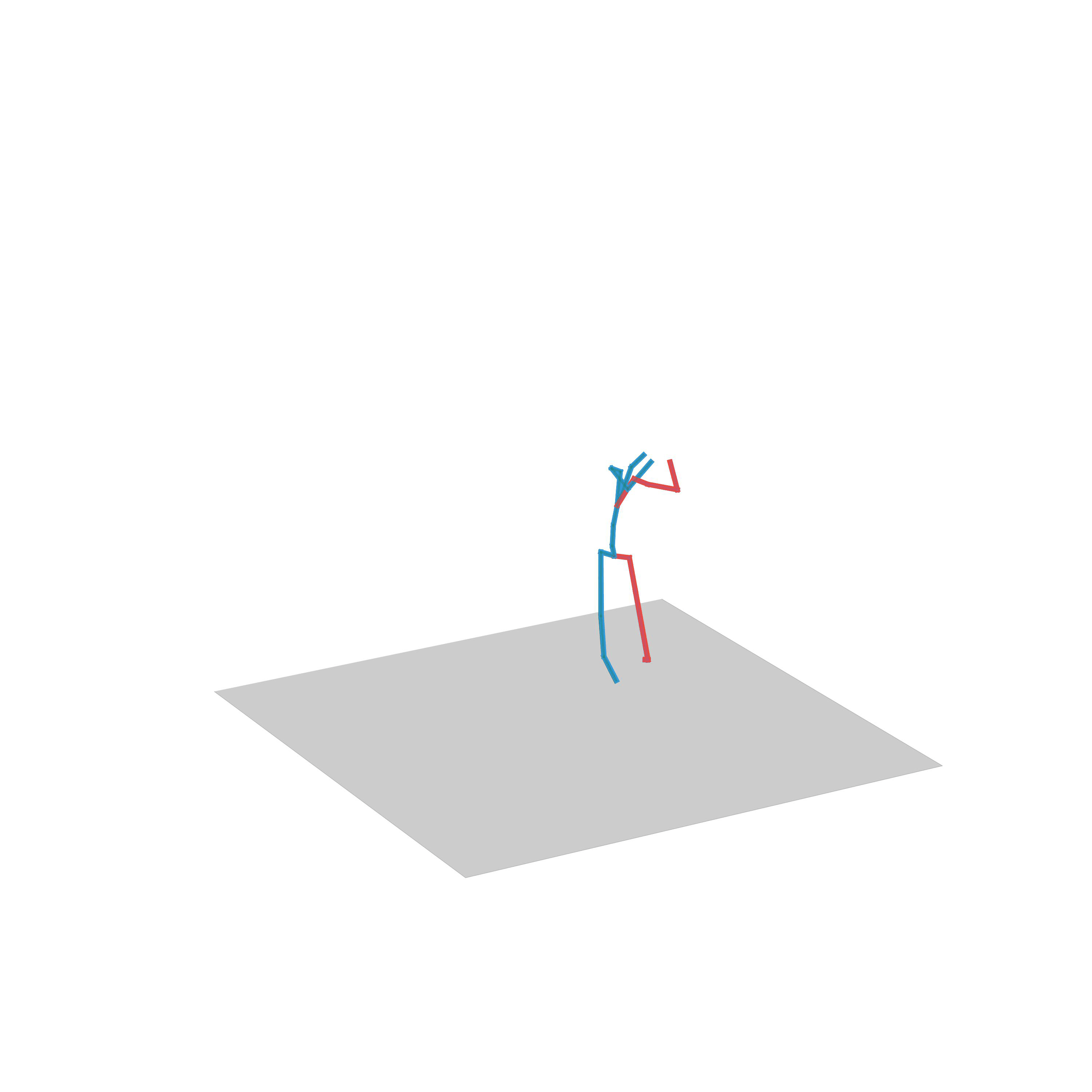
“Crouching”
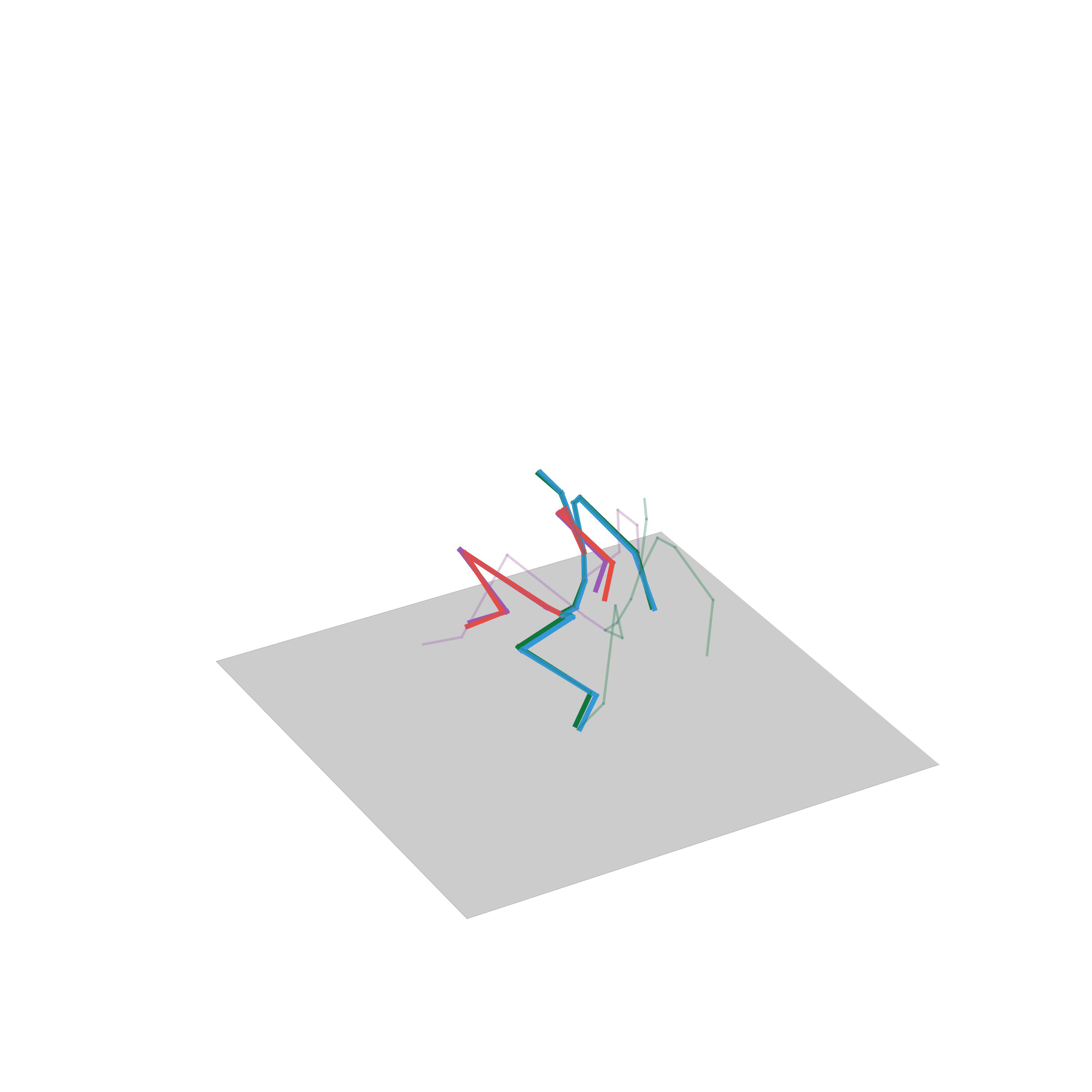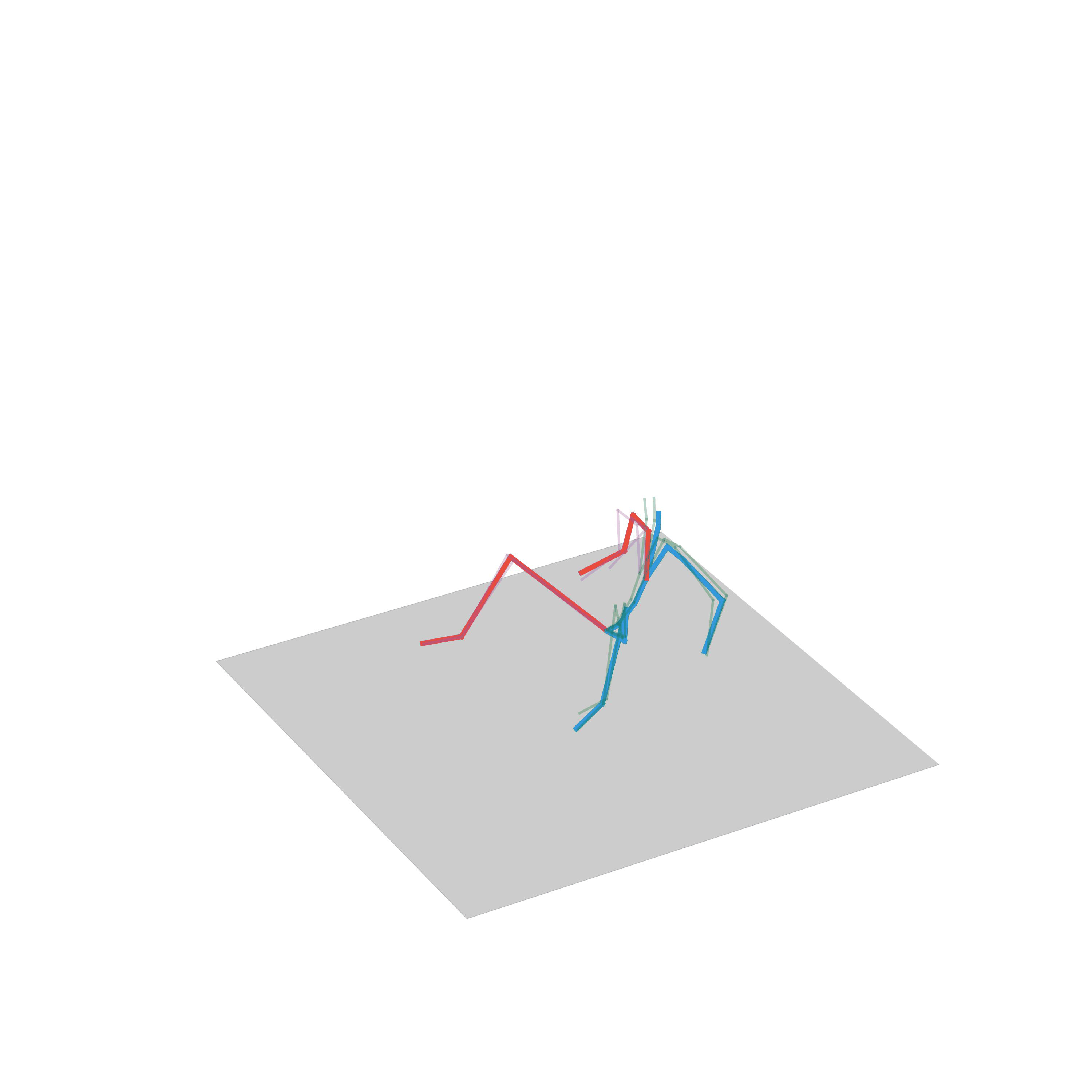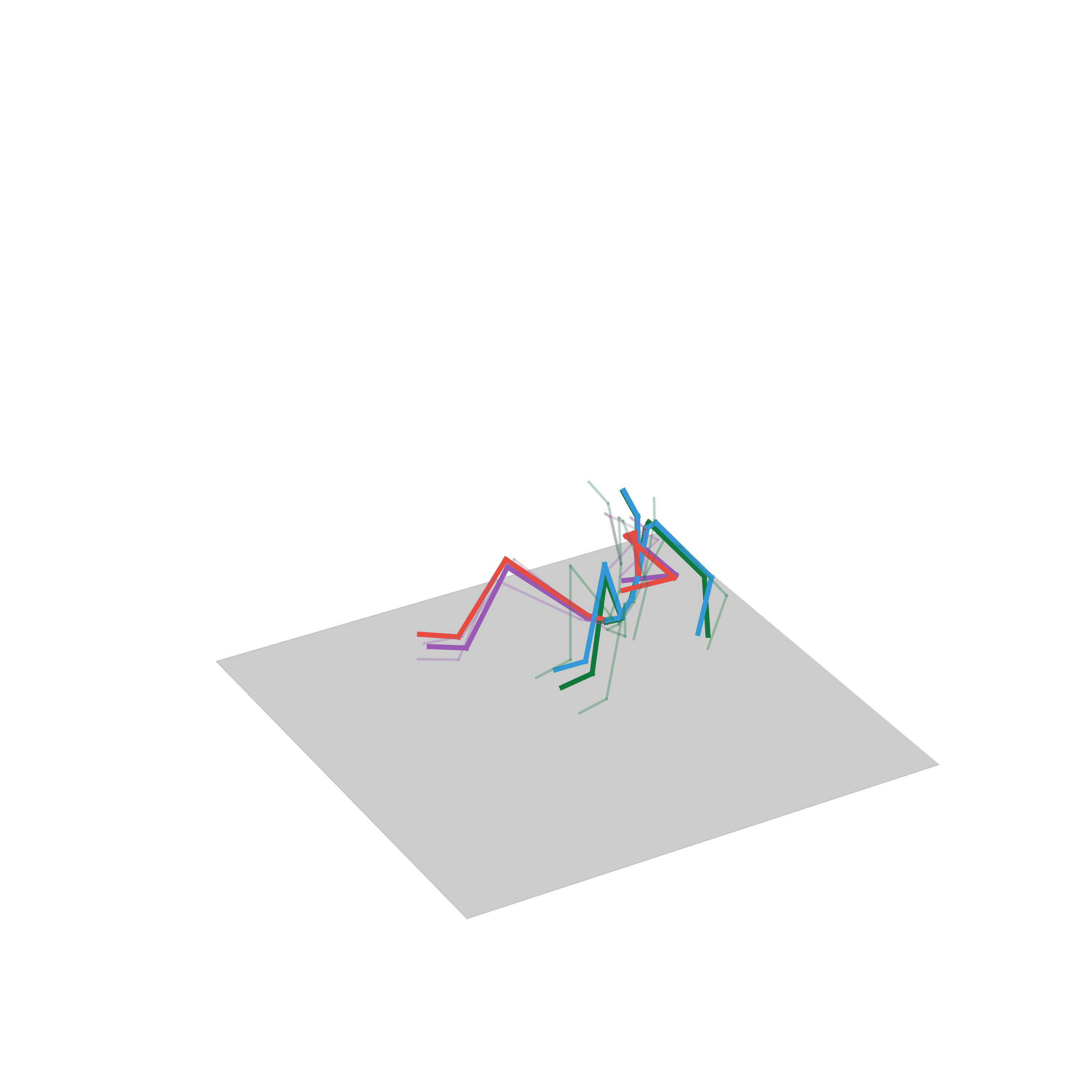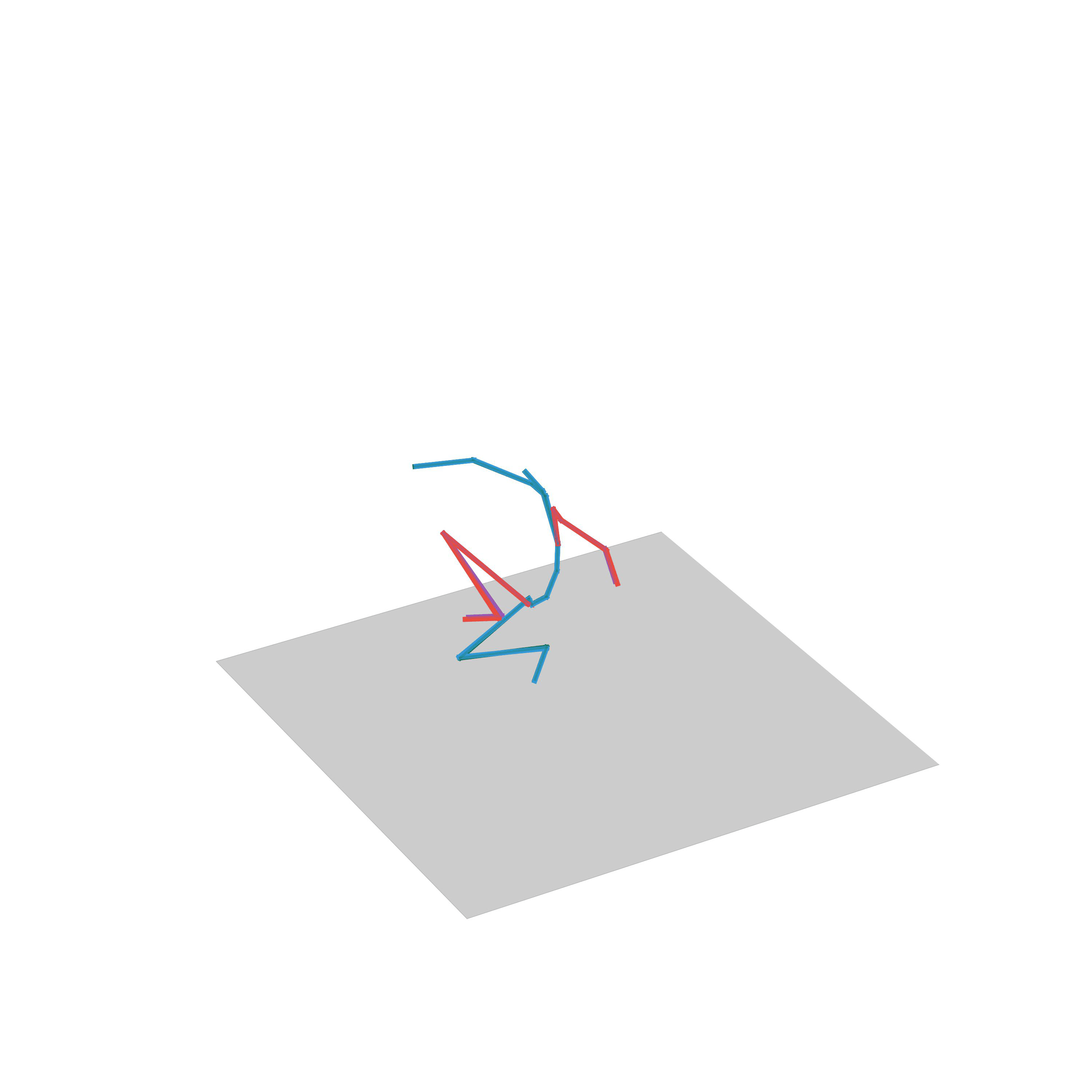
“Jumping on one foot”
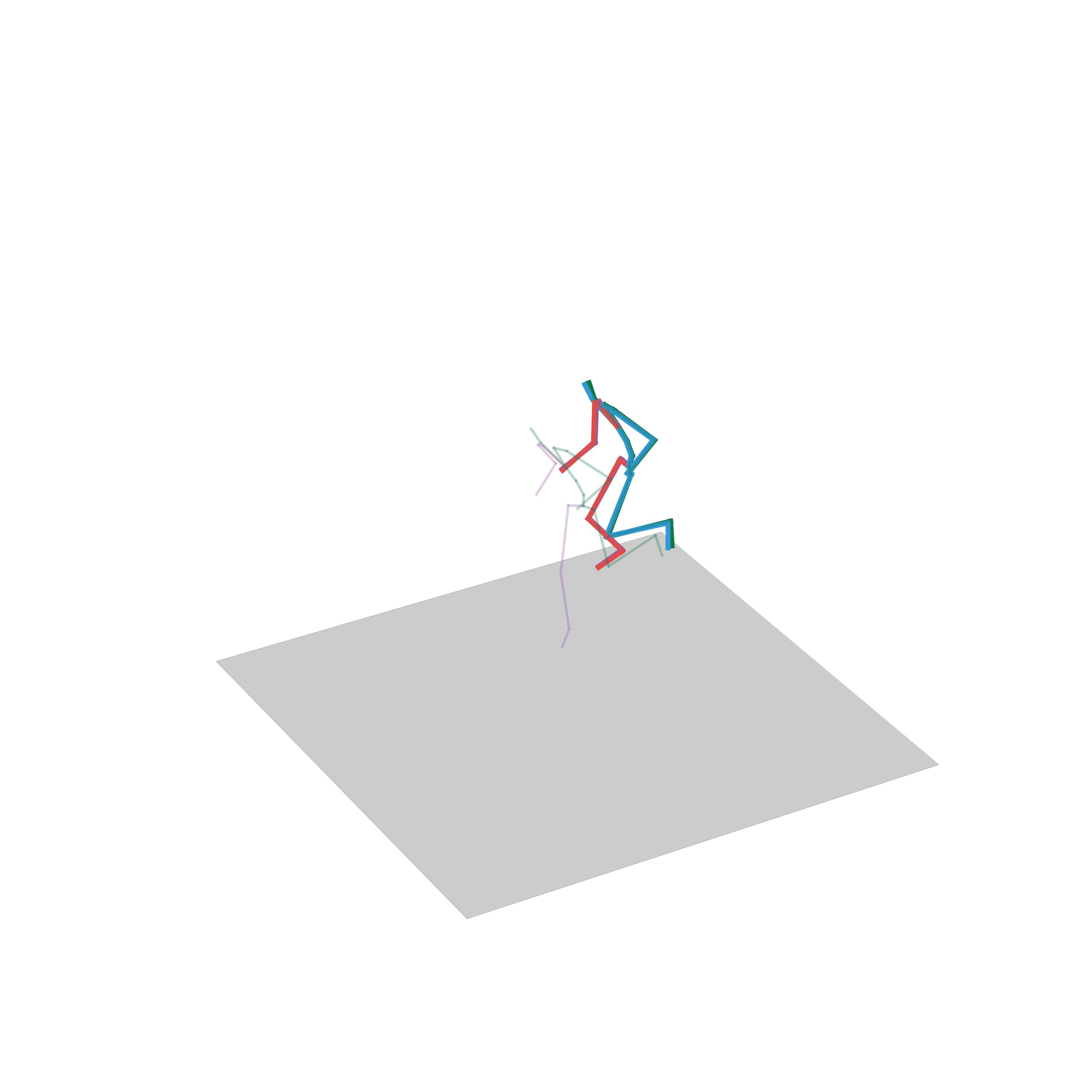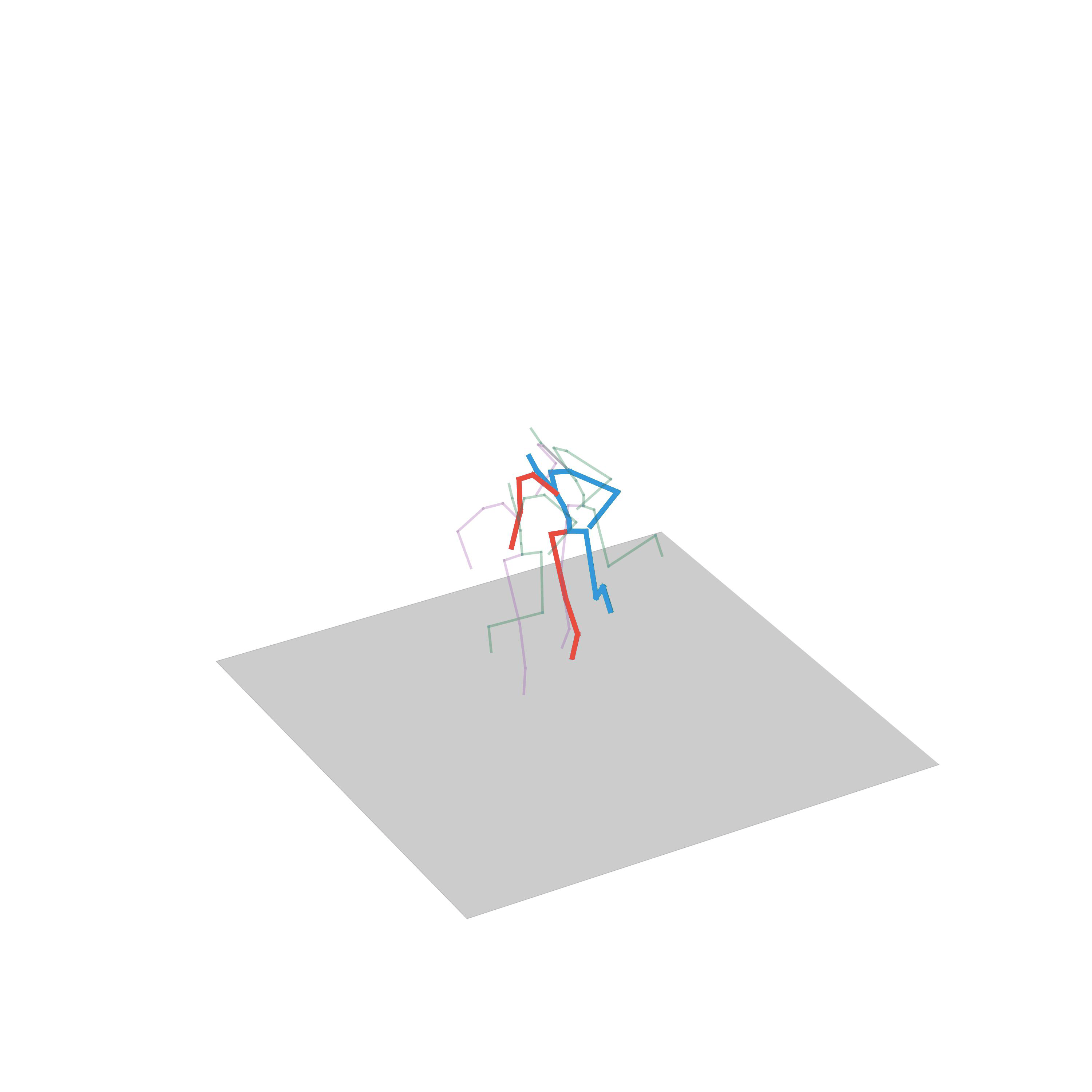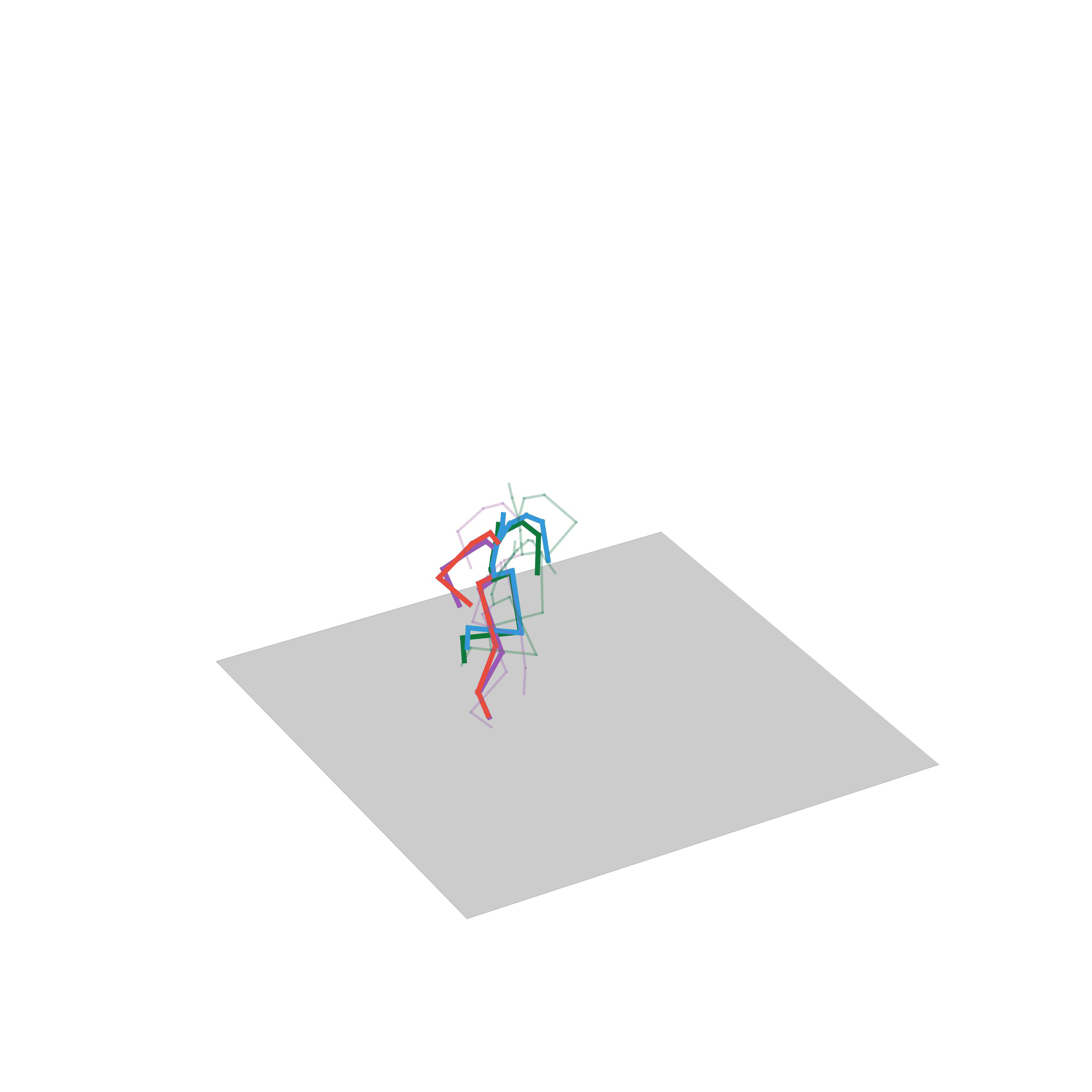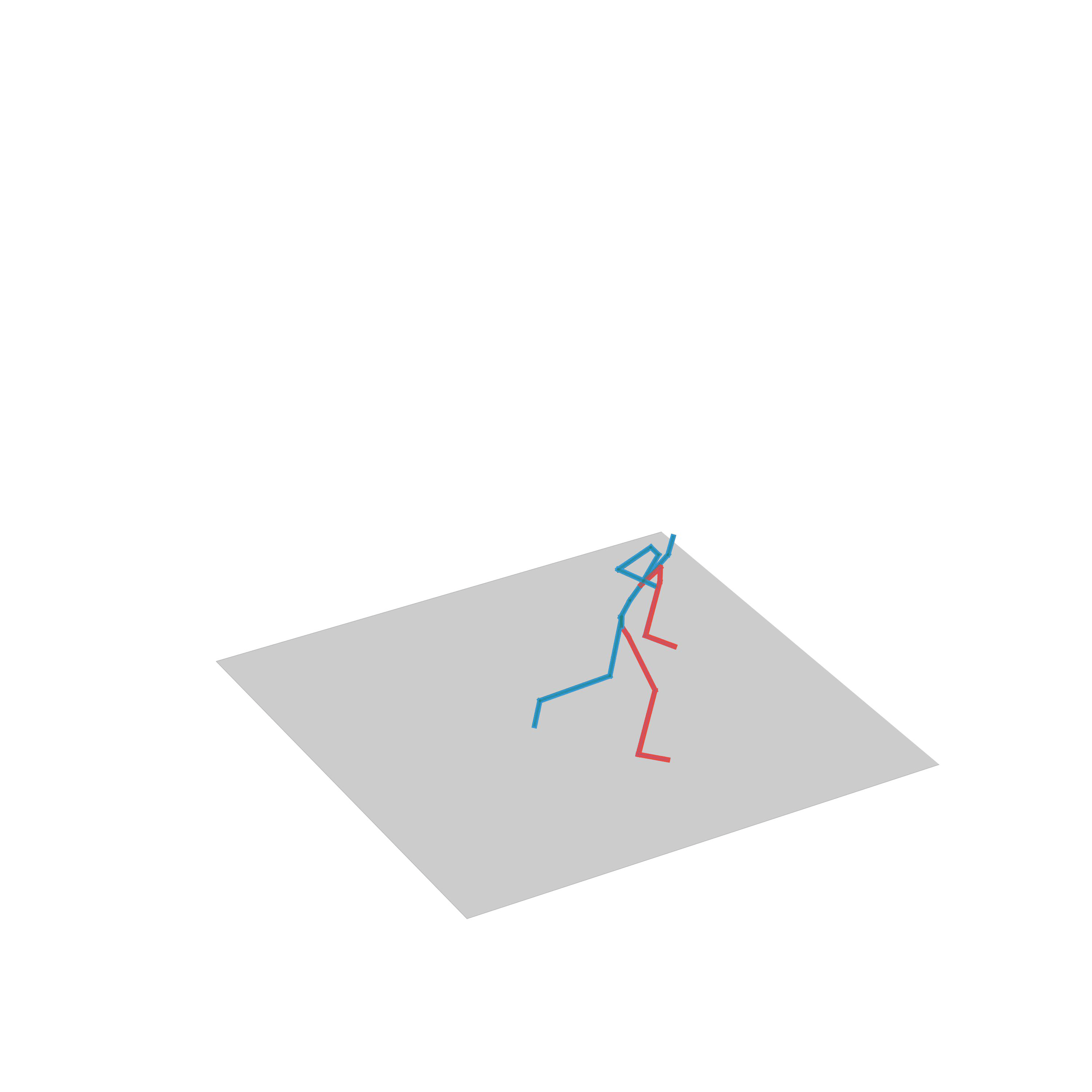
“Jumping on two feet”
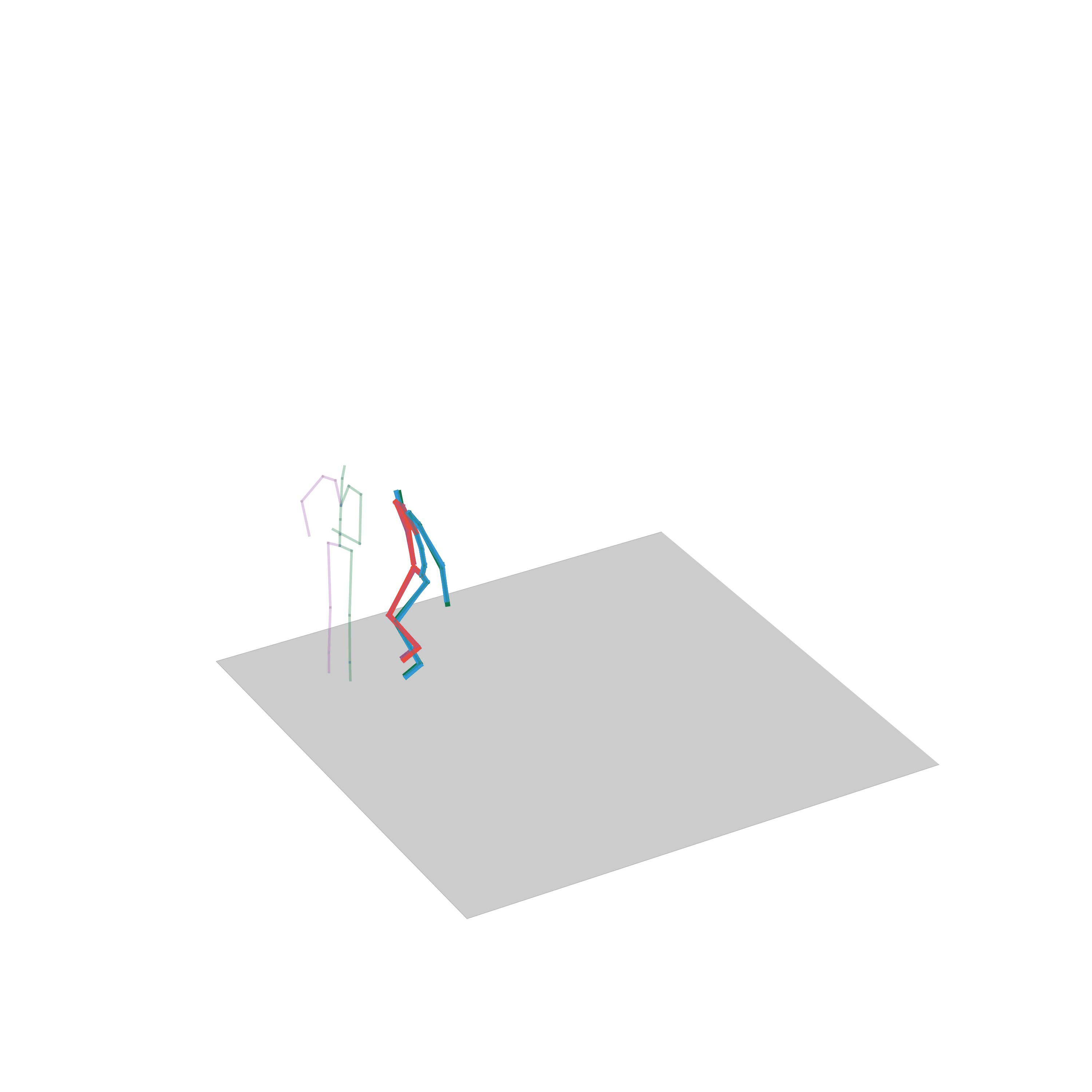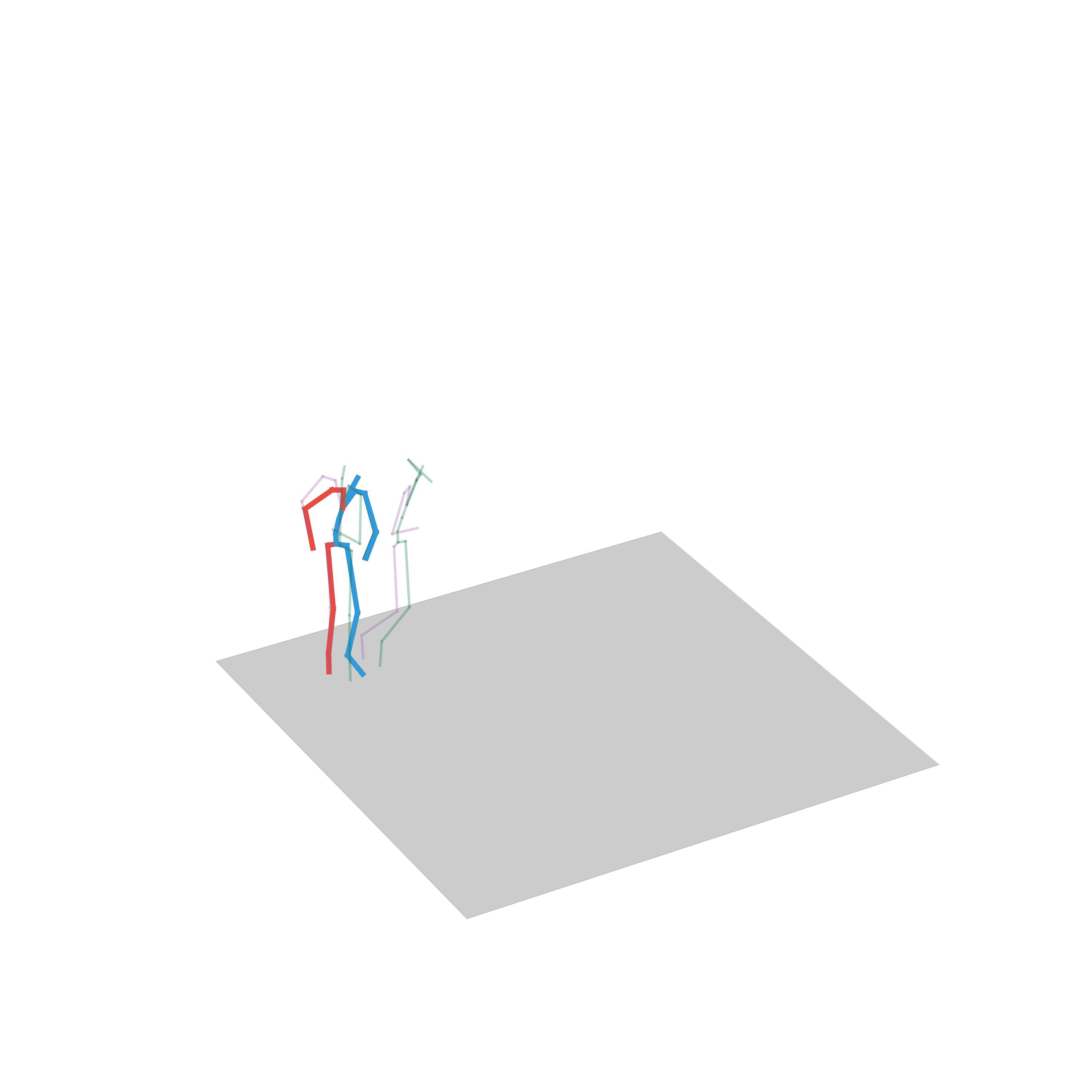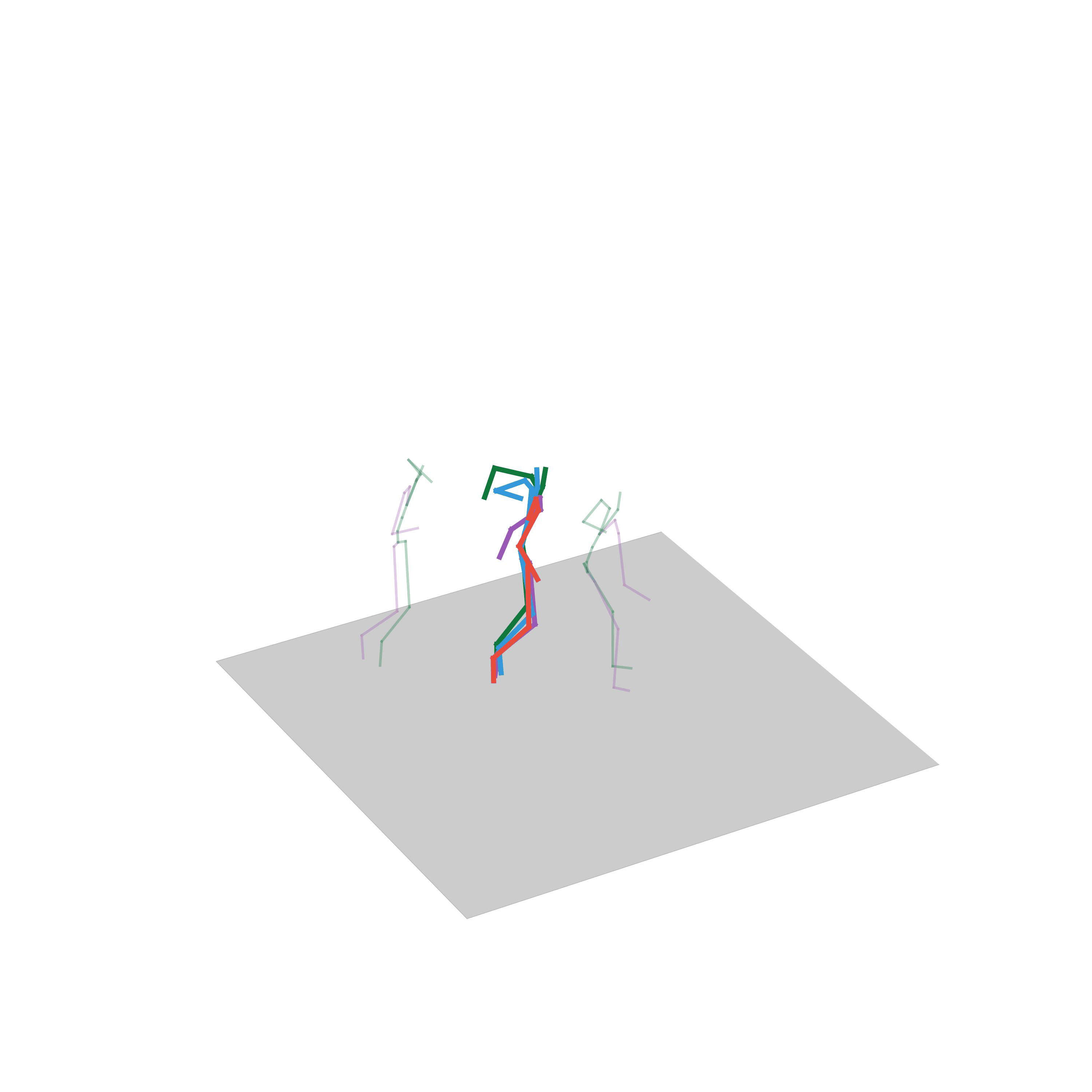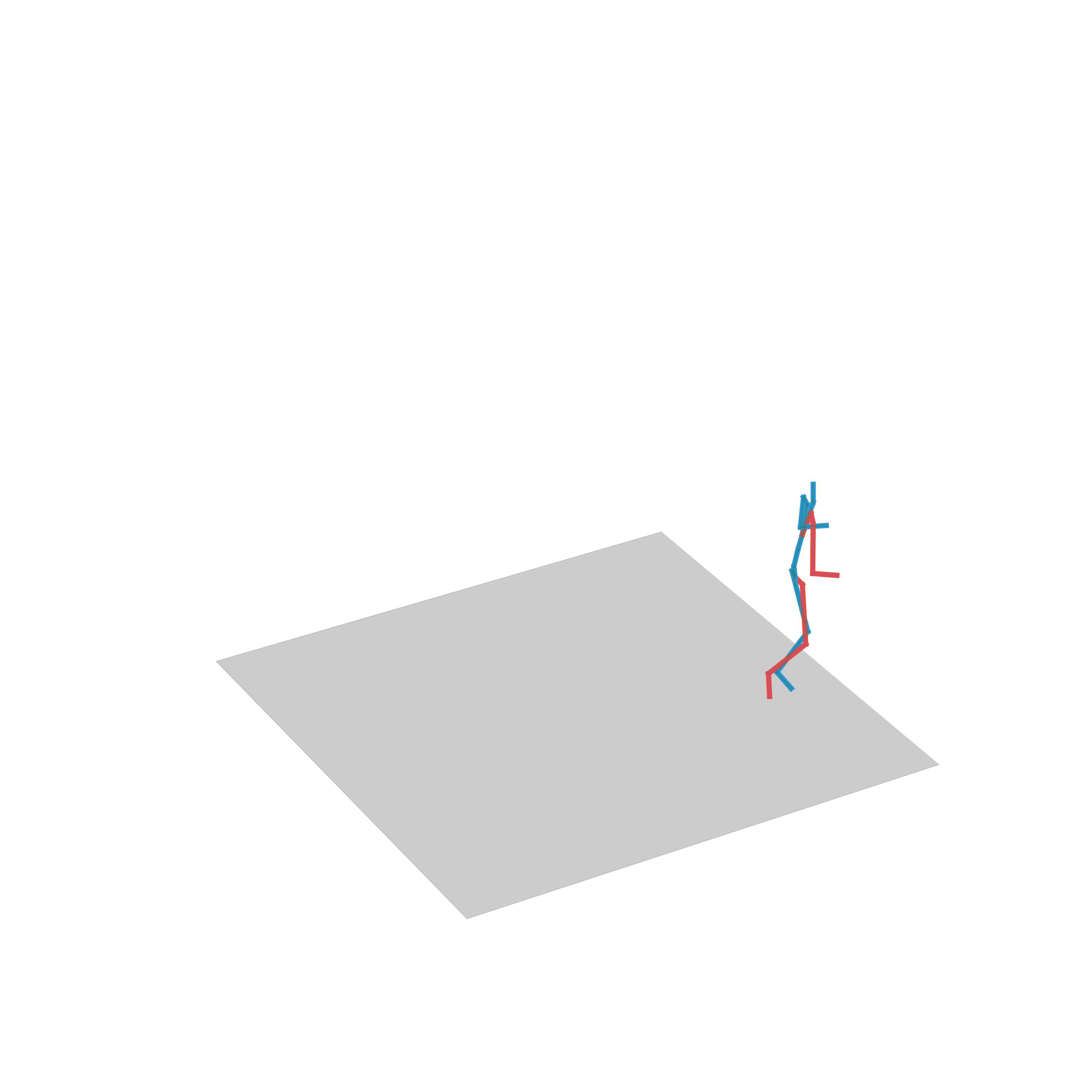
“Walking up the stairs”
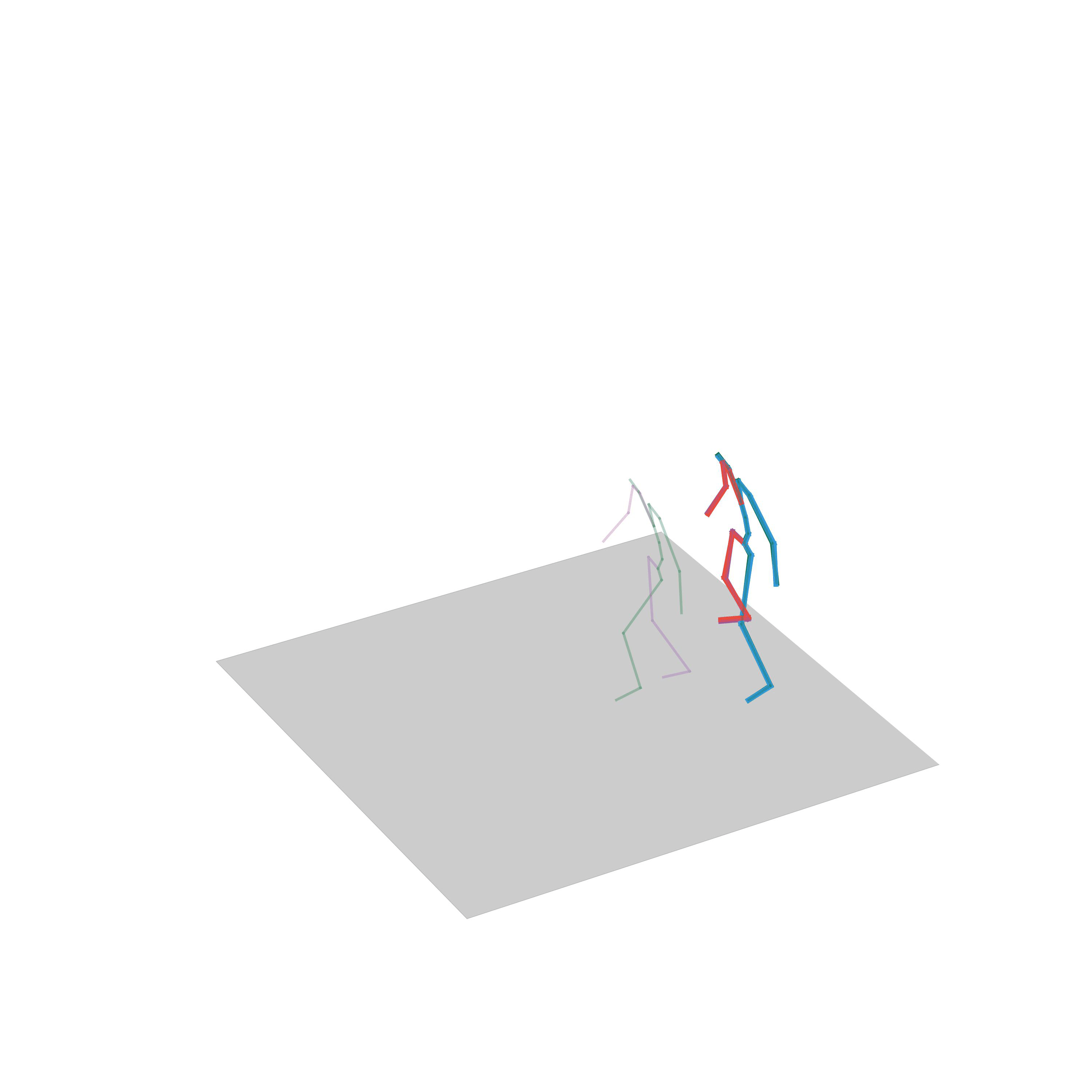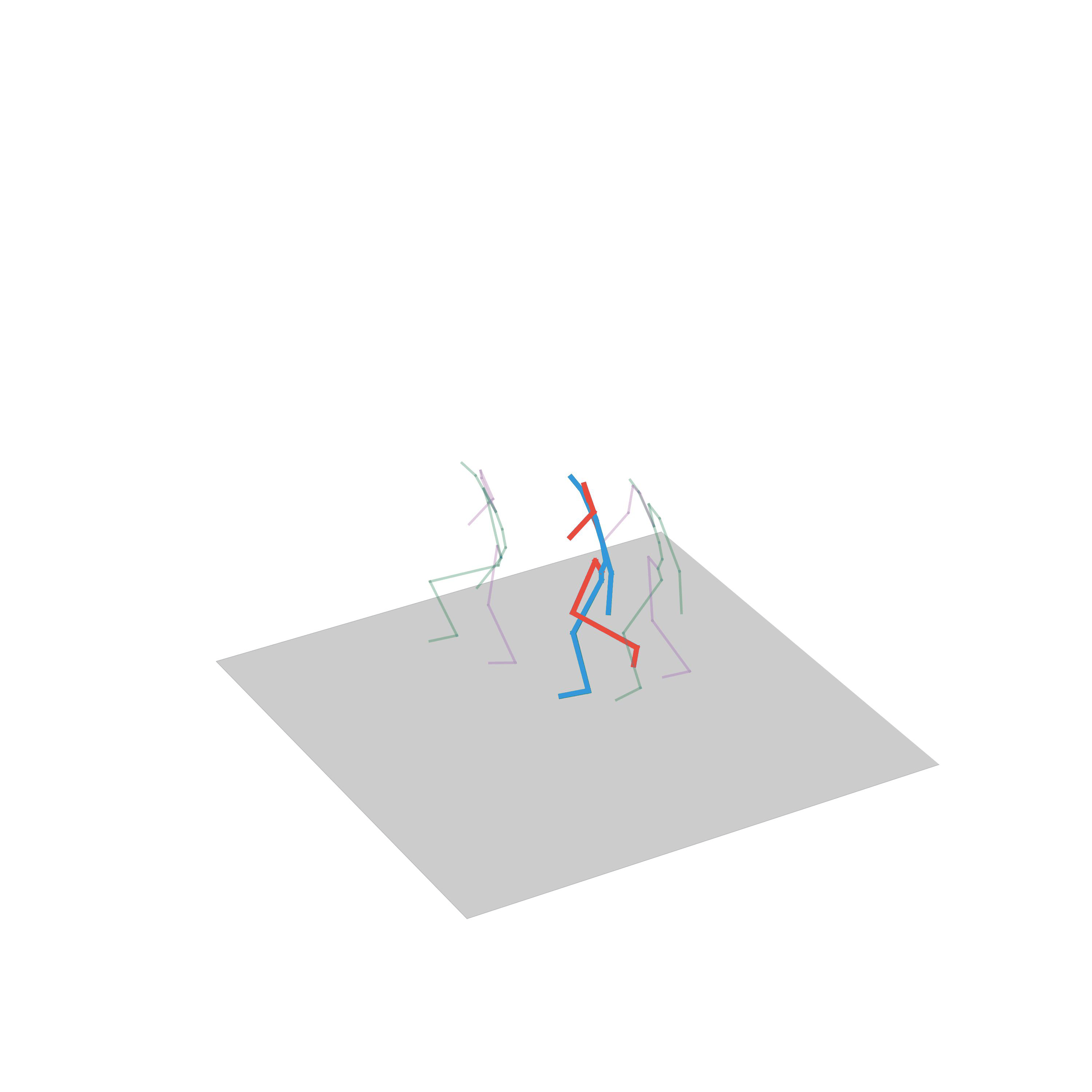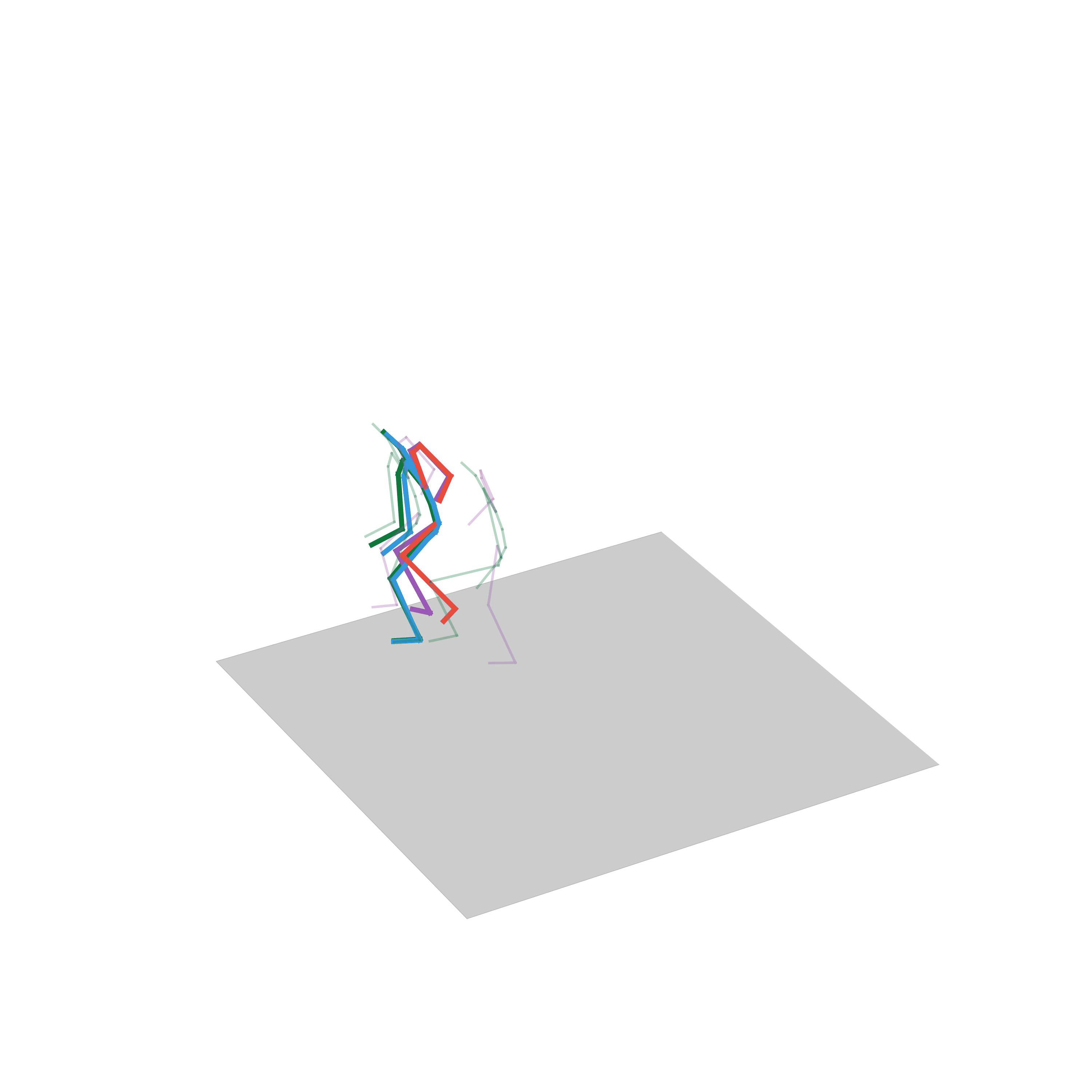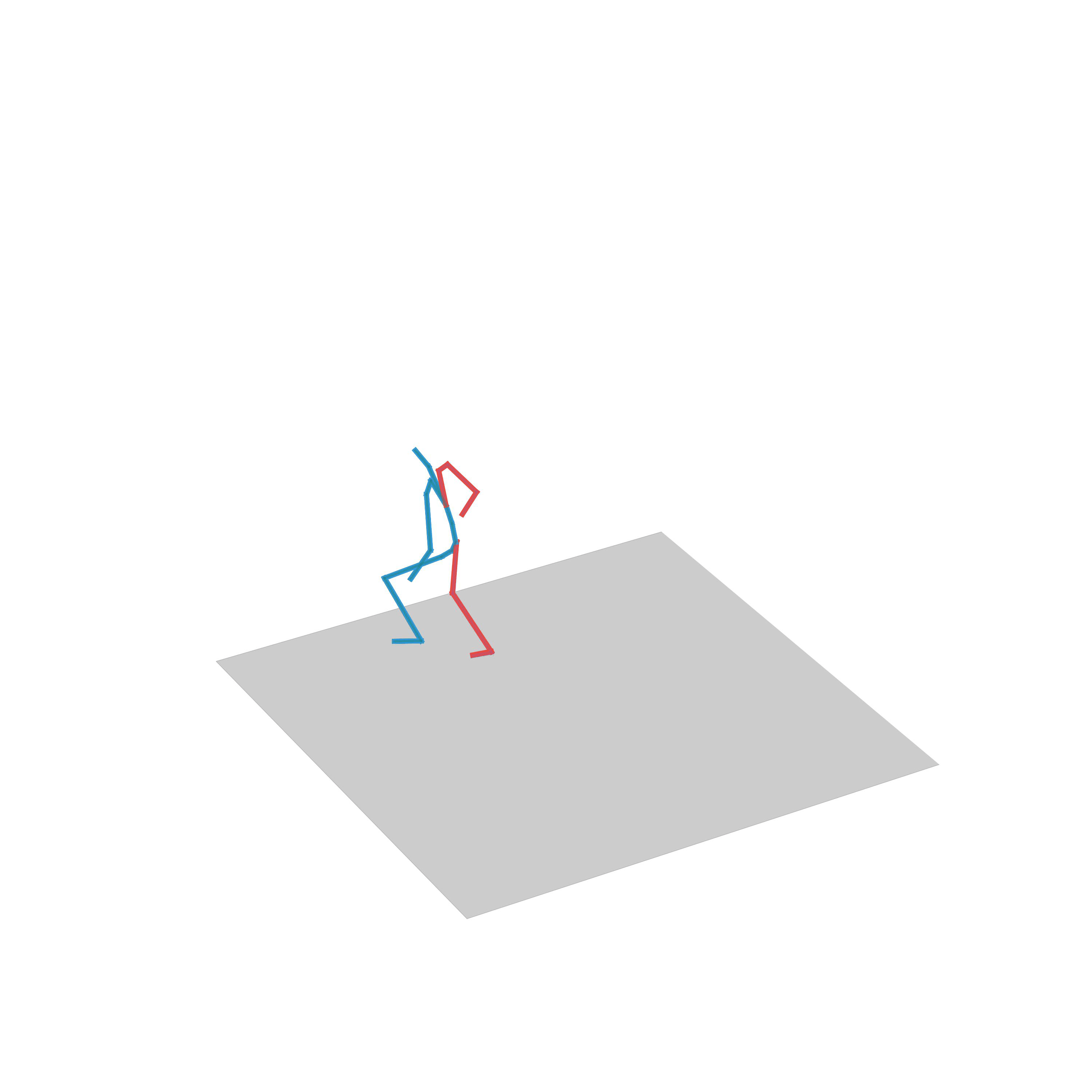
“Jumping on two feet”
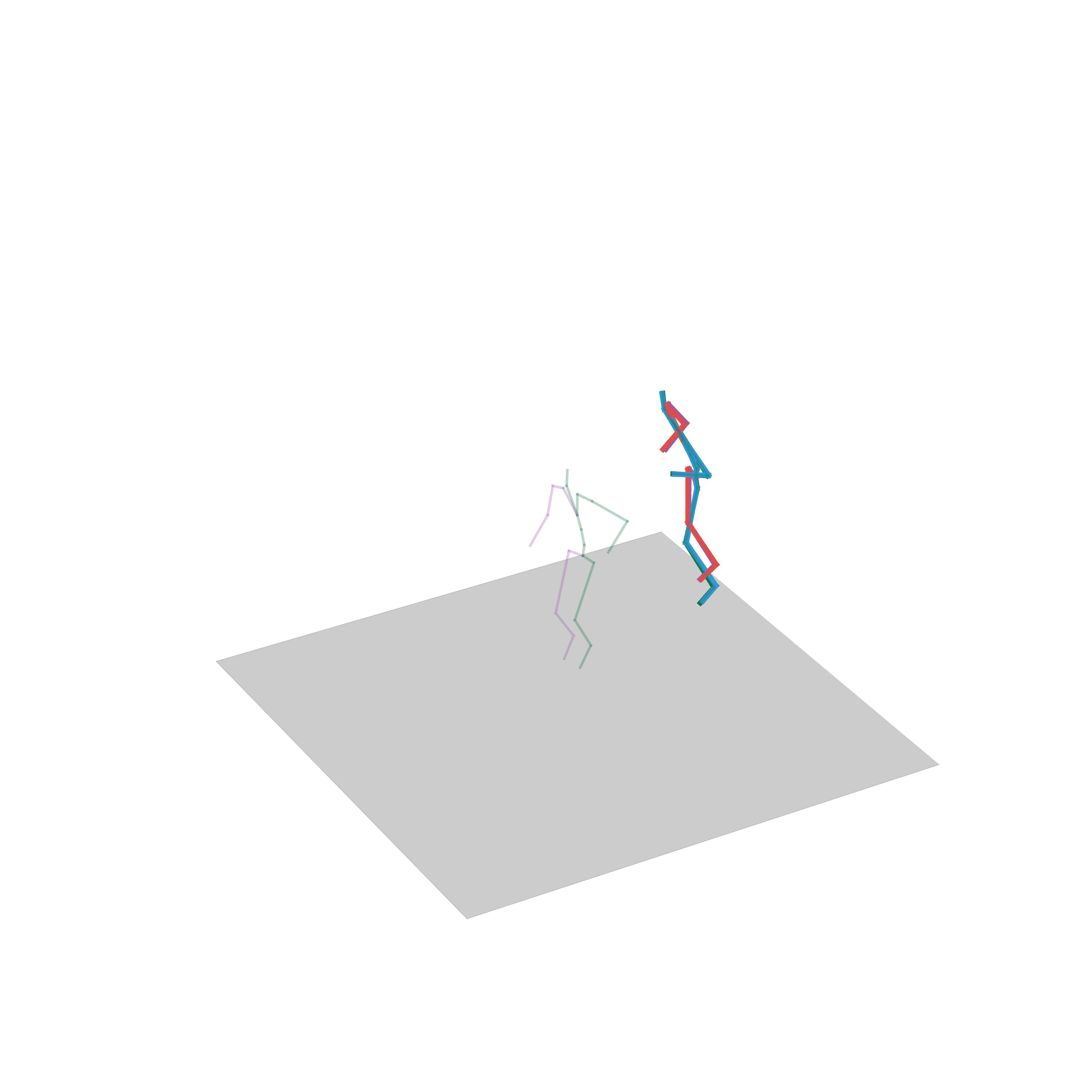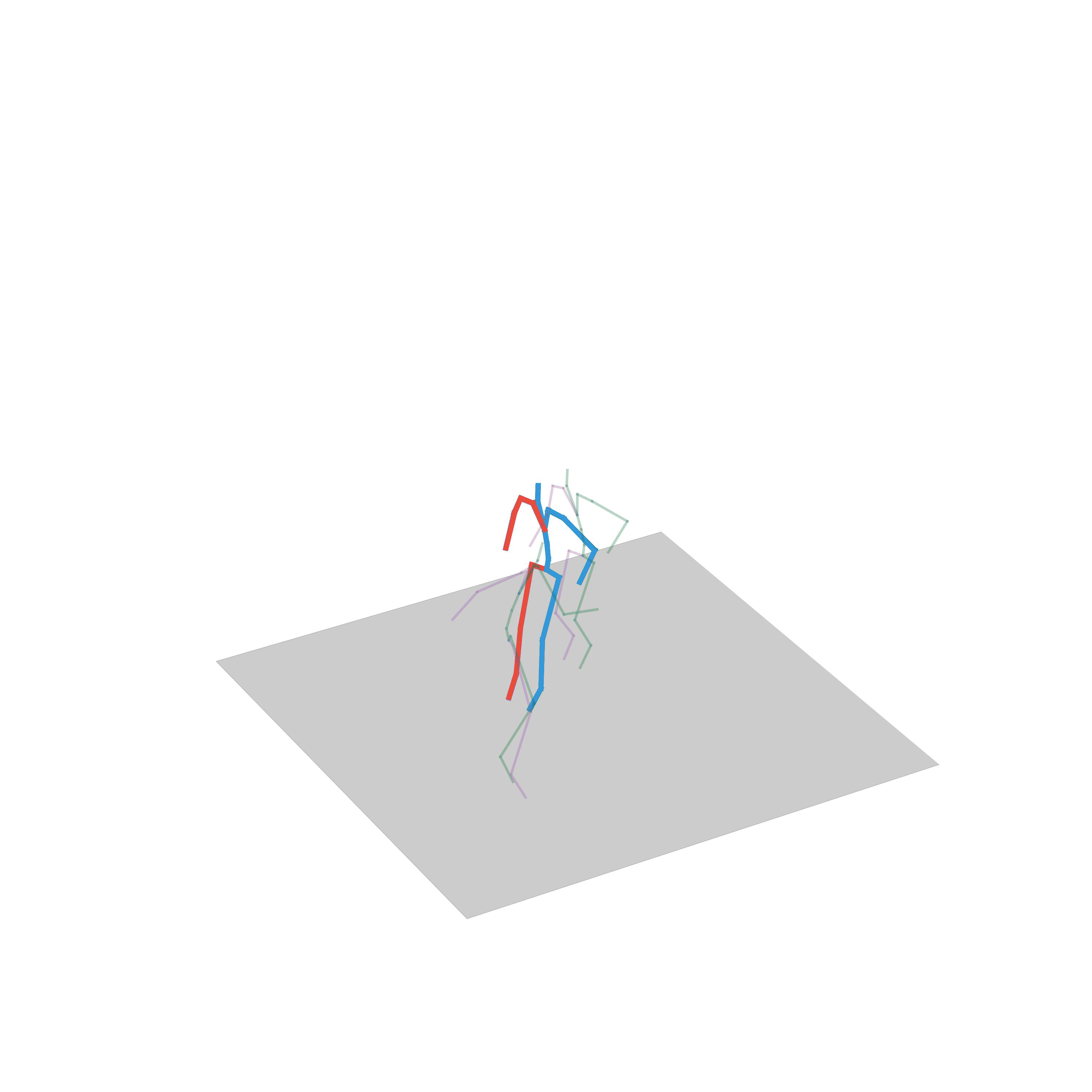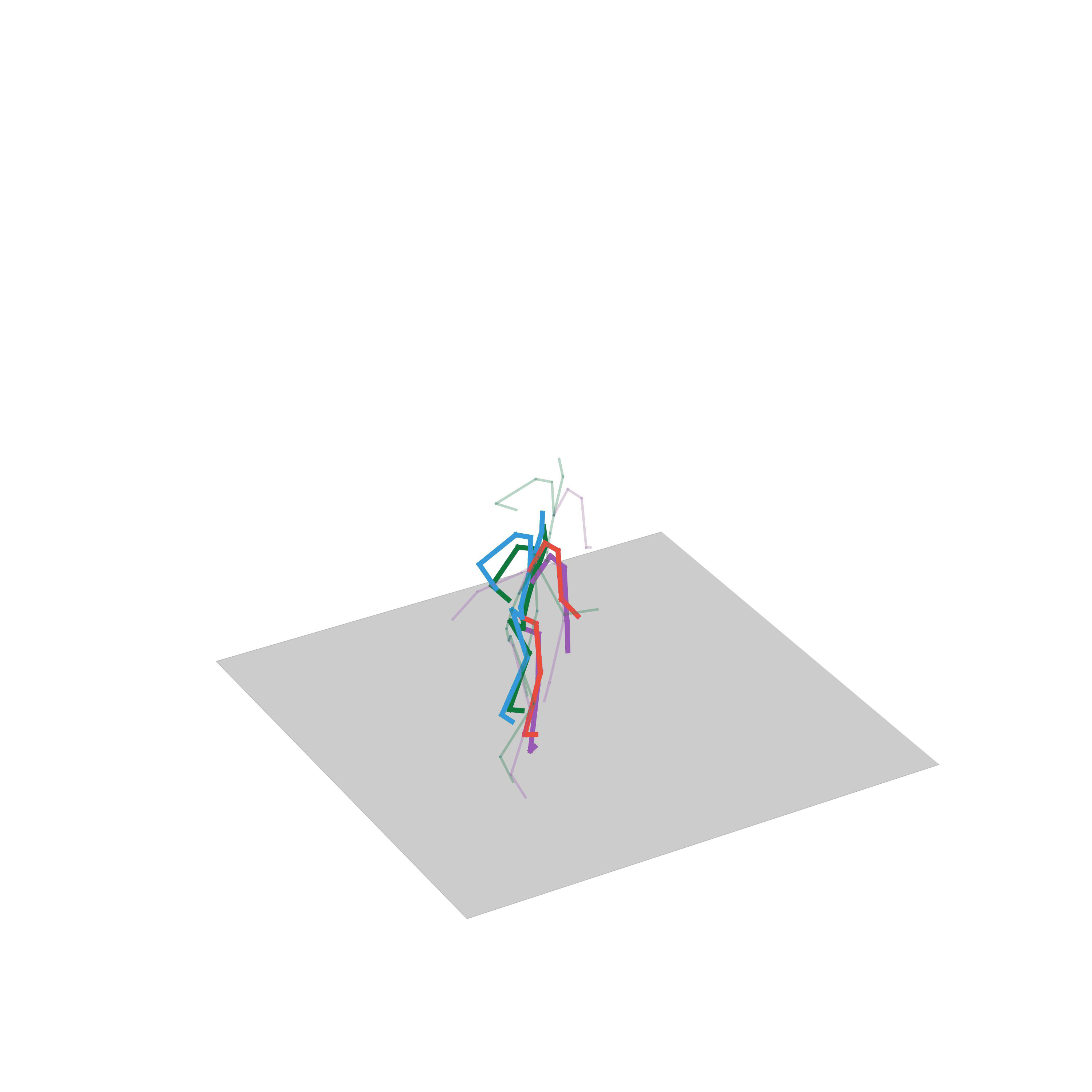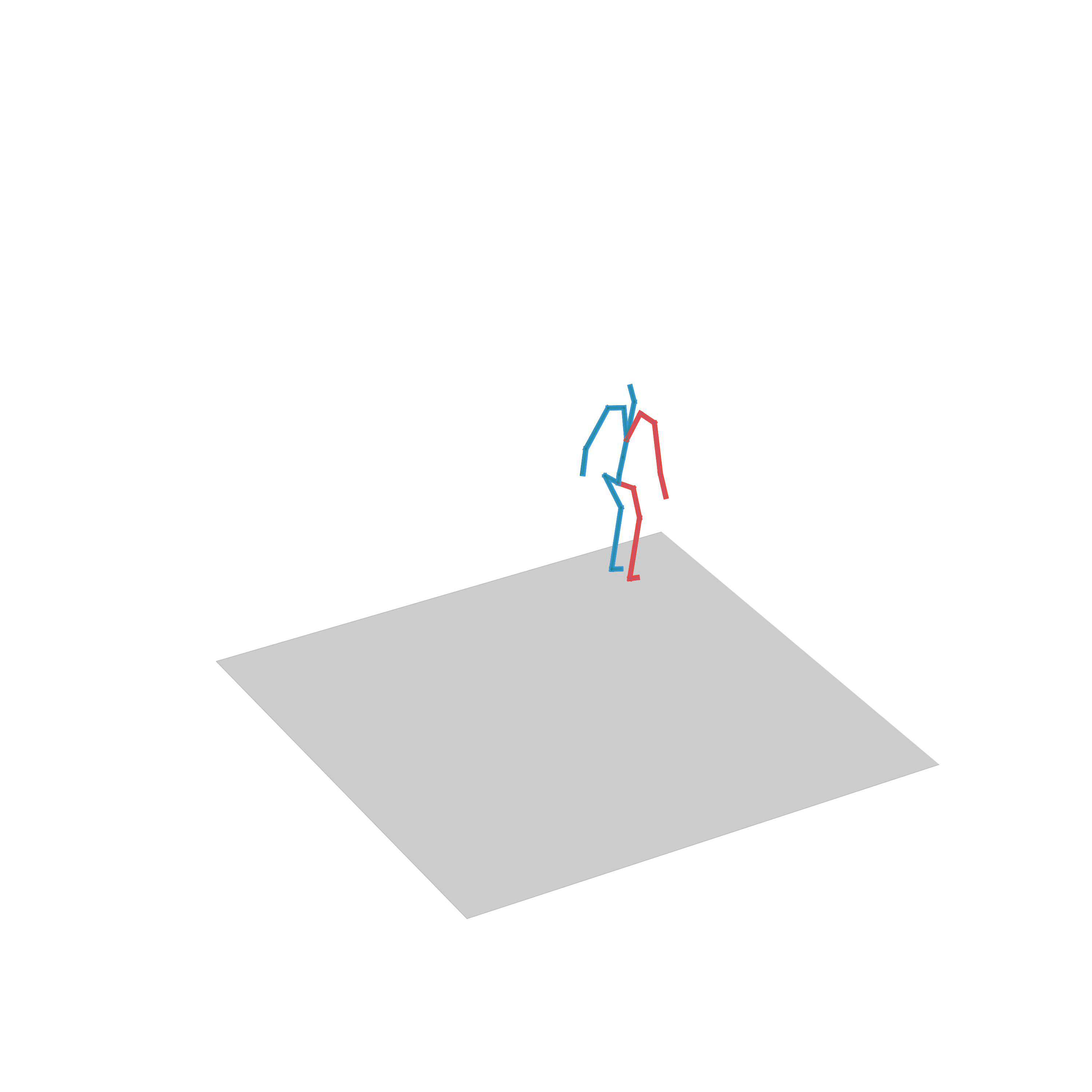
“Walking to crawling”
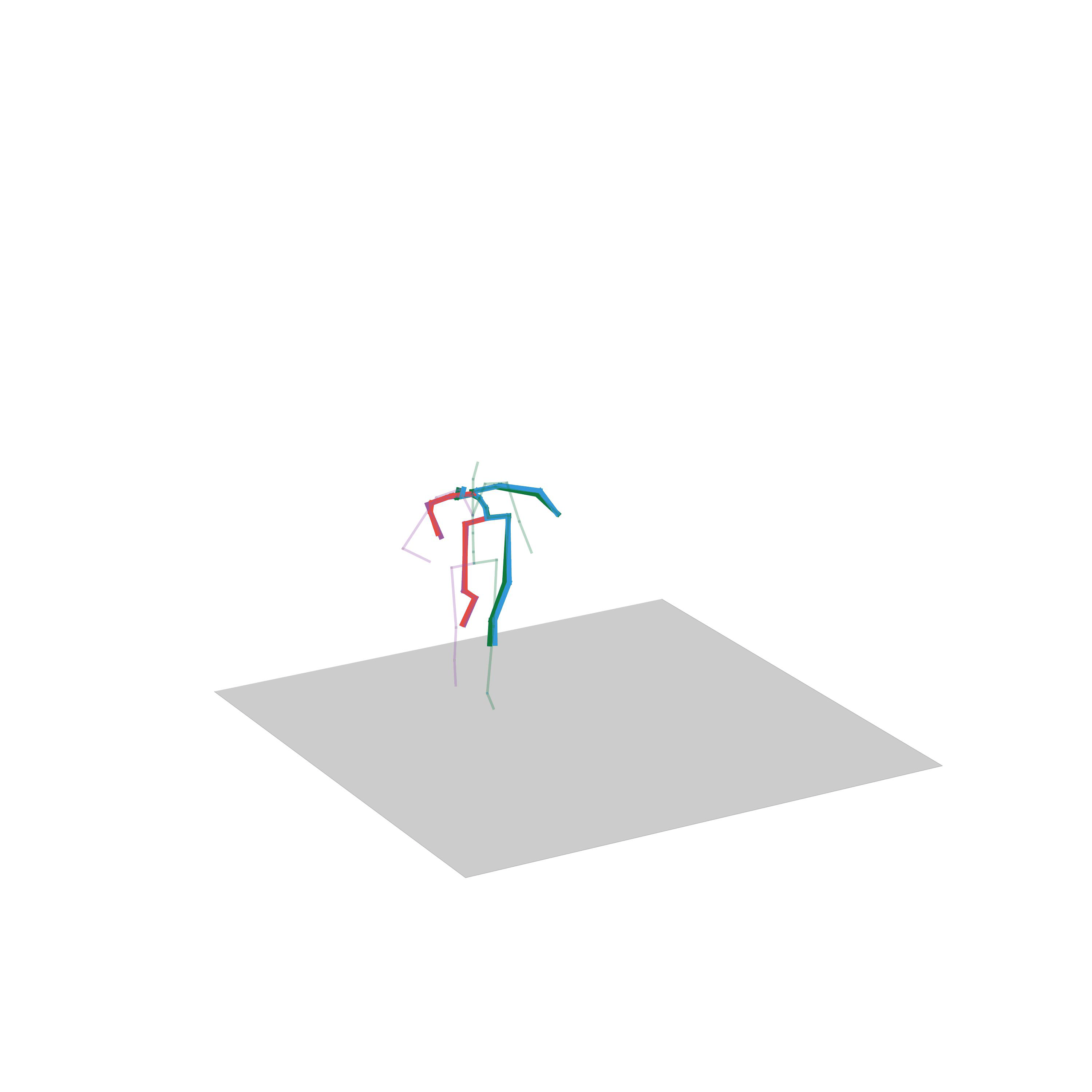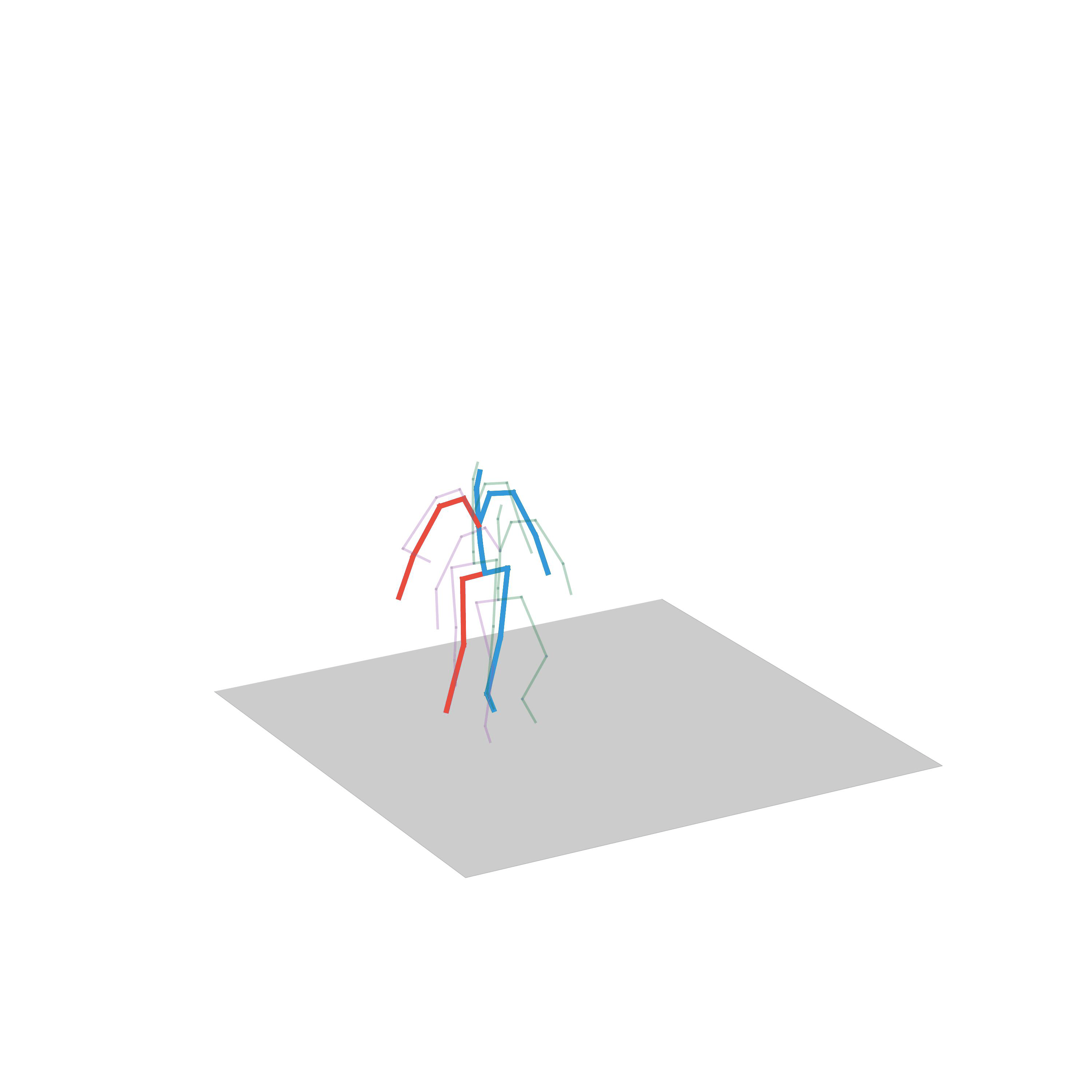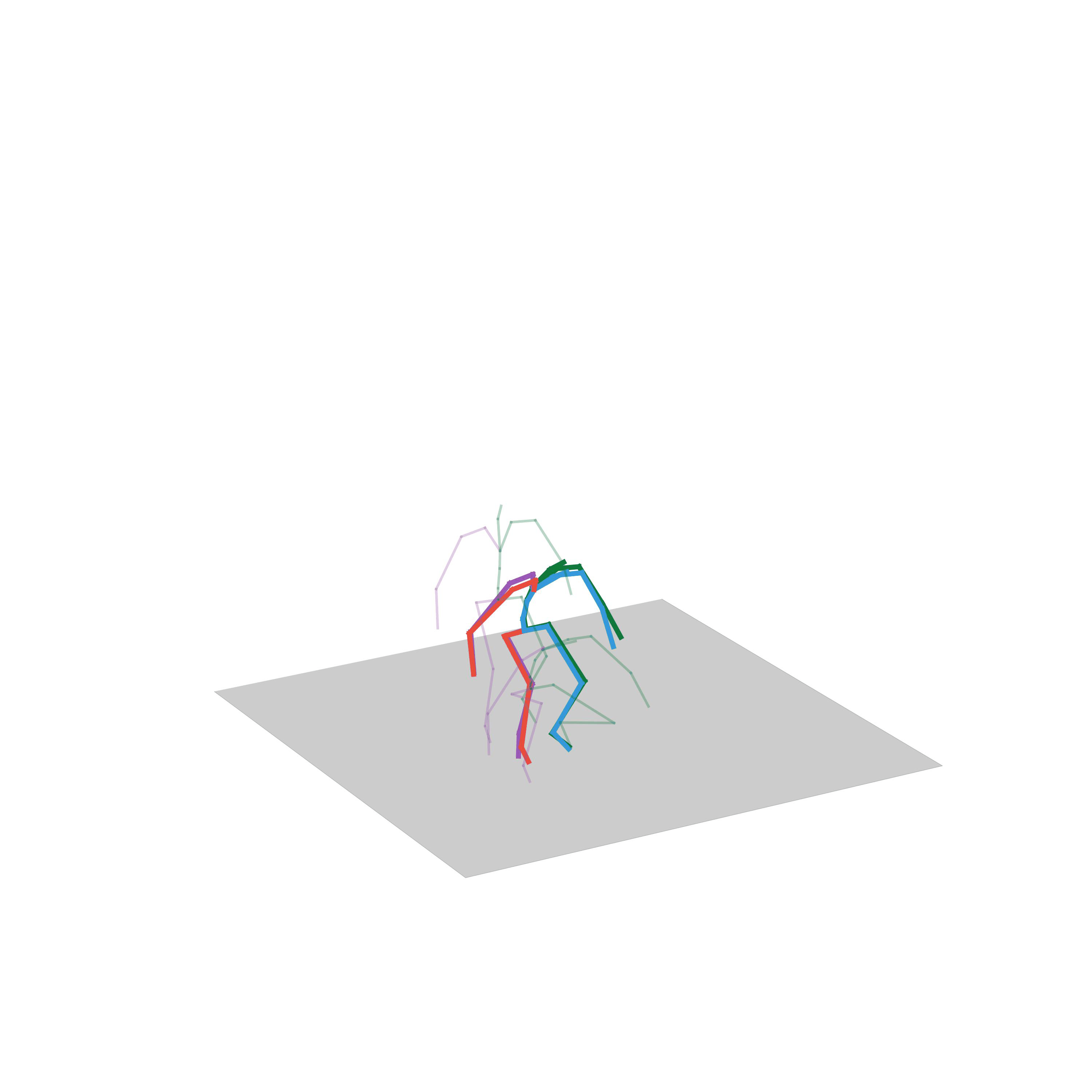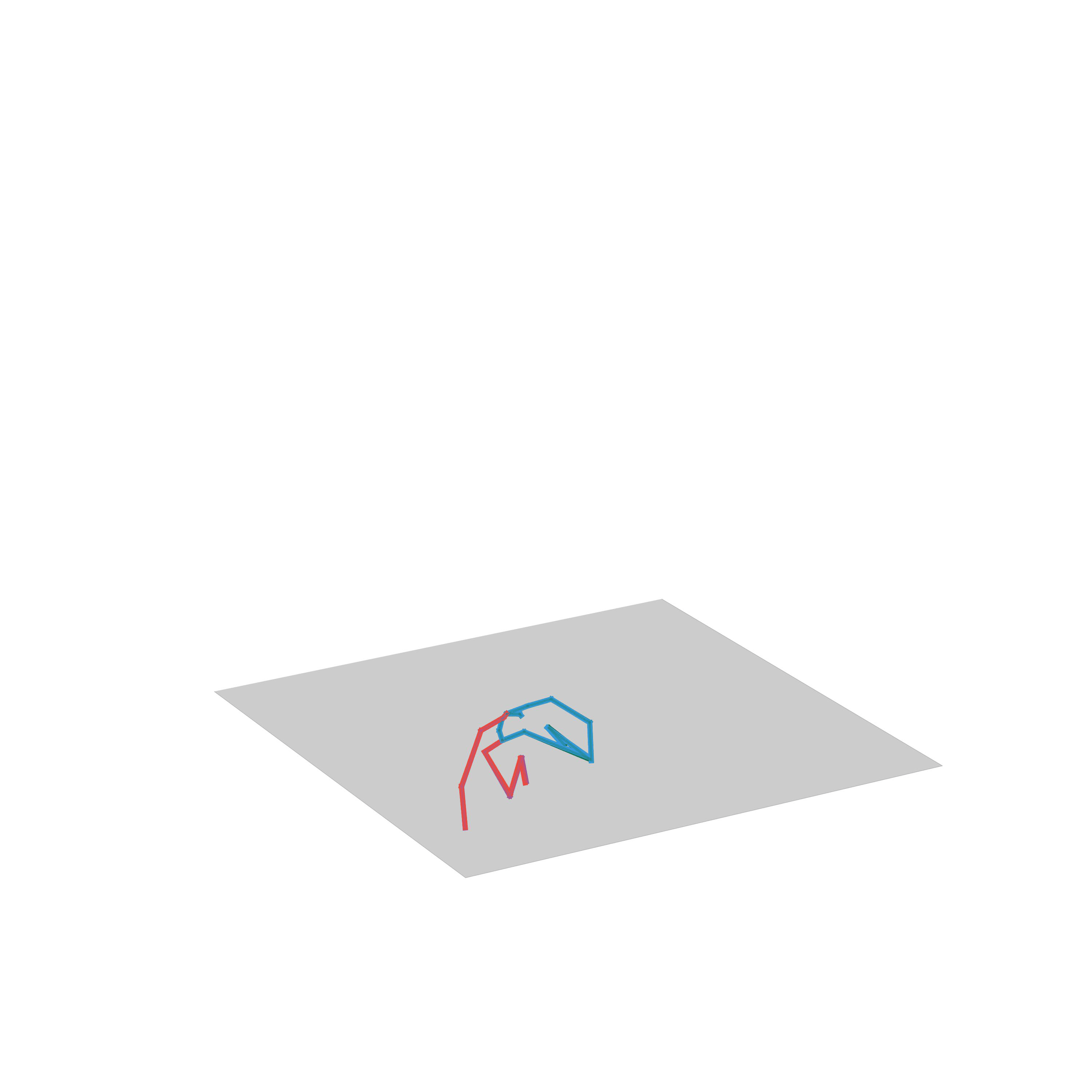
“Fighting”
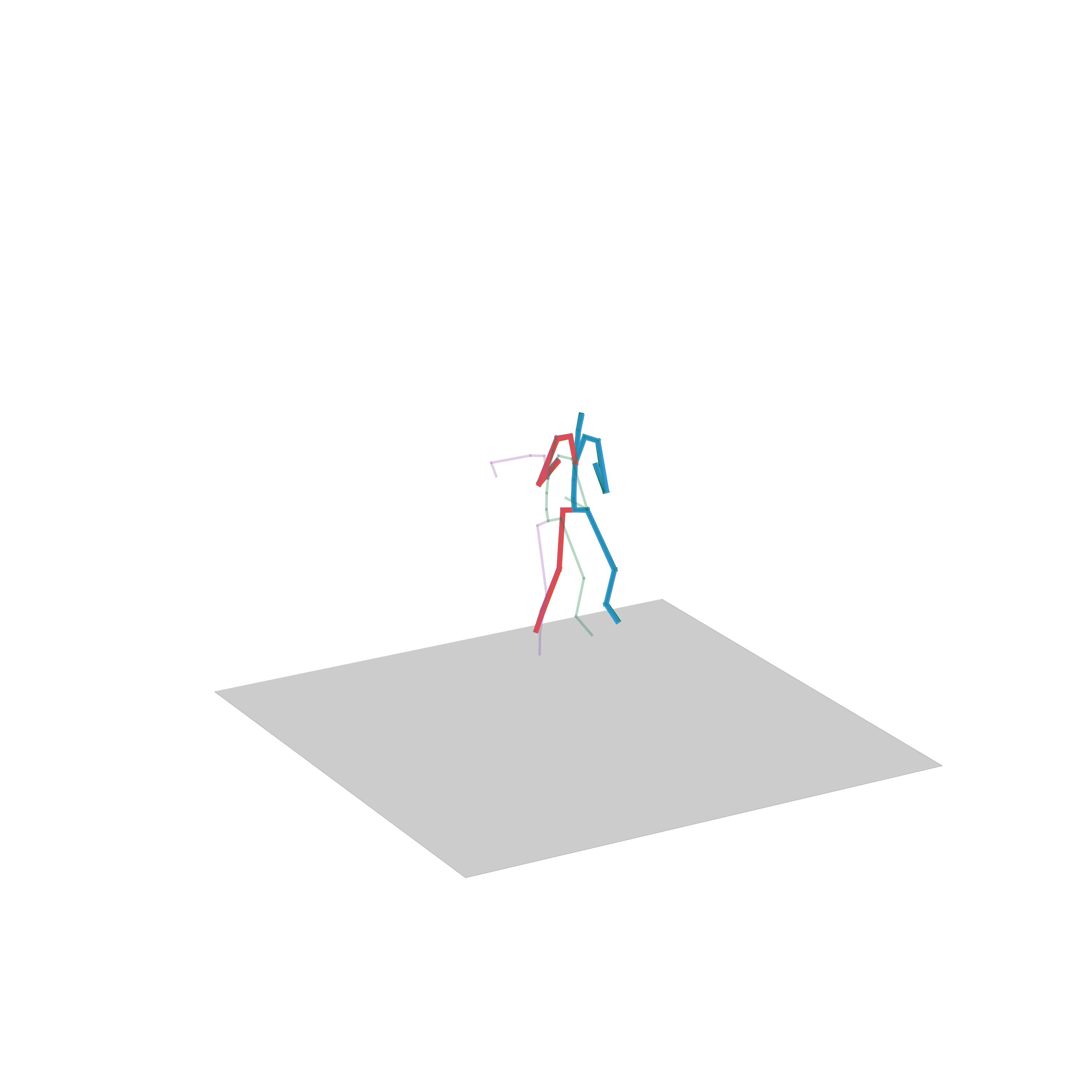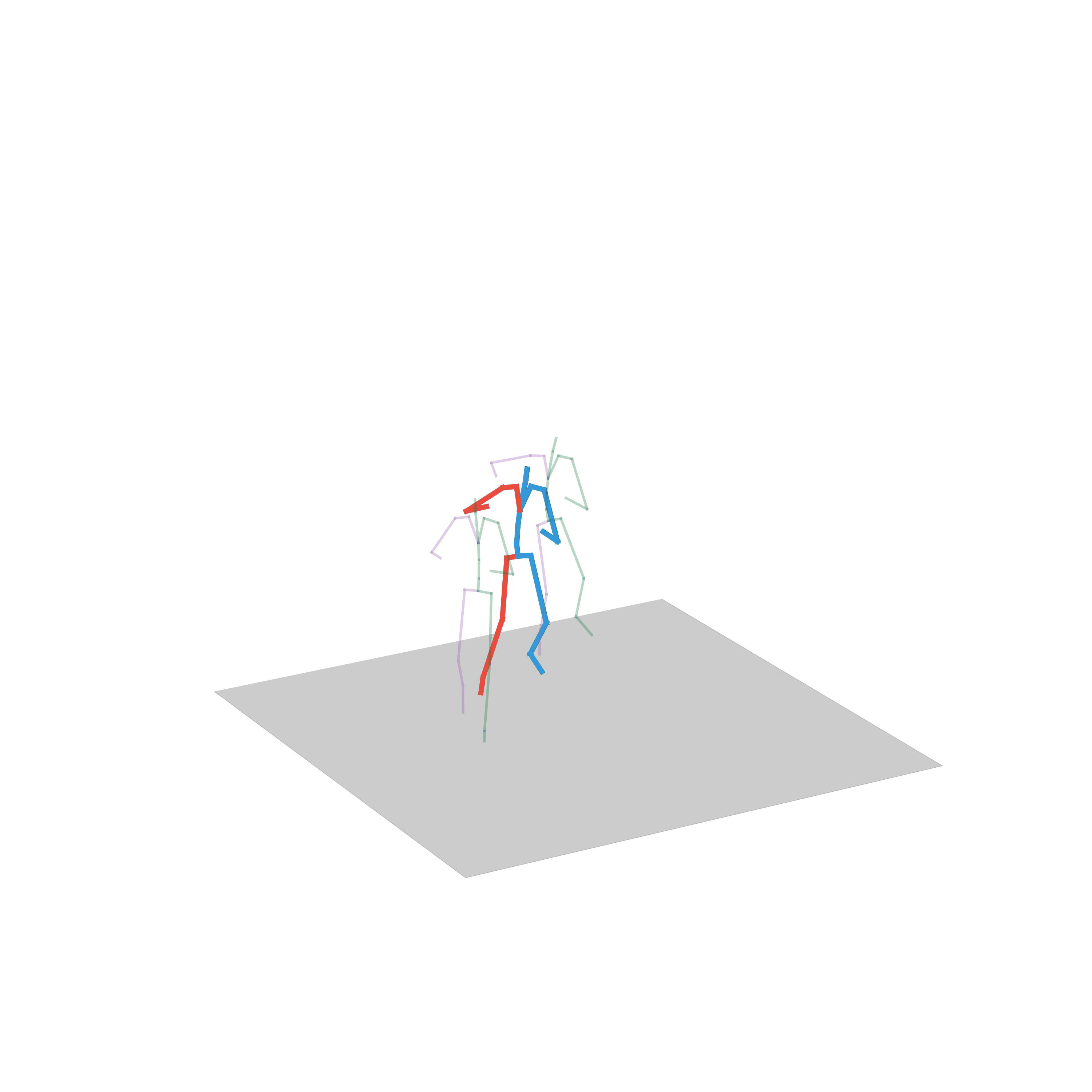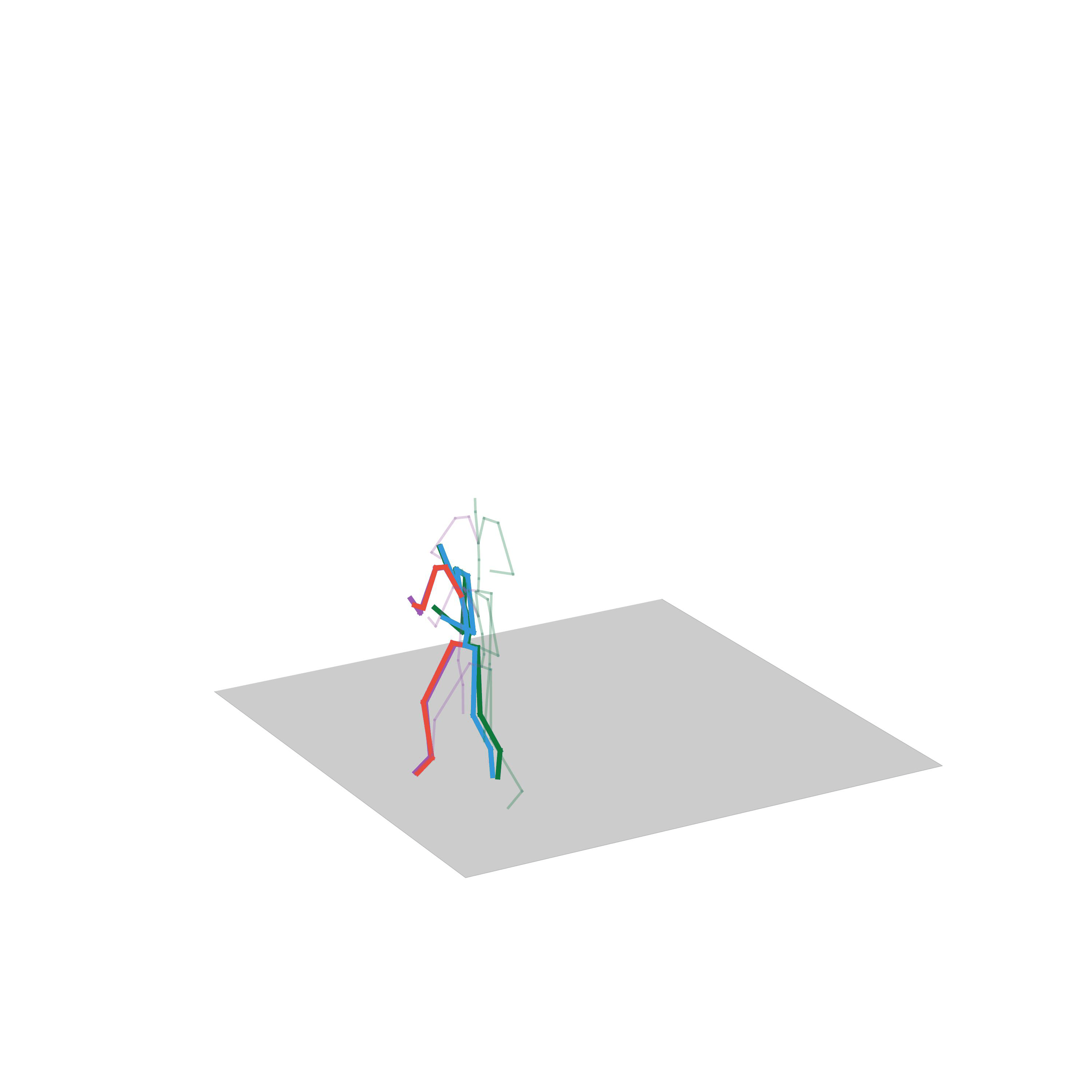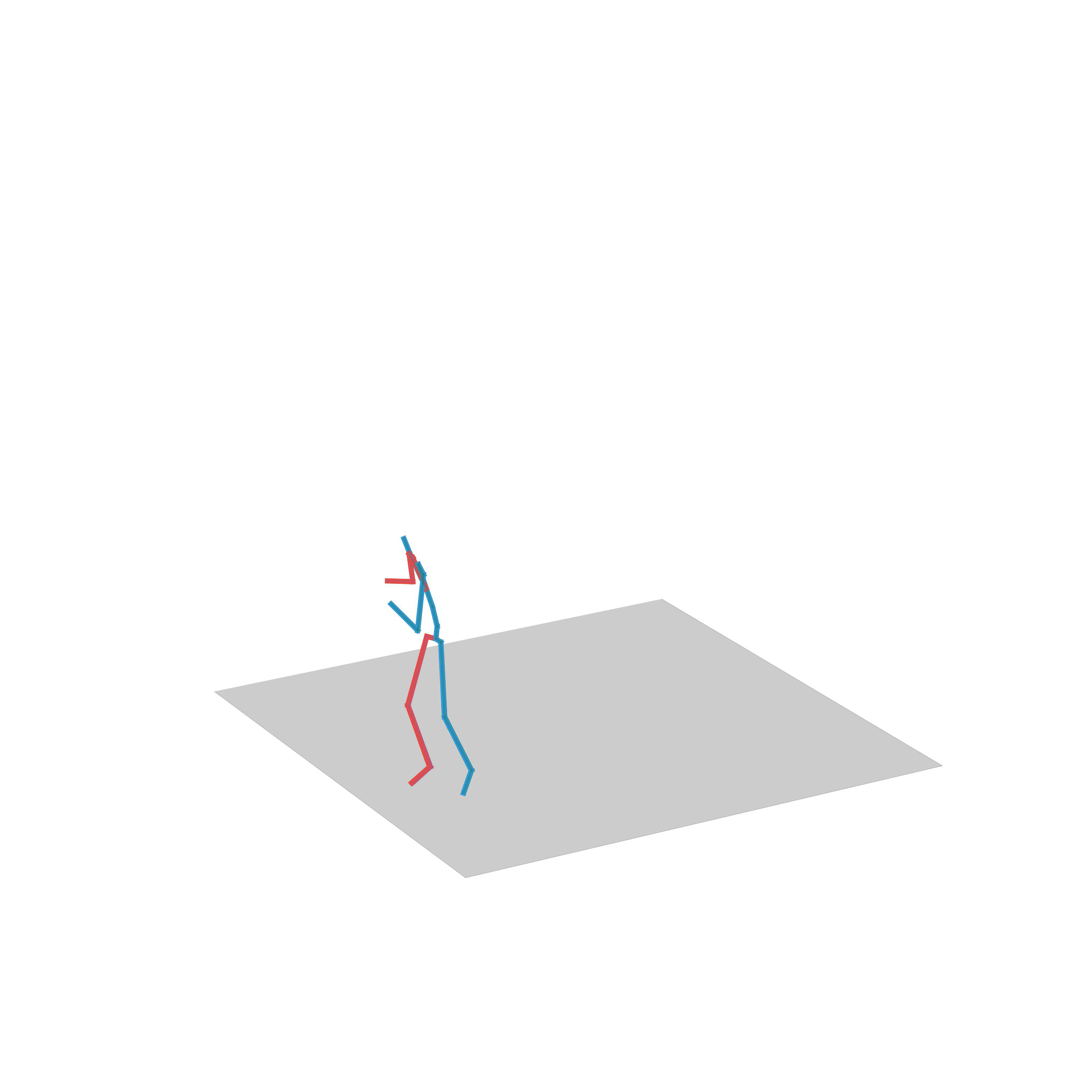
“Avoiding obstacles and fighting”
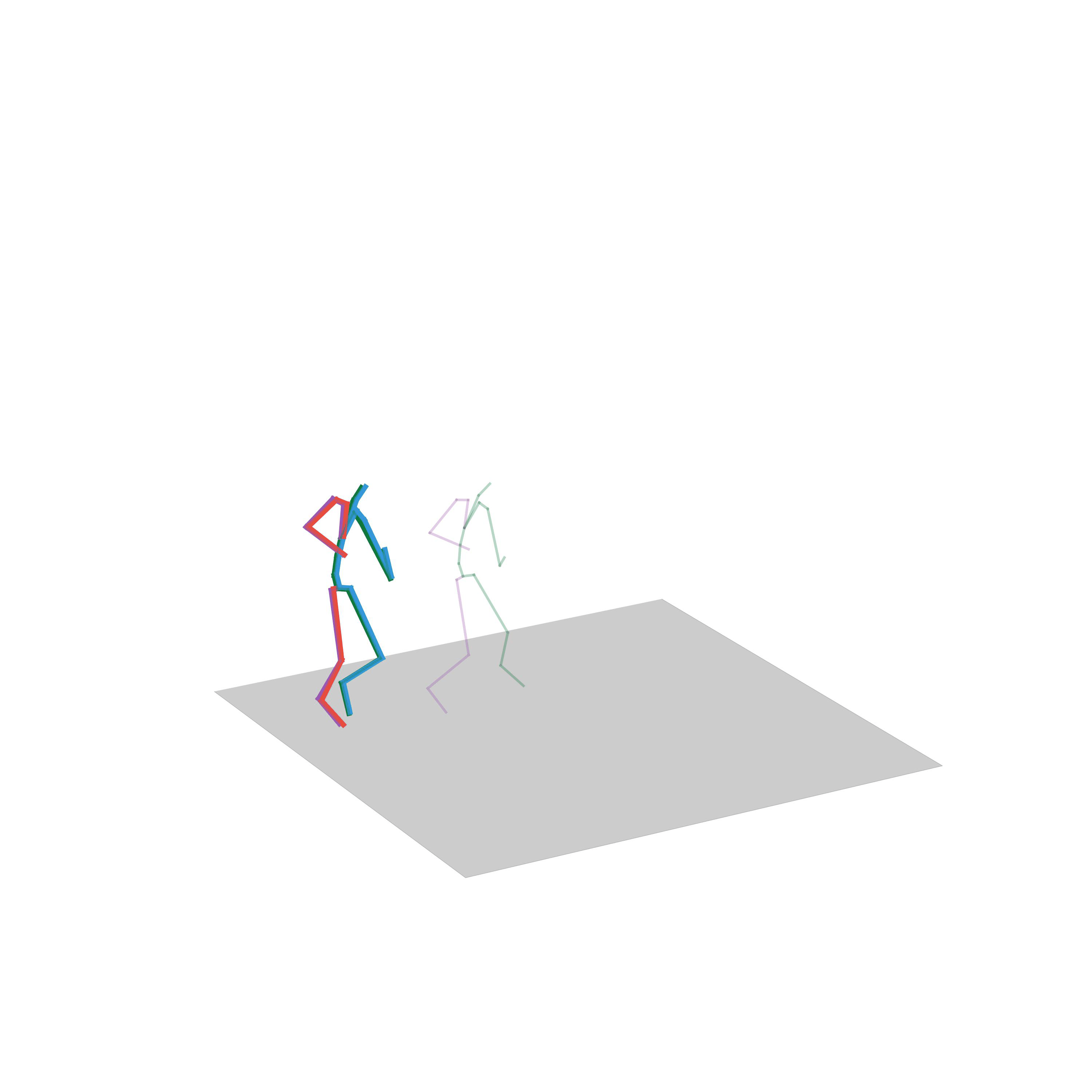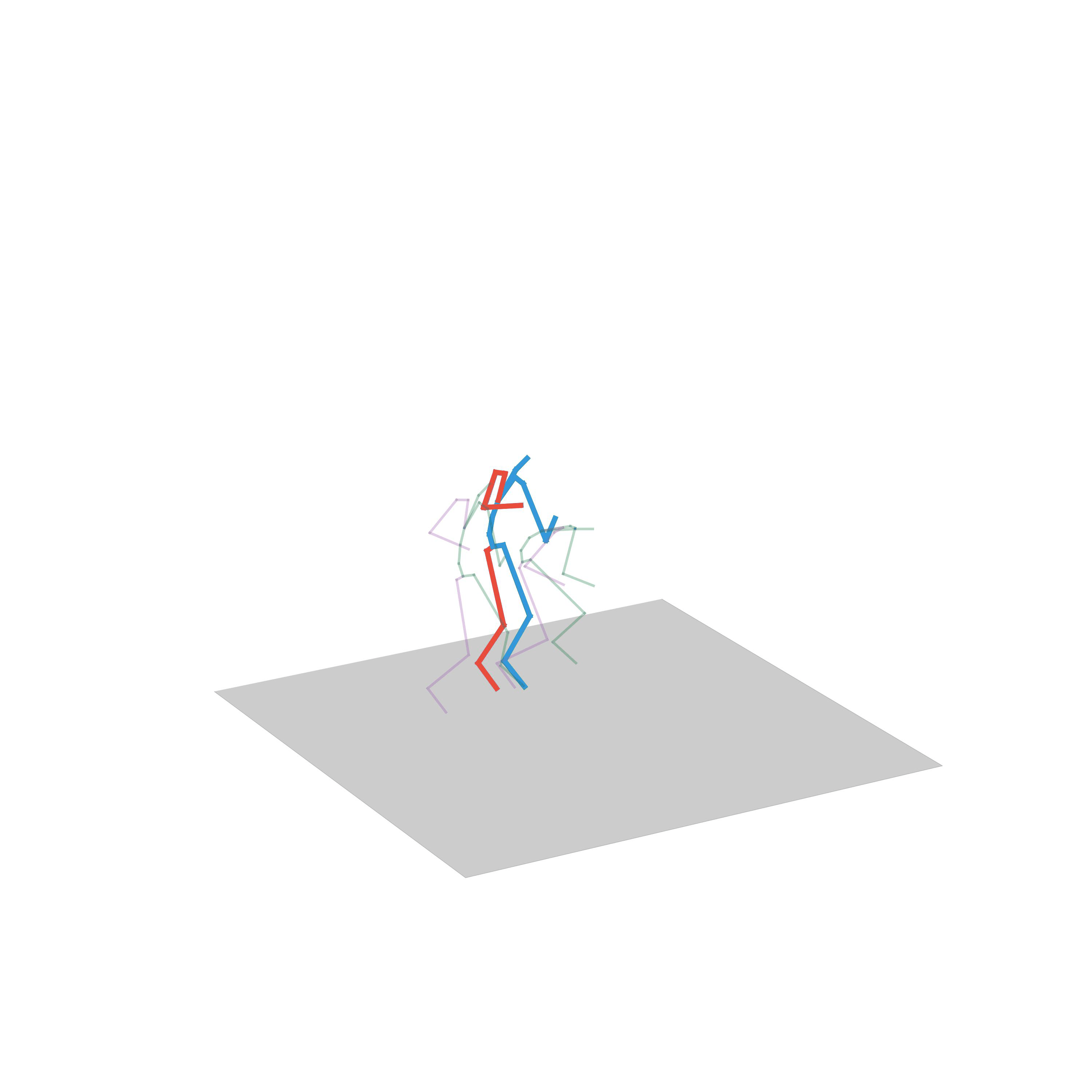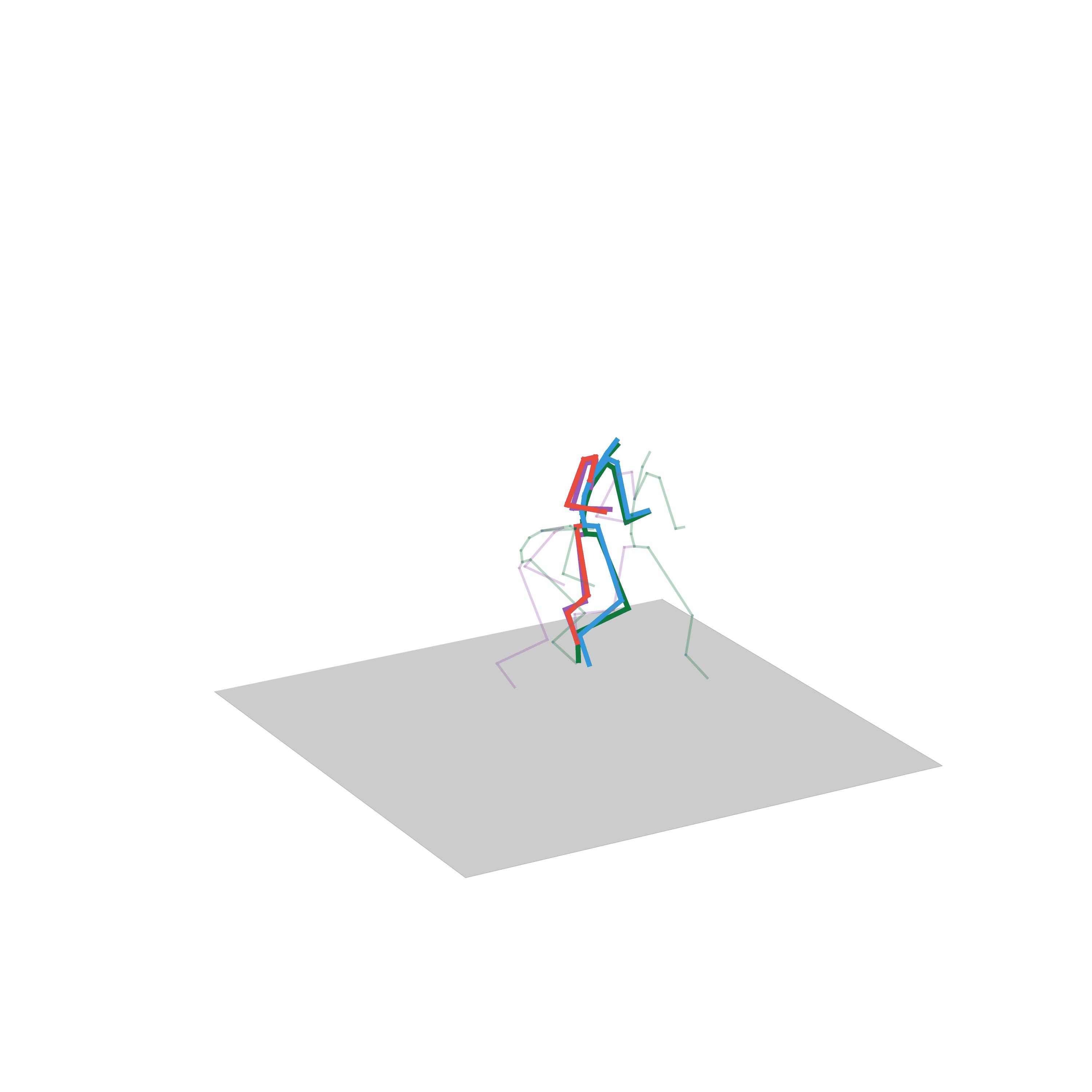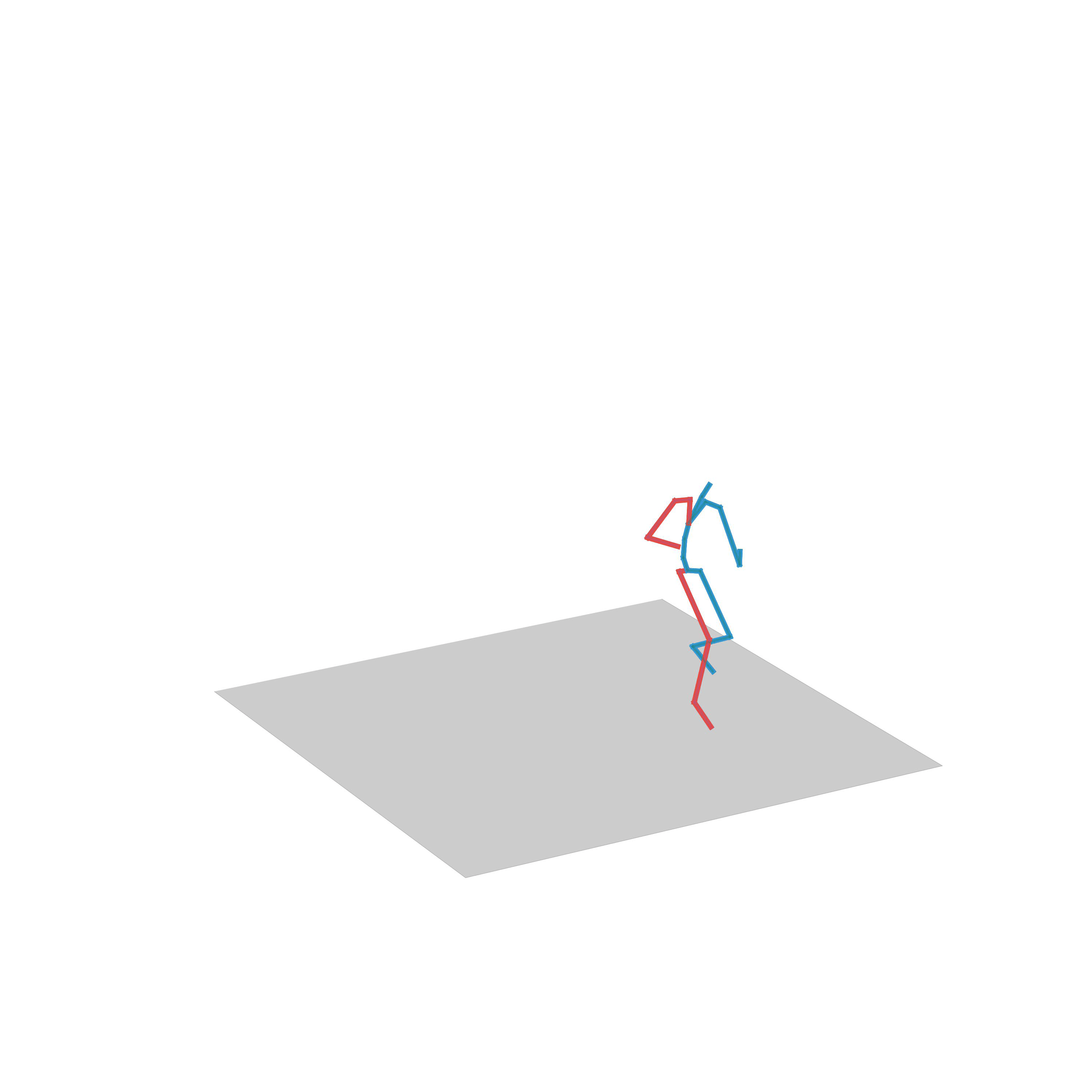
“Walking and stepping up the stairs”
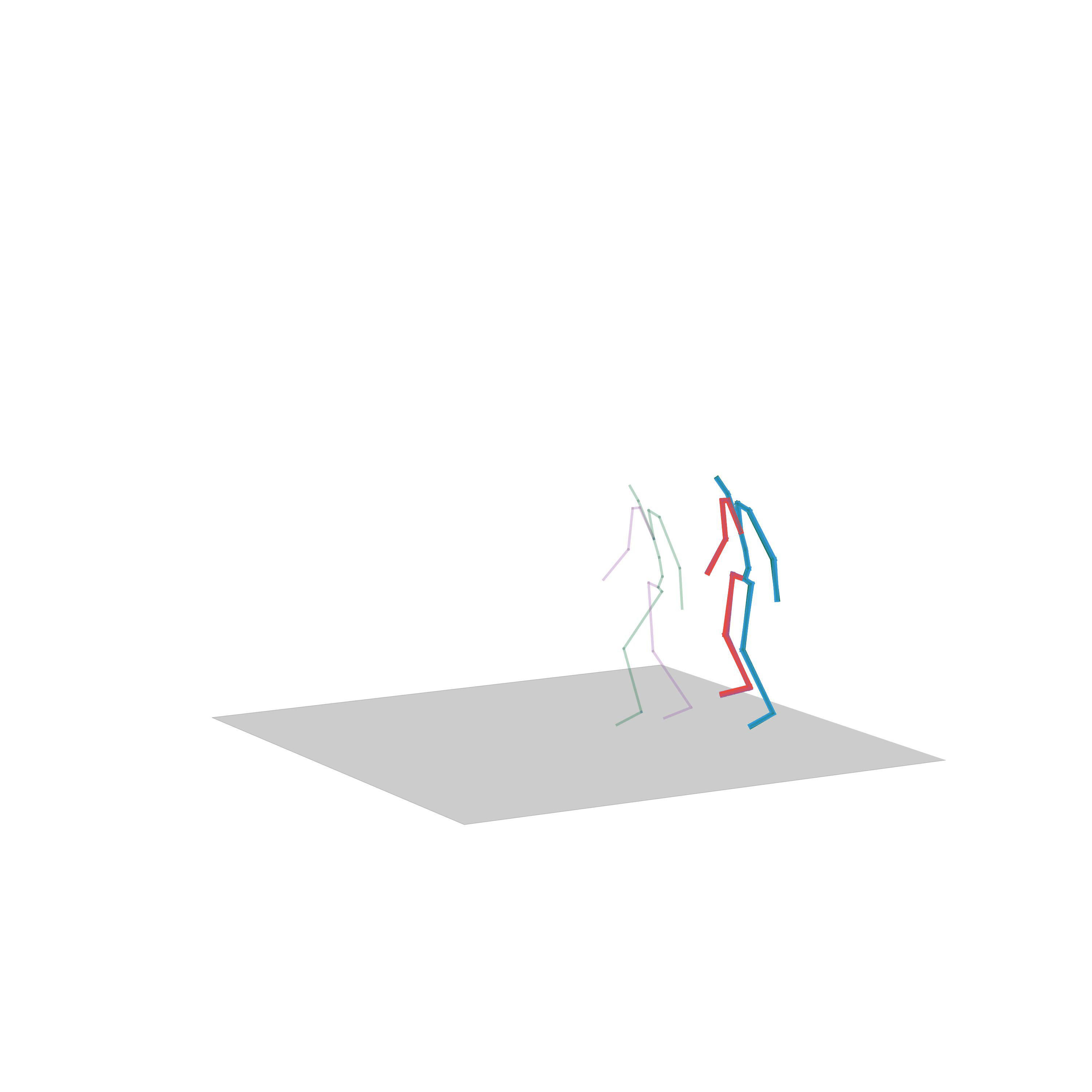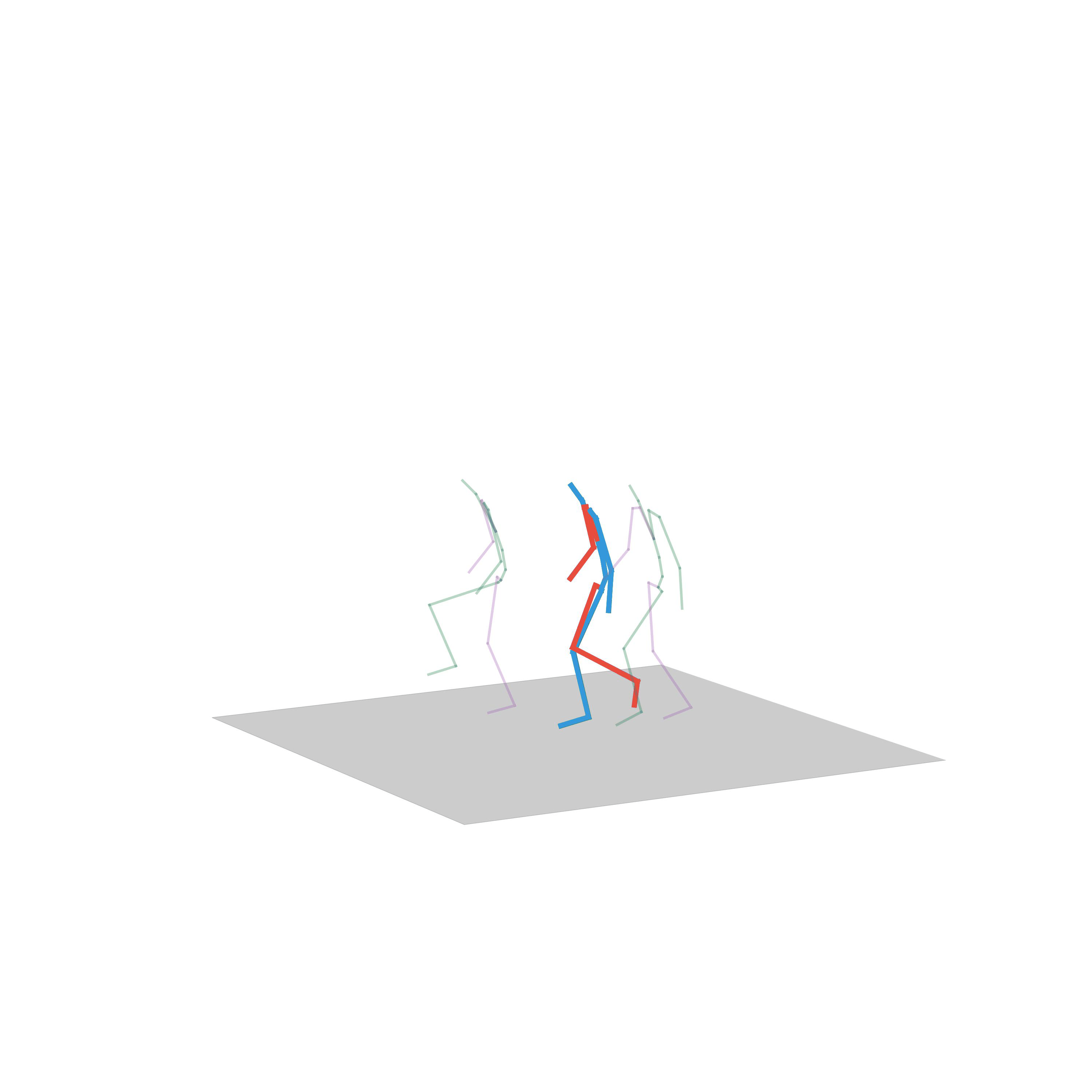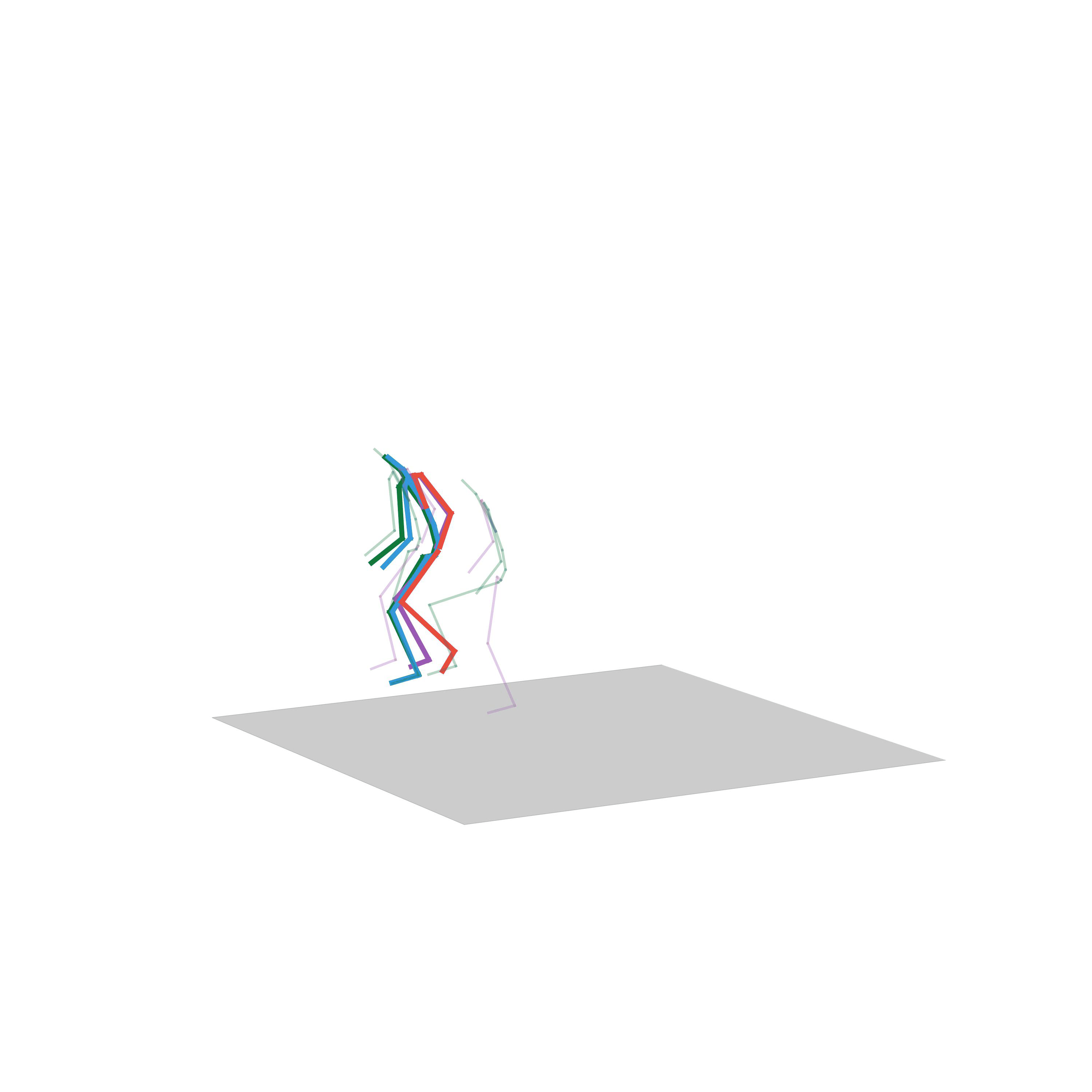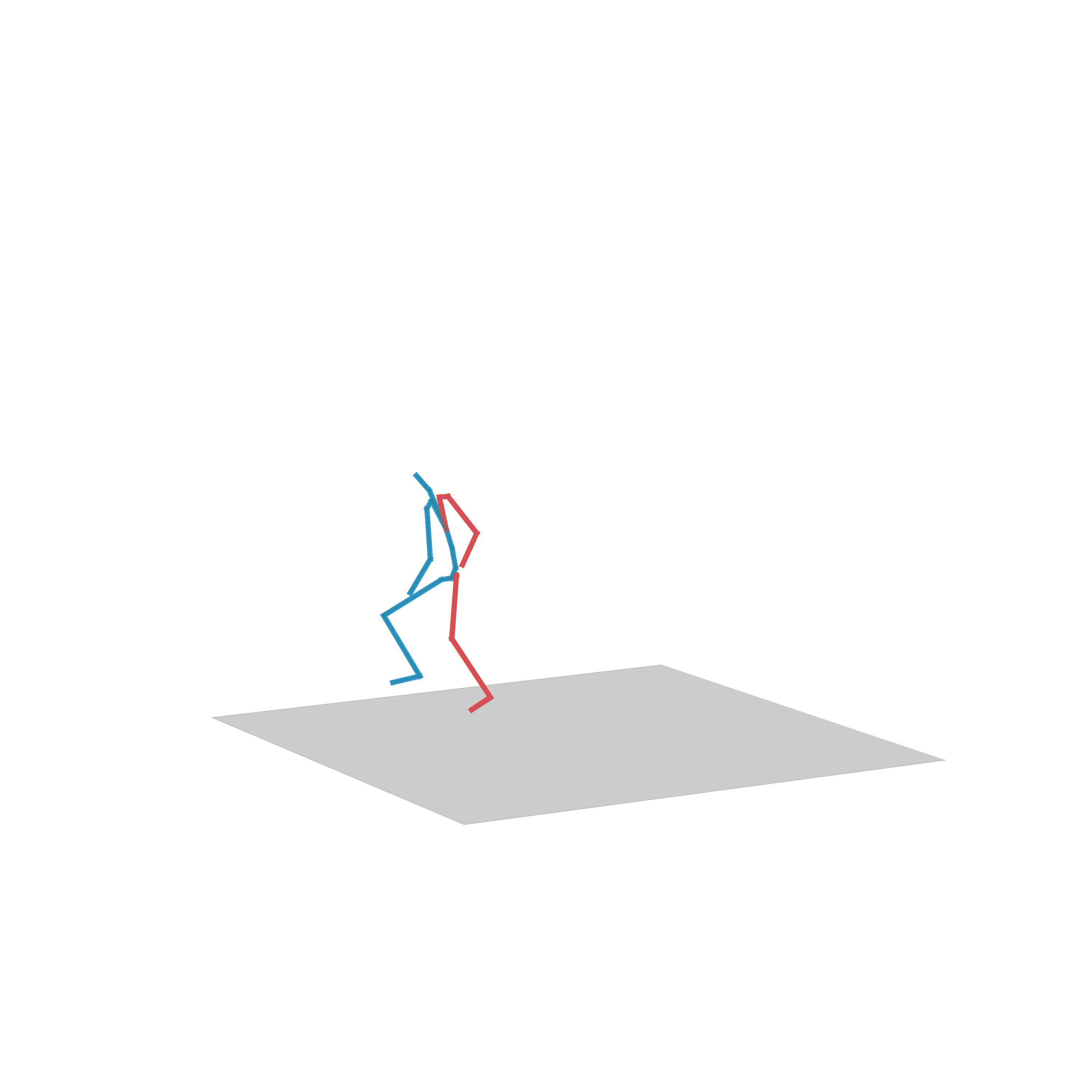
“Crouching”
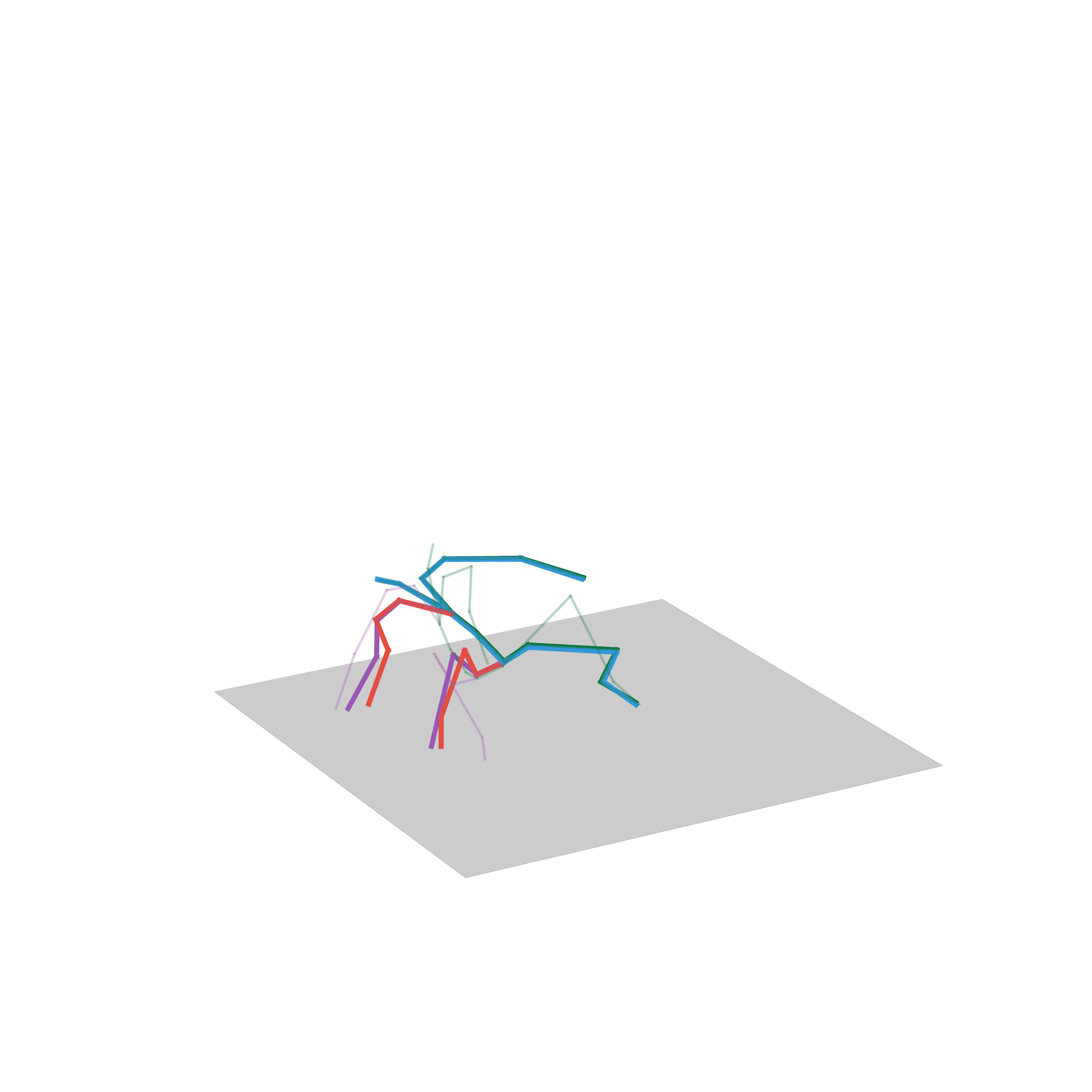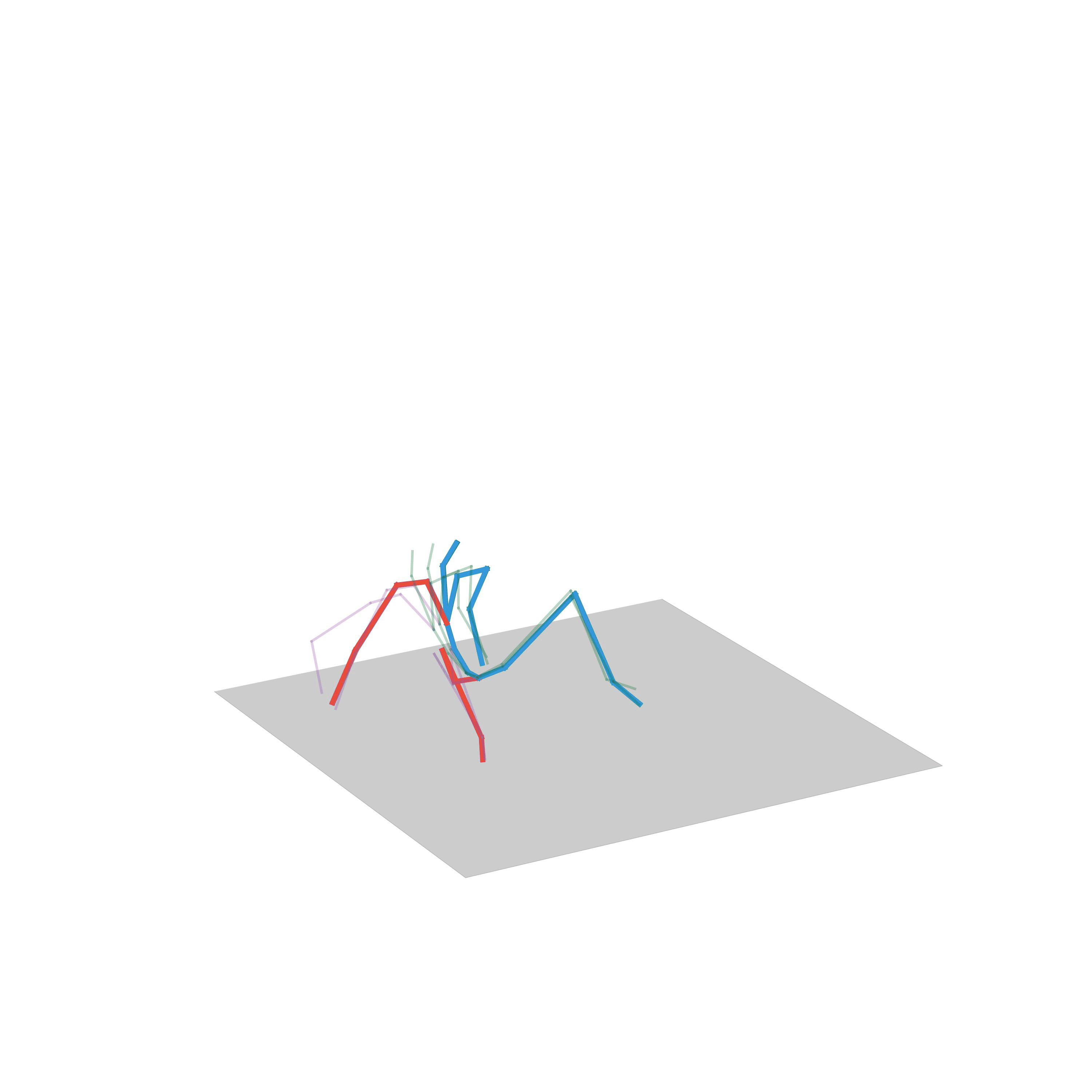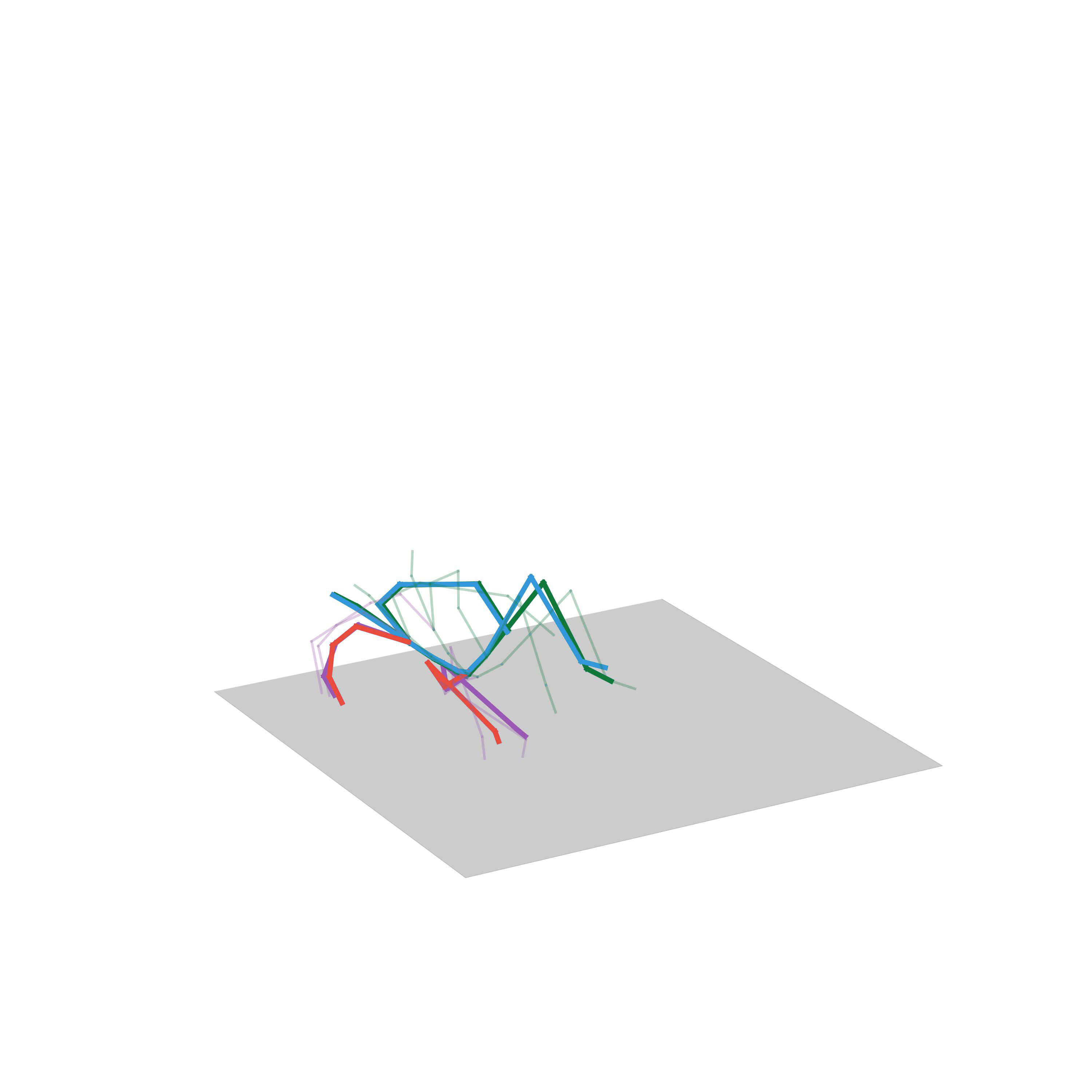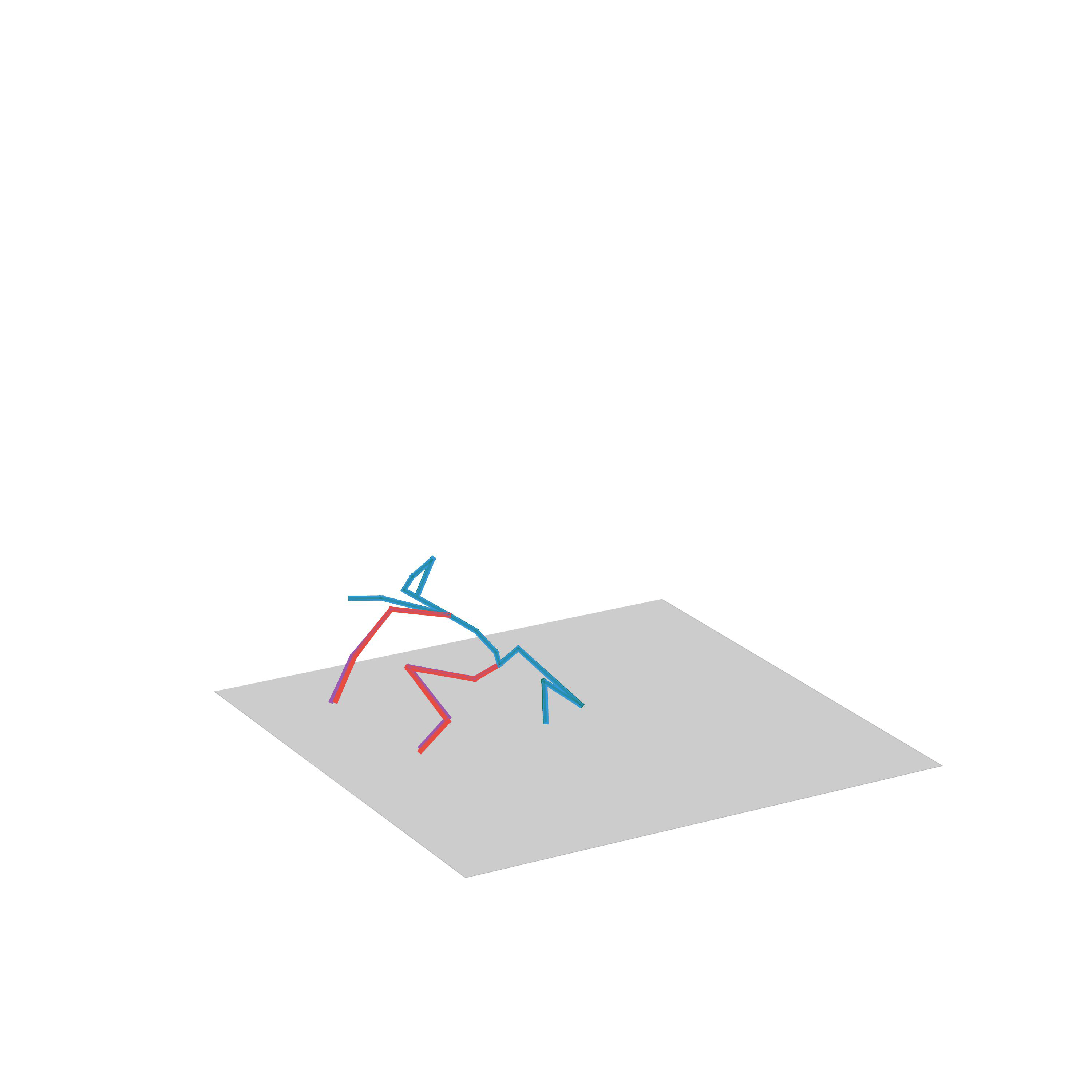
“Fighting”
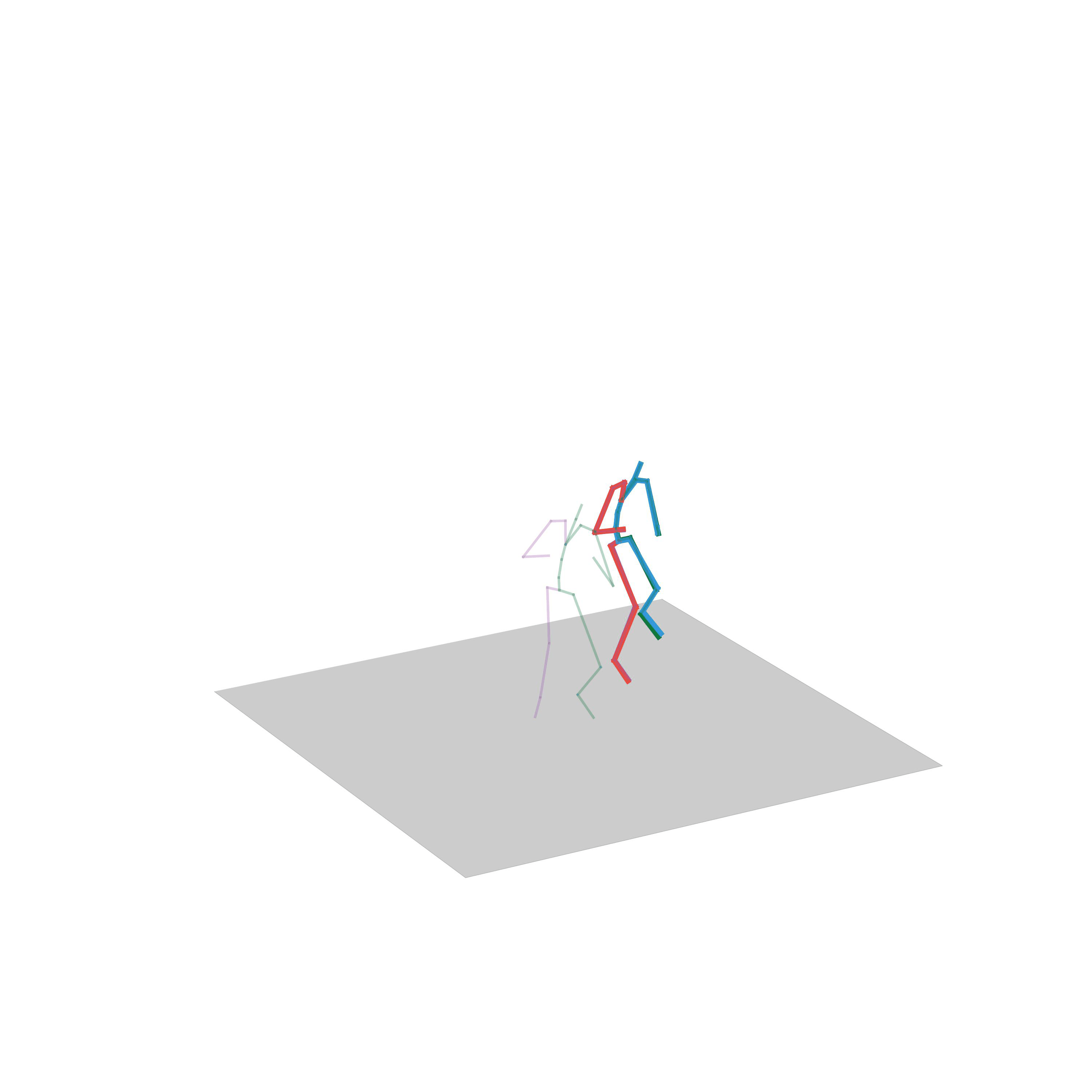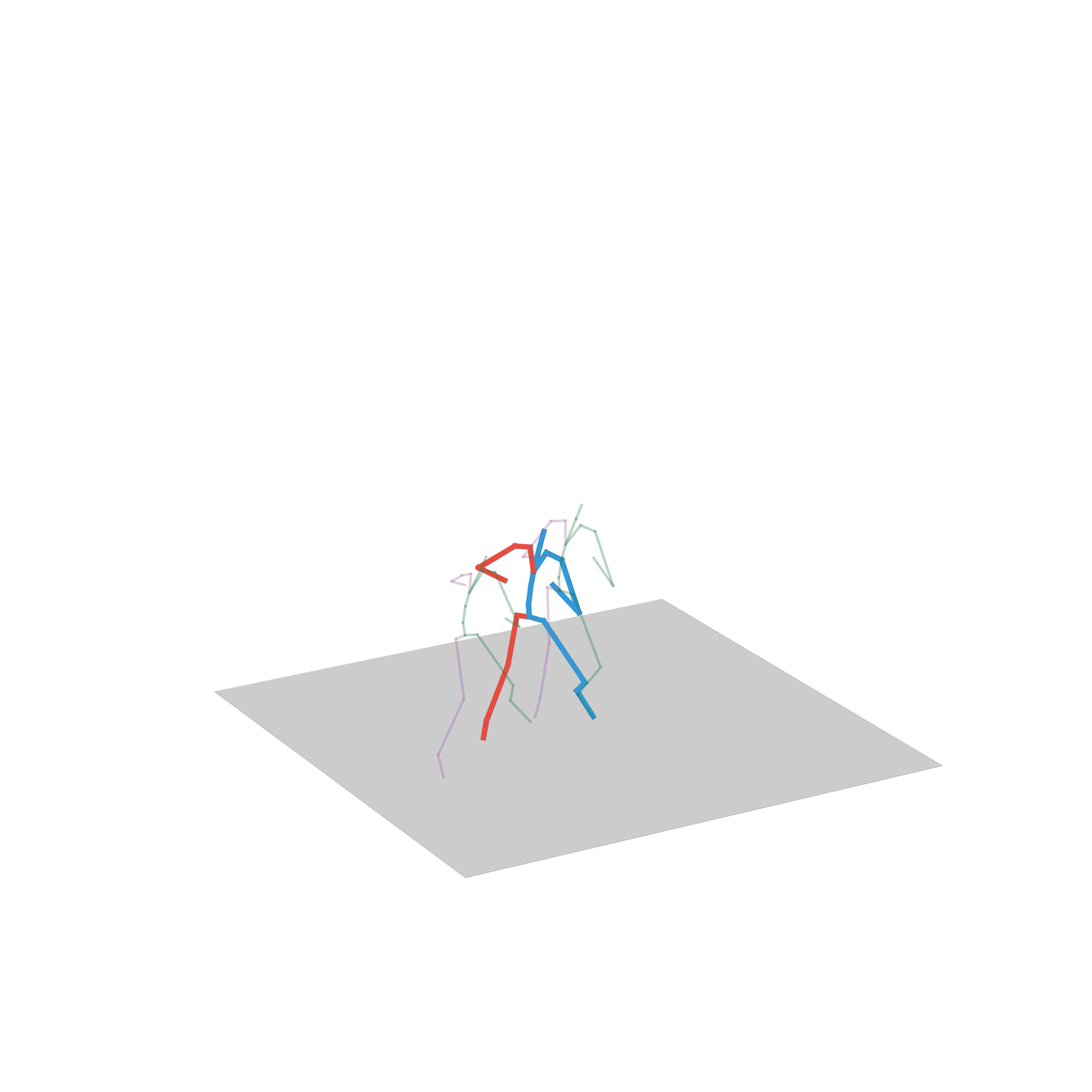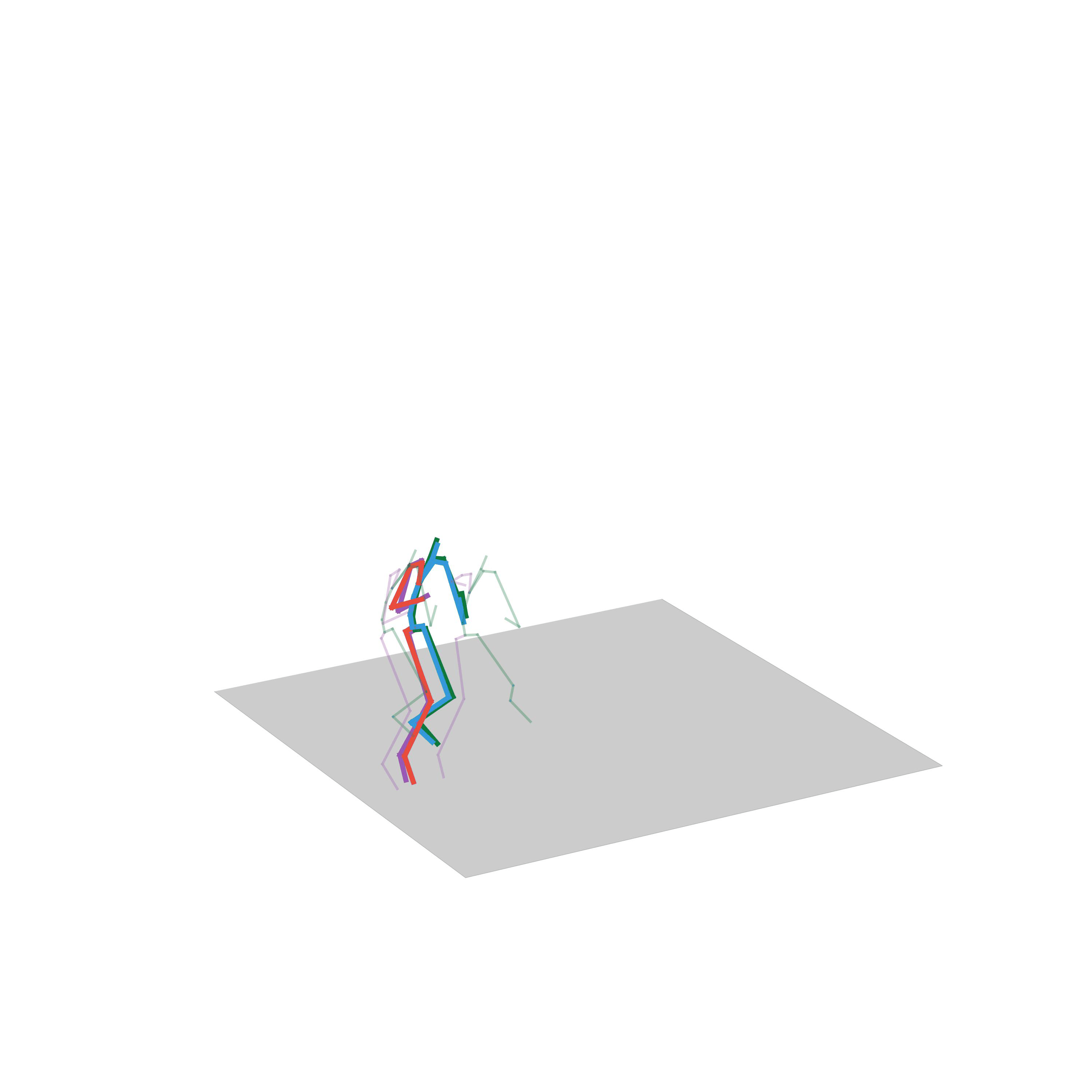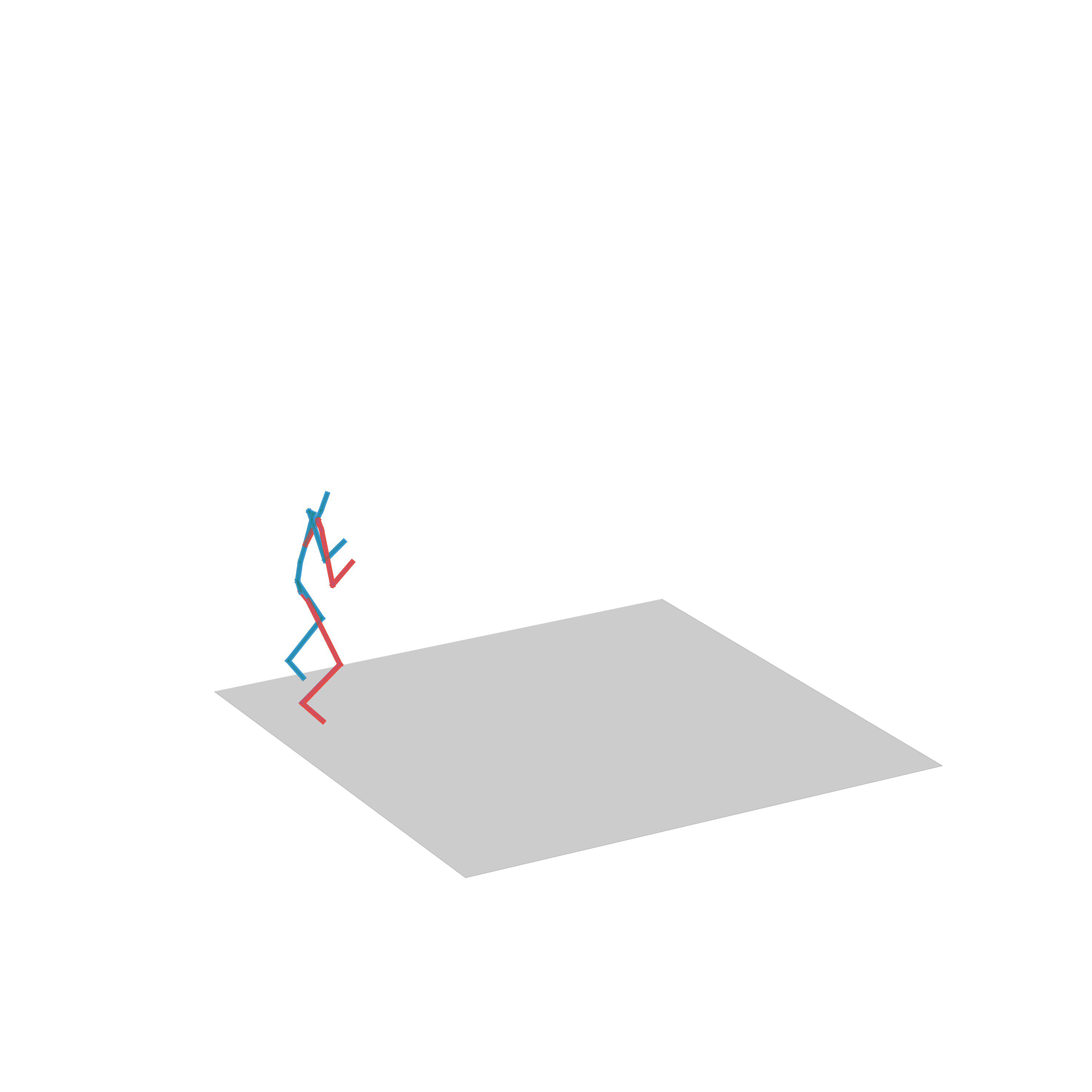
“Walking and turning”
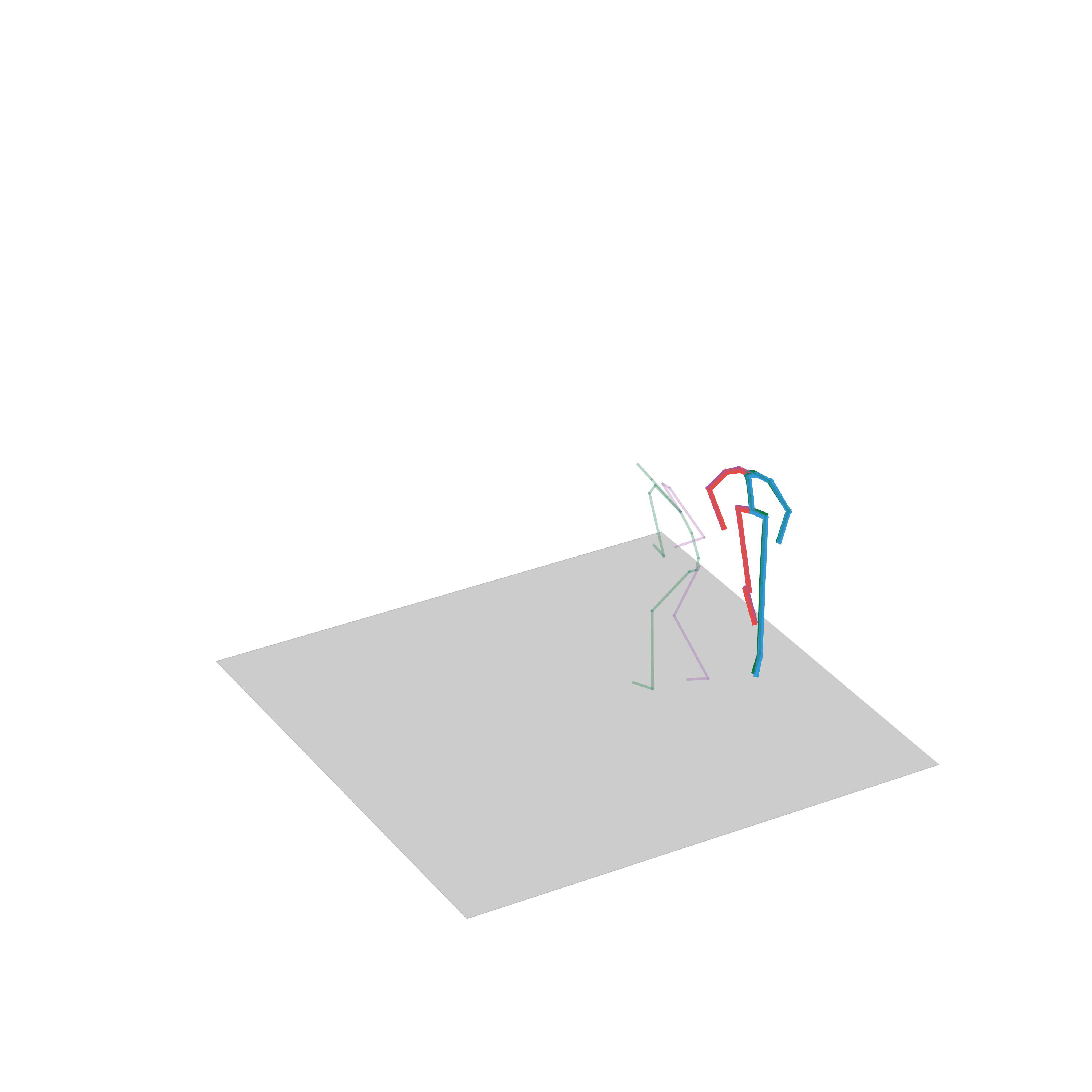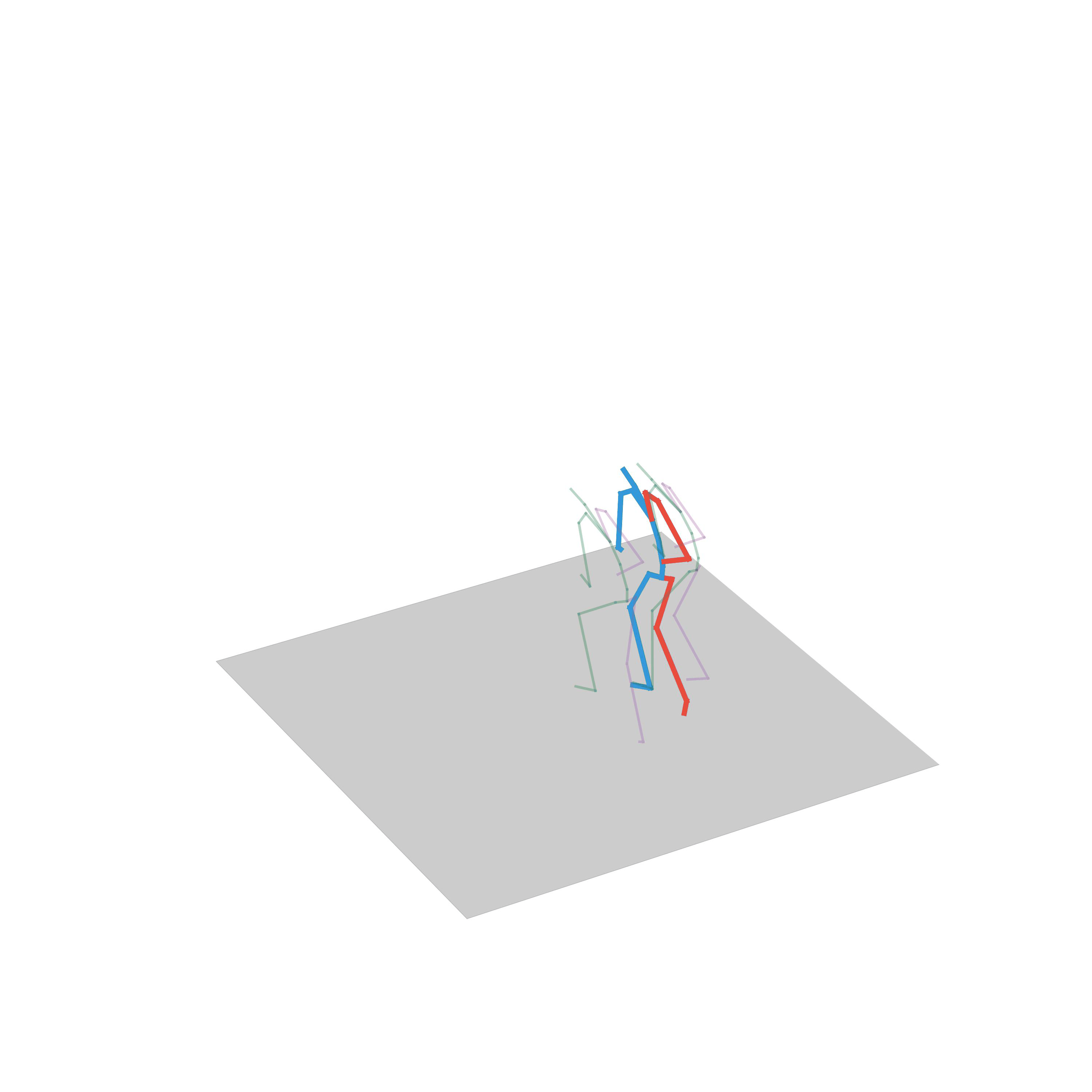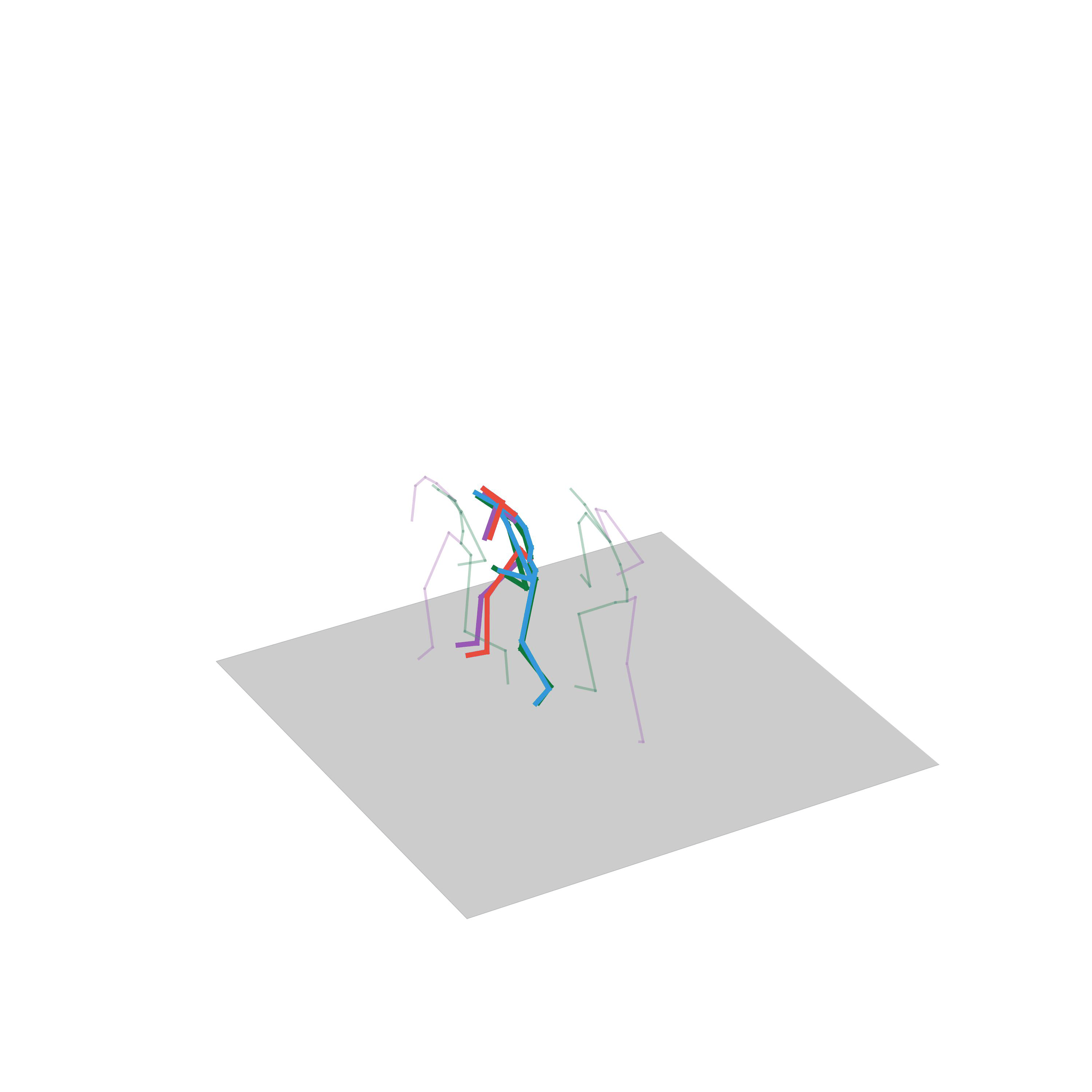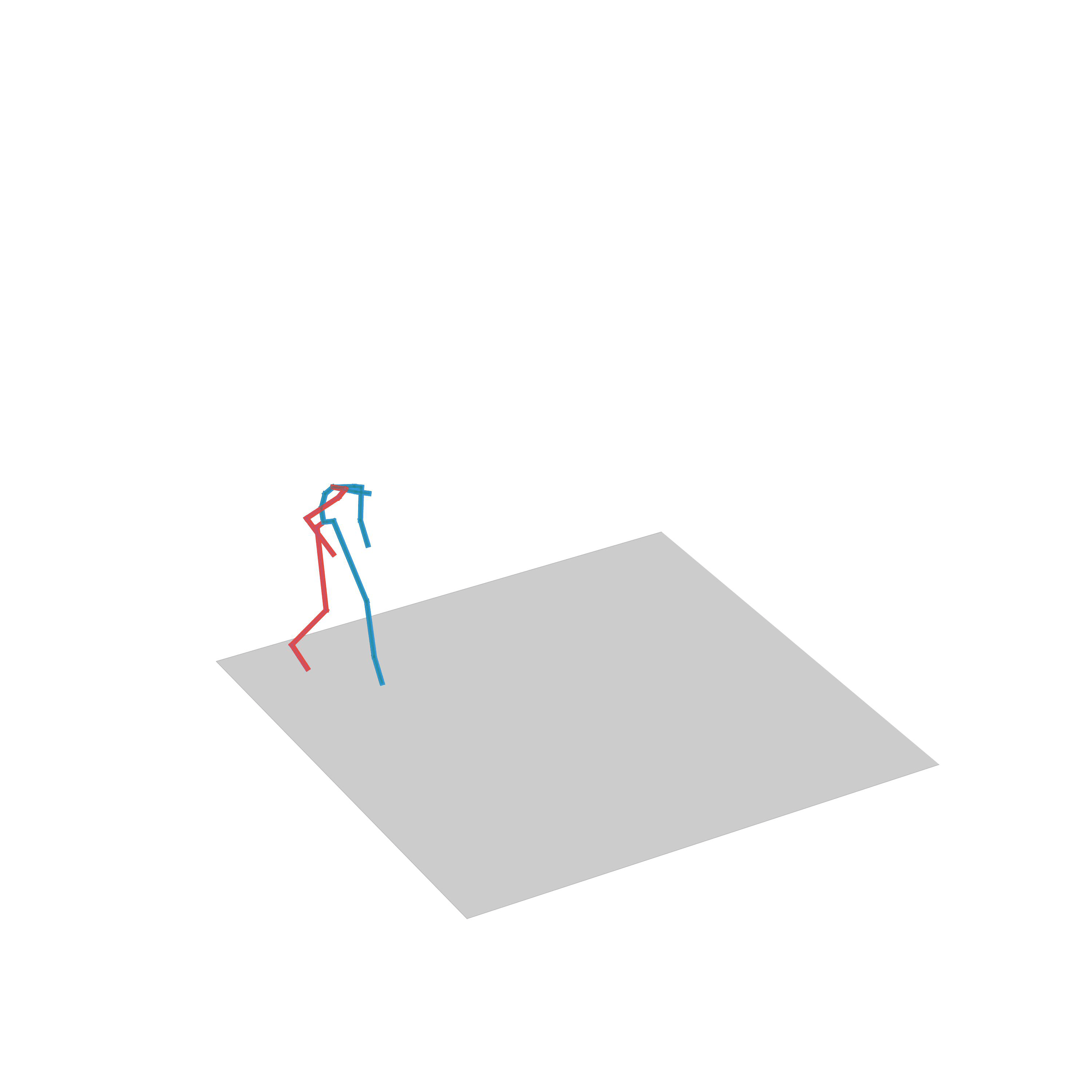
“Walking while avoiding obstacles”
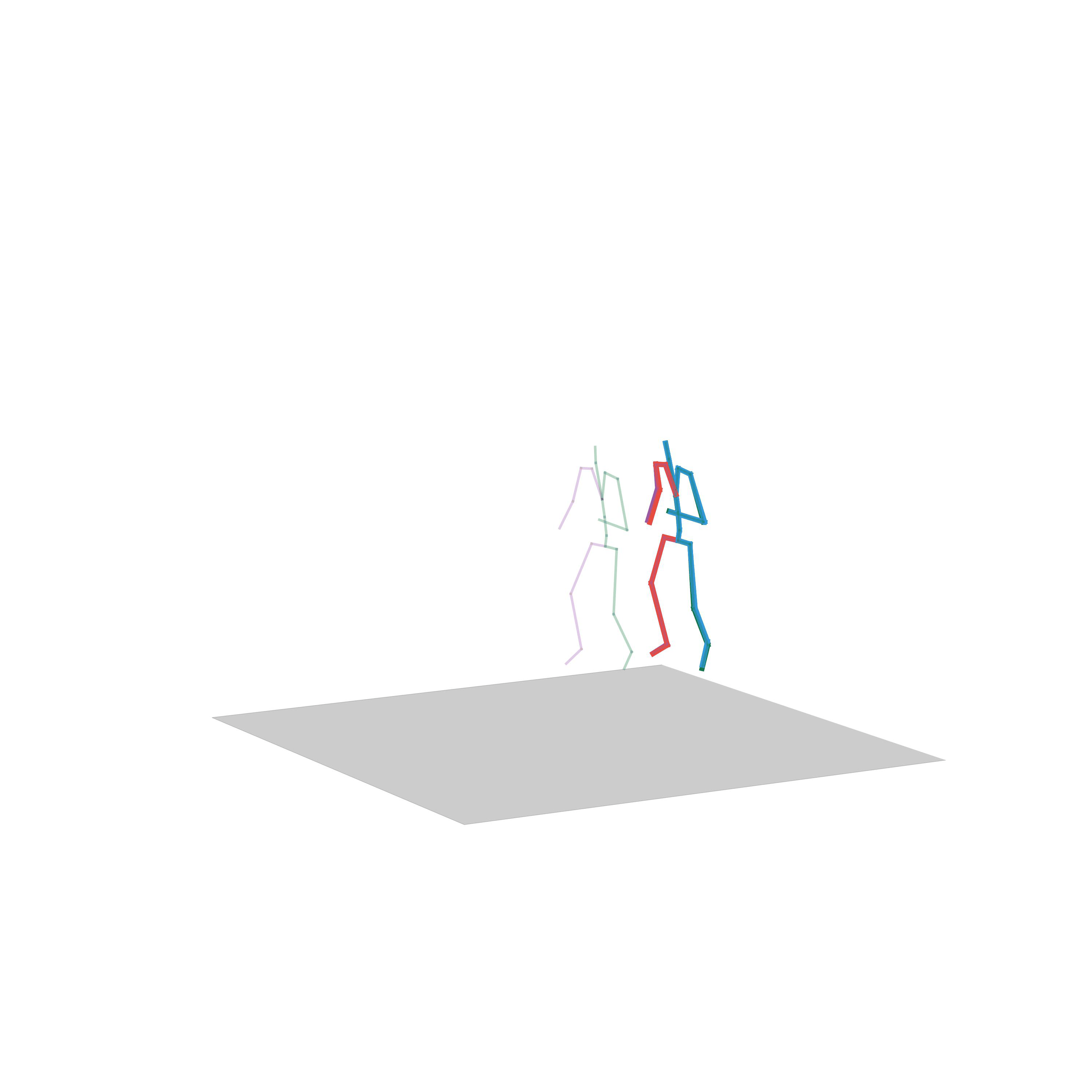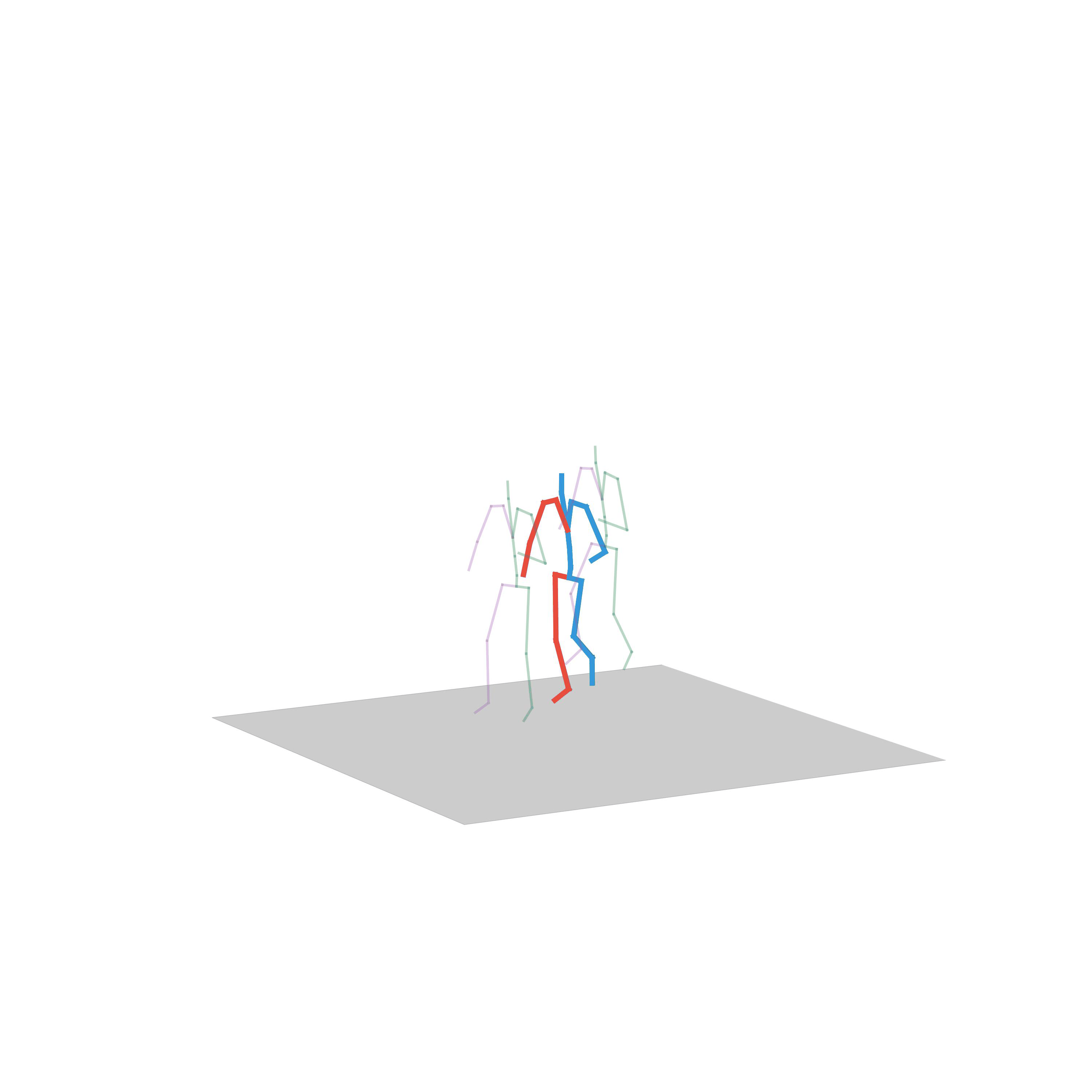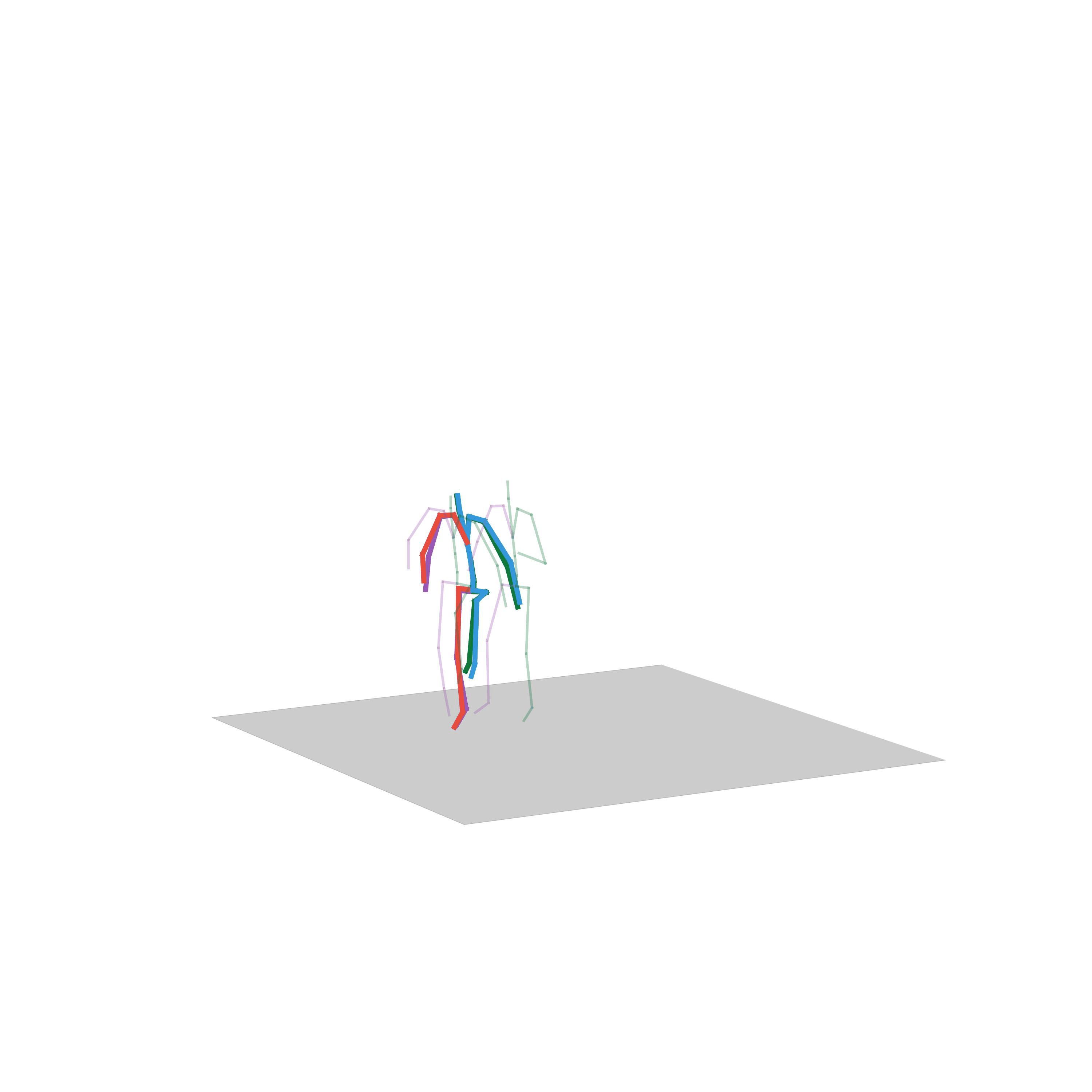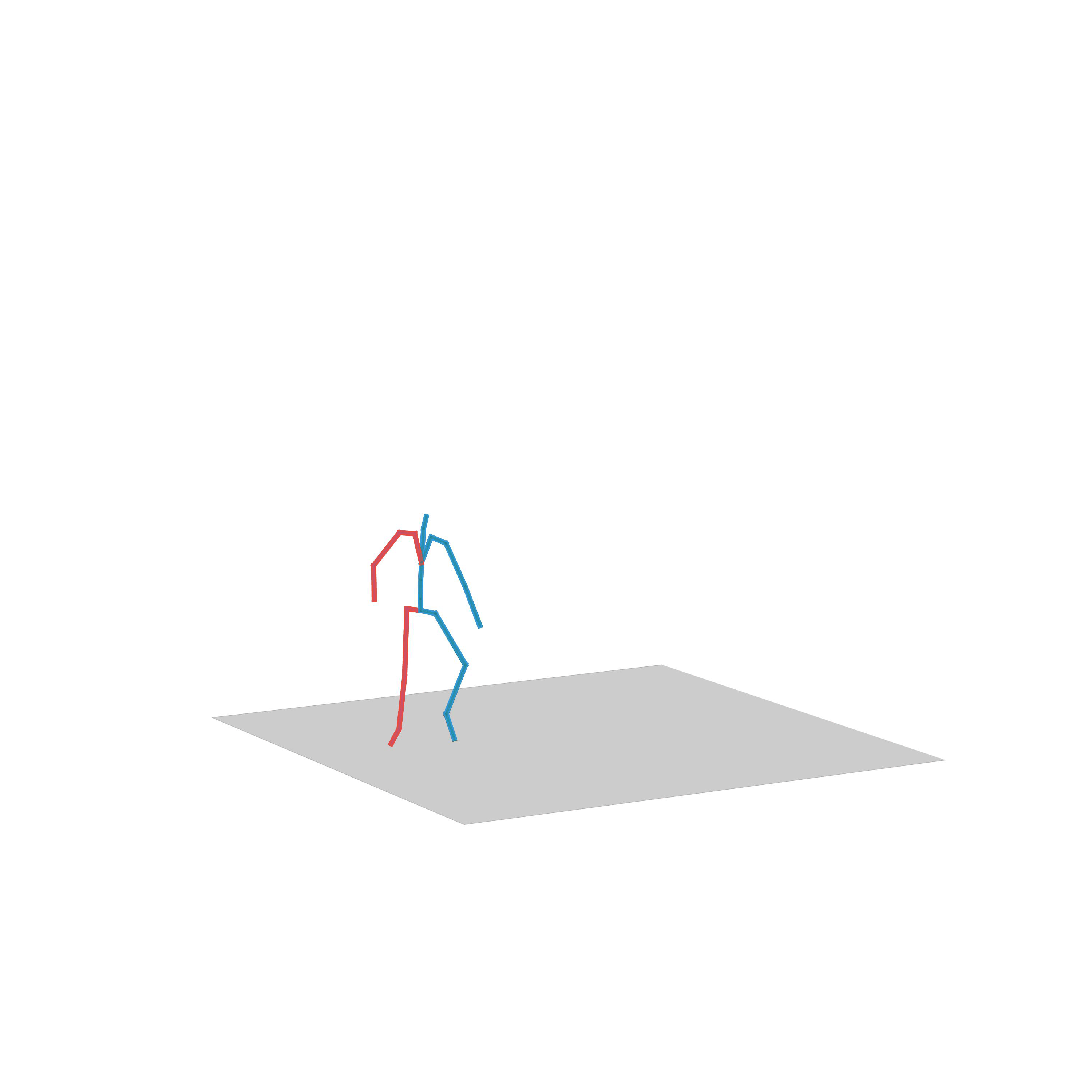
“Crawling to walking”
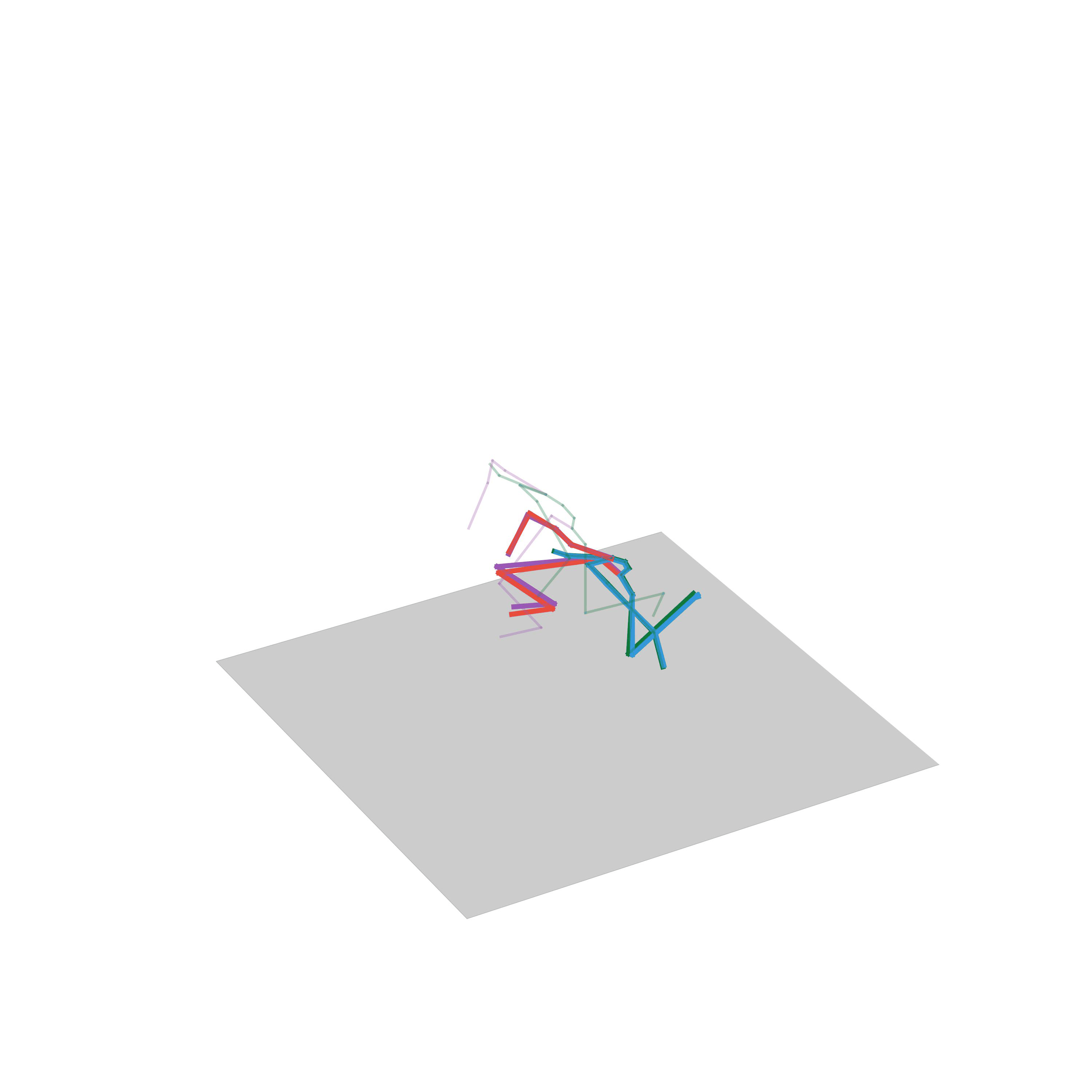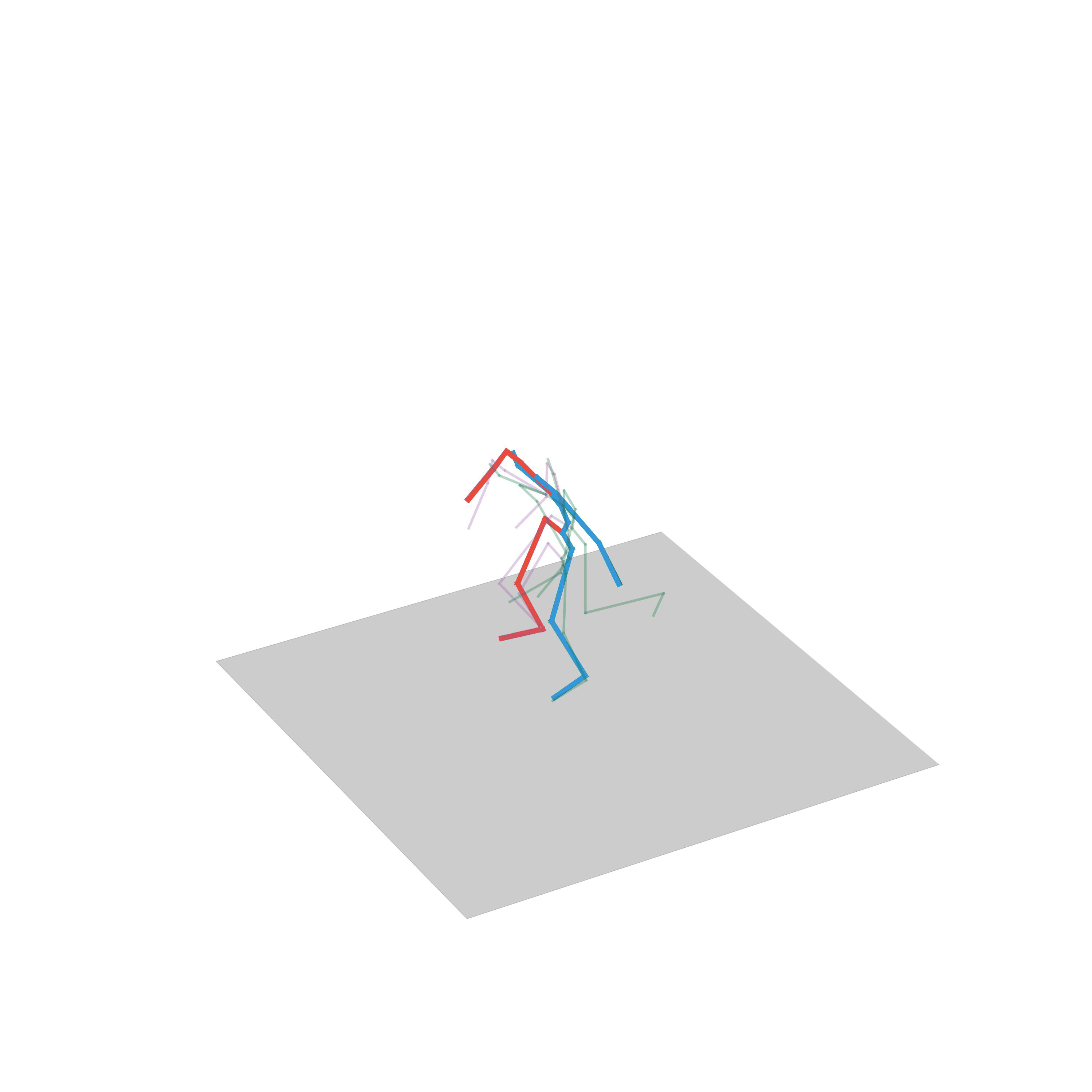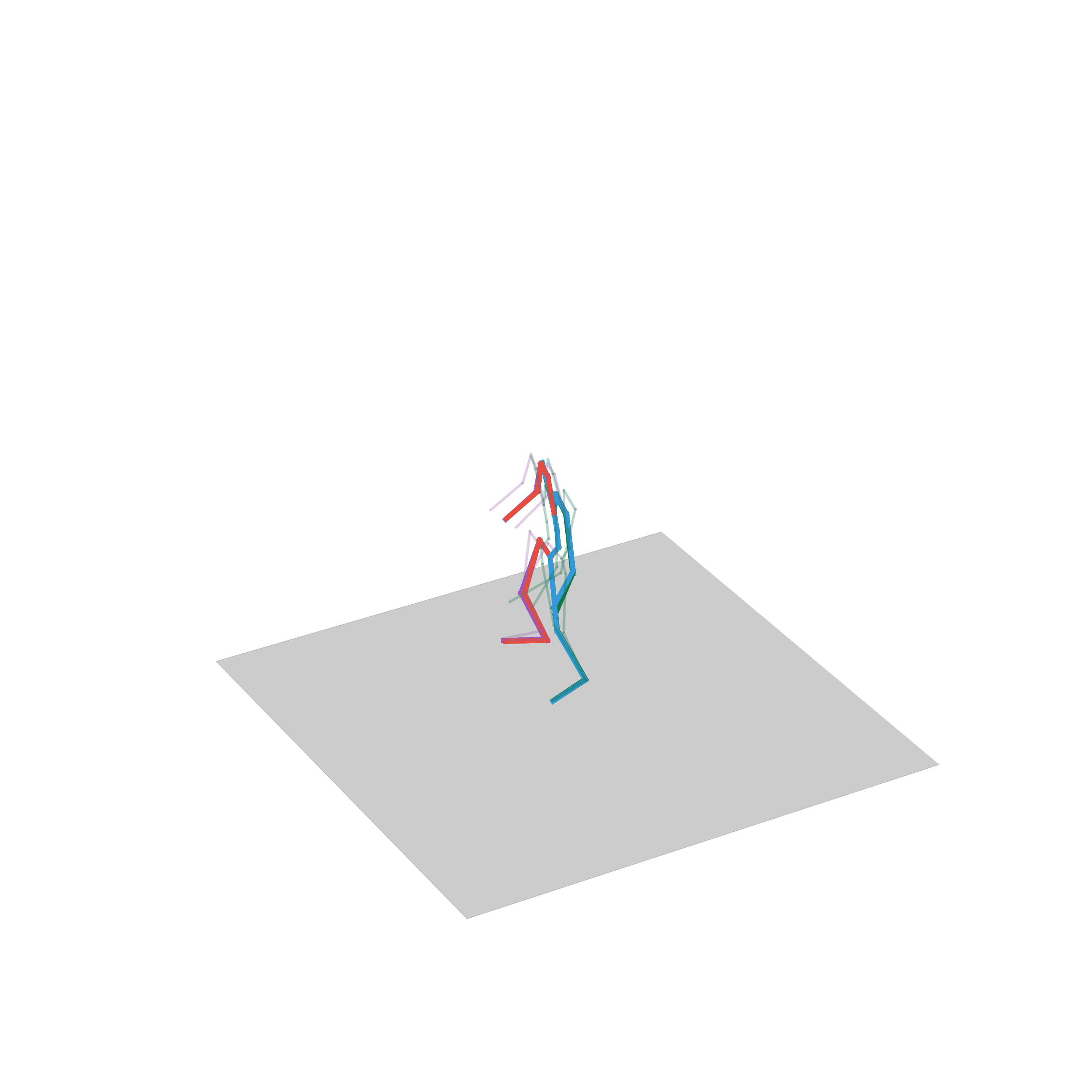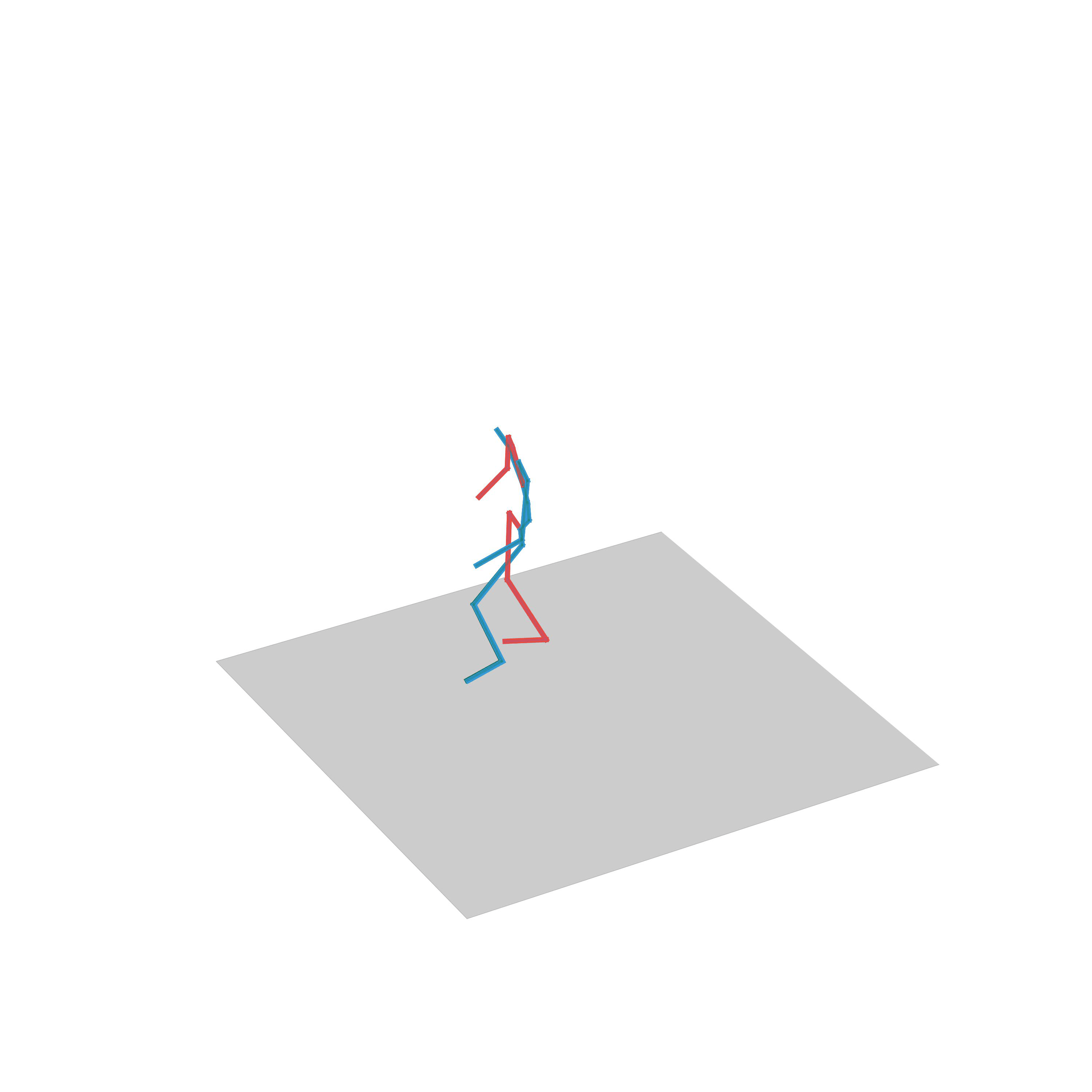
“Running while avoiding obstacles”
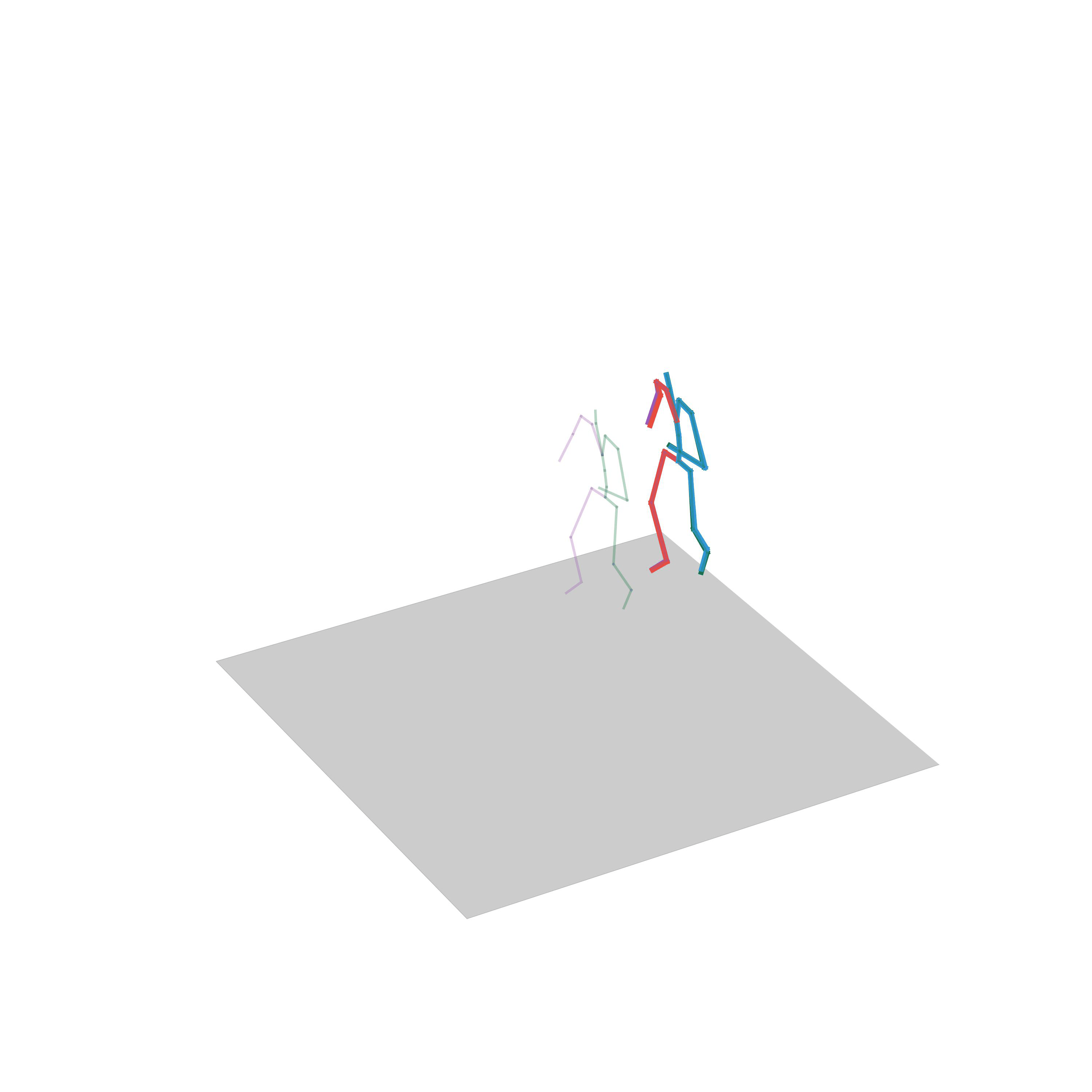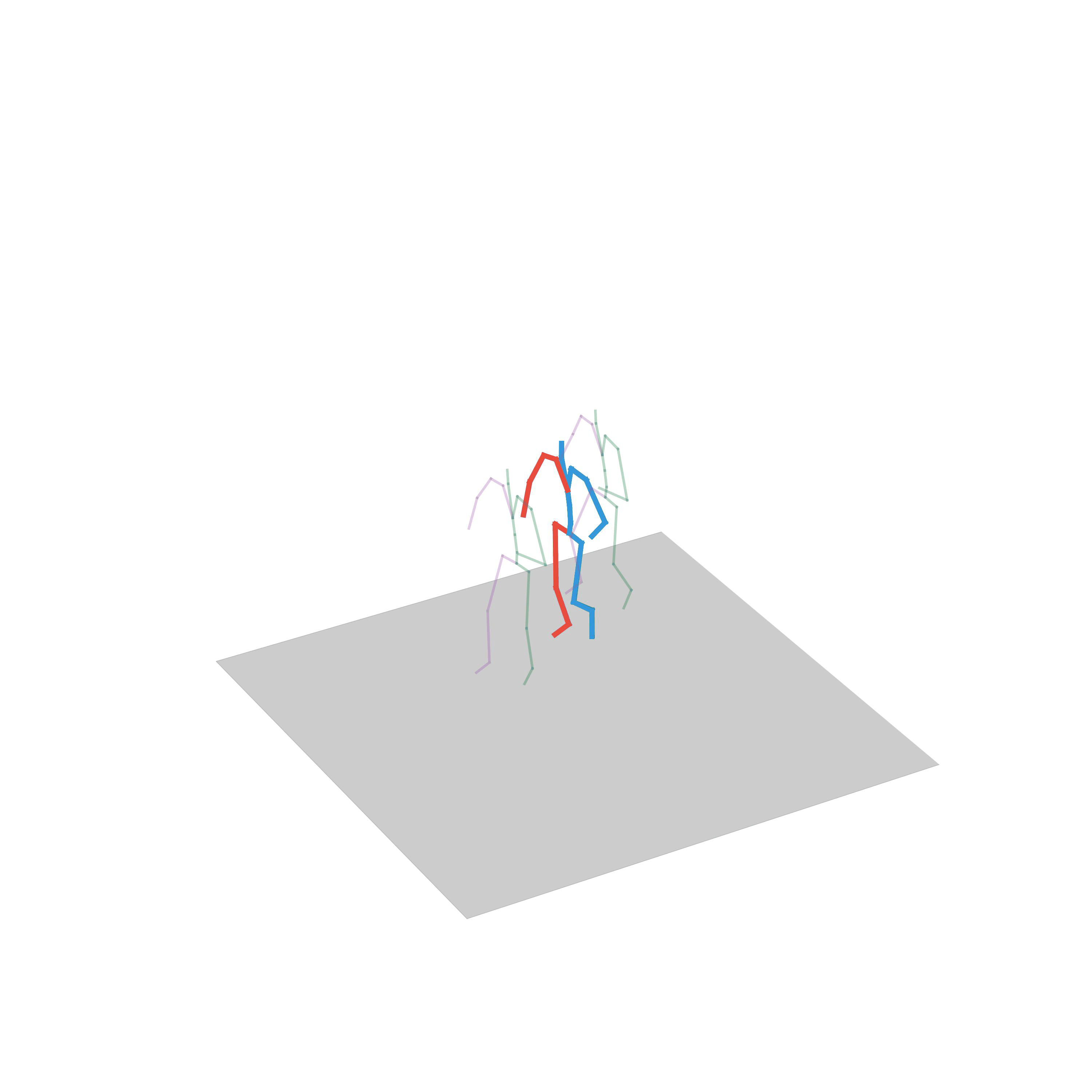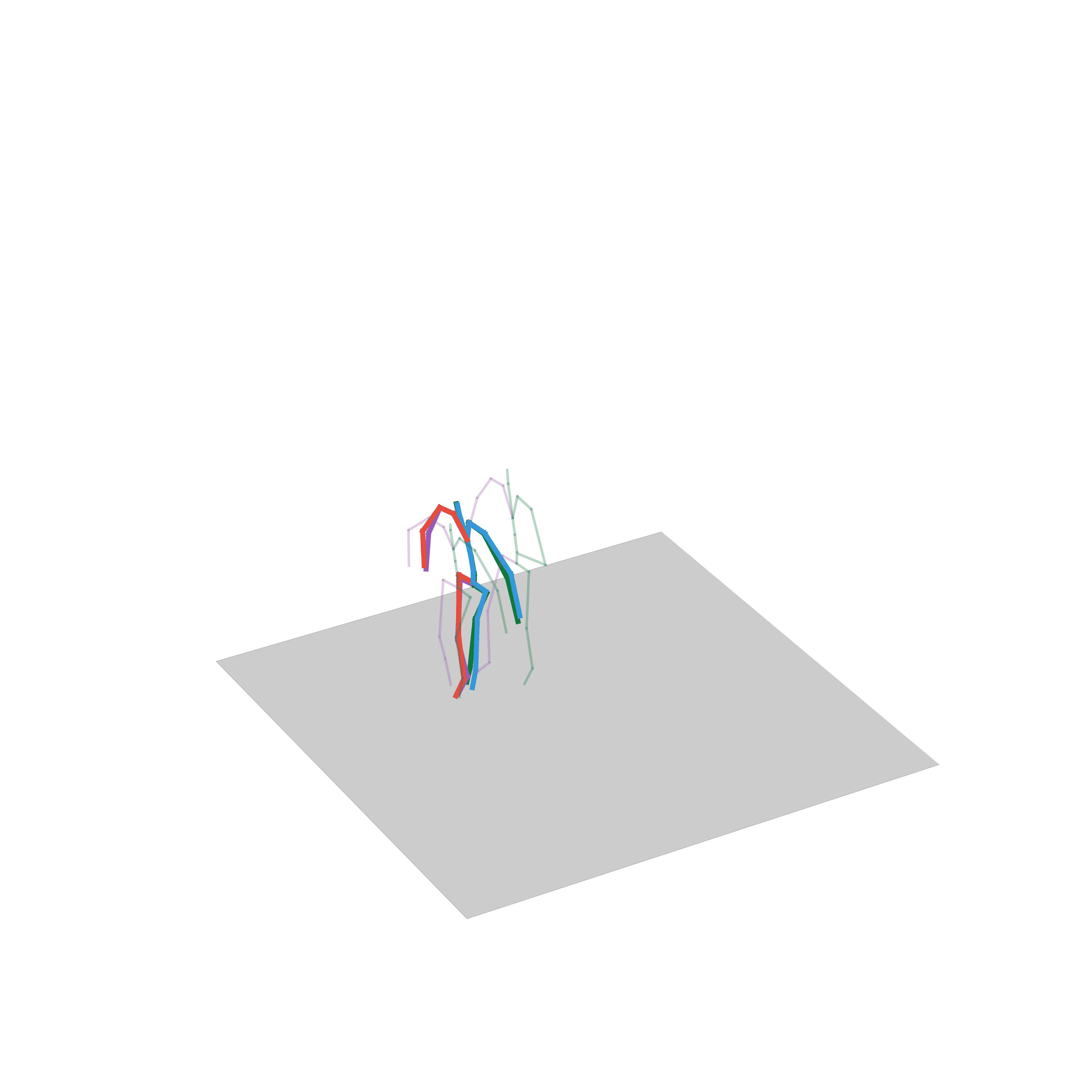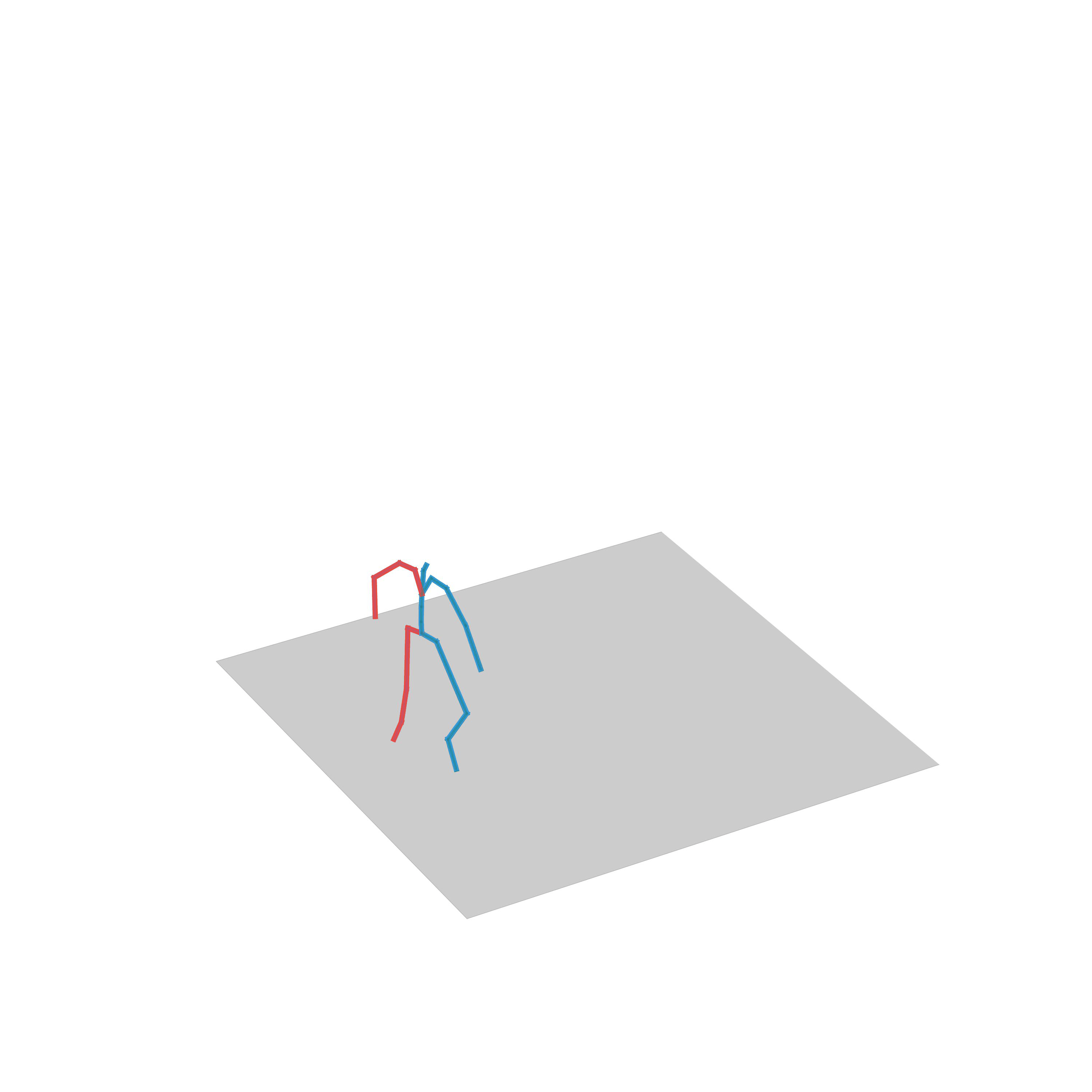
“Walking avoiding obstacles”
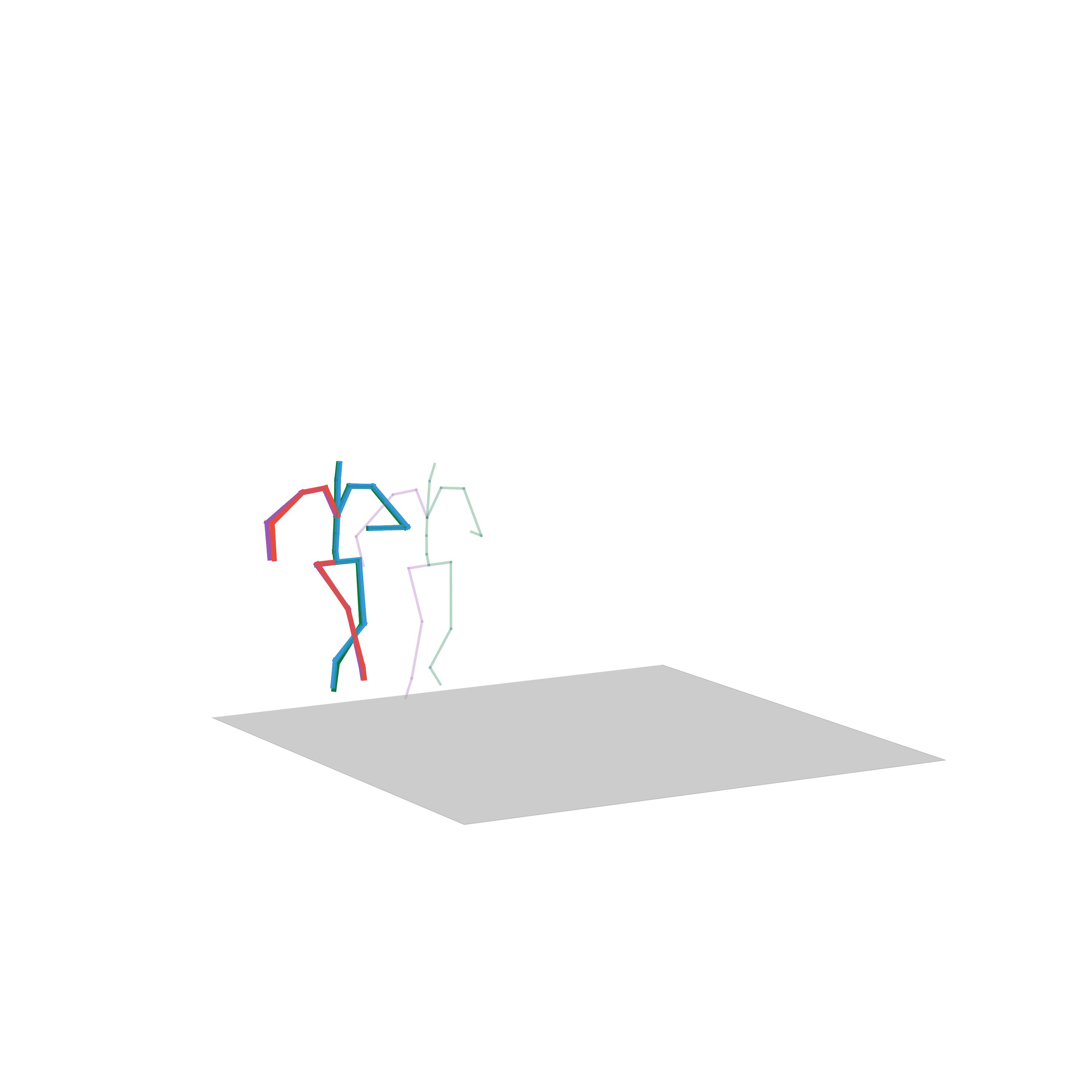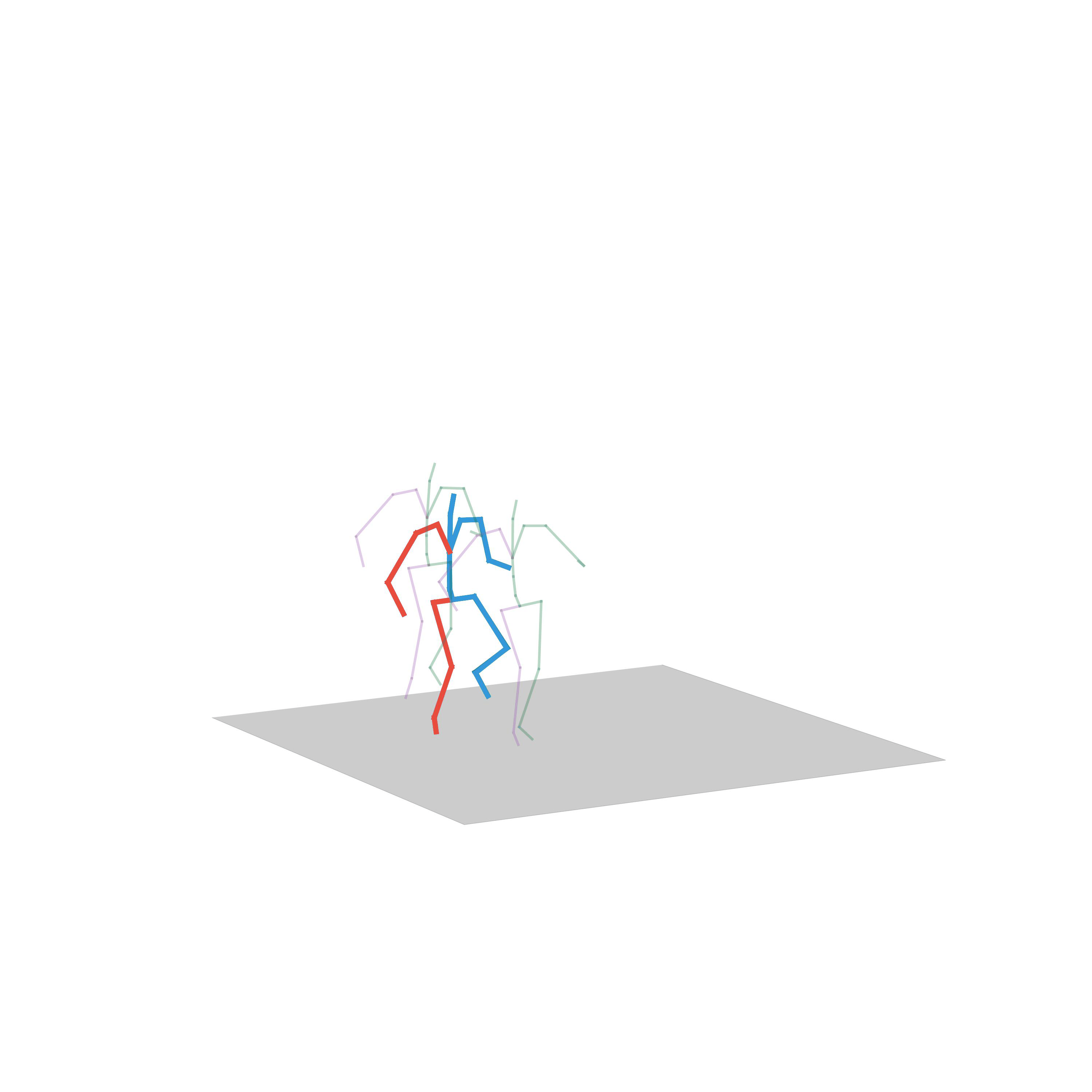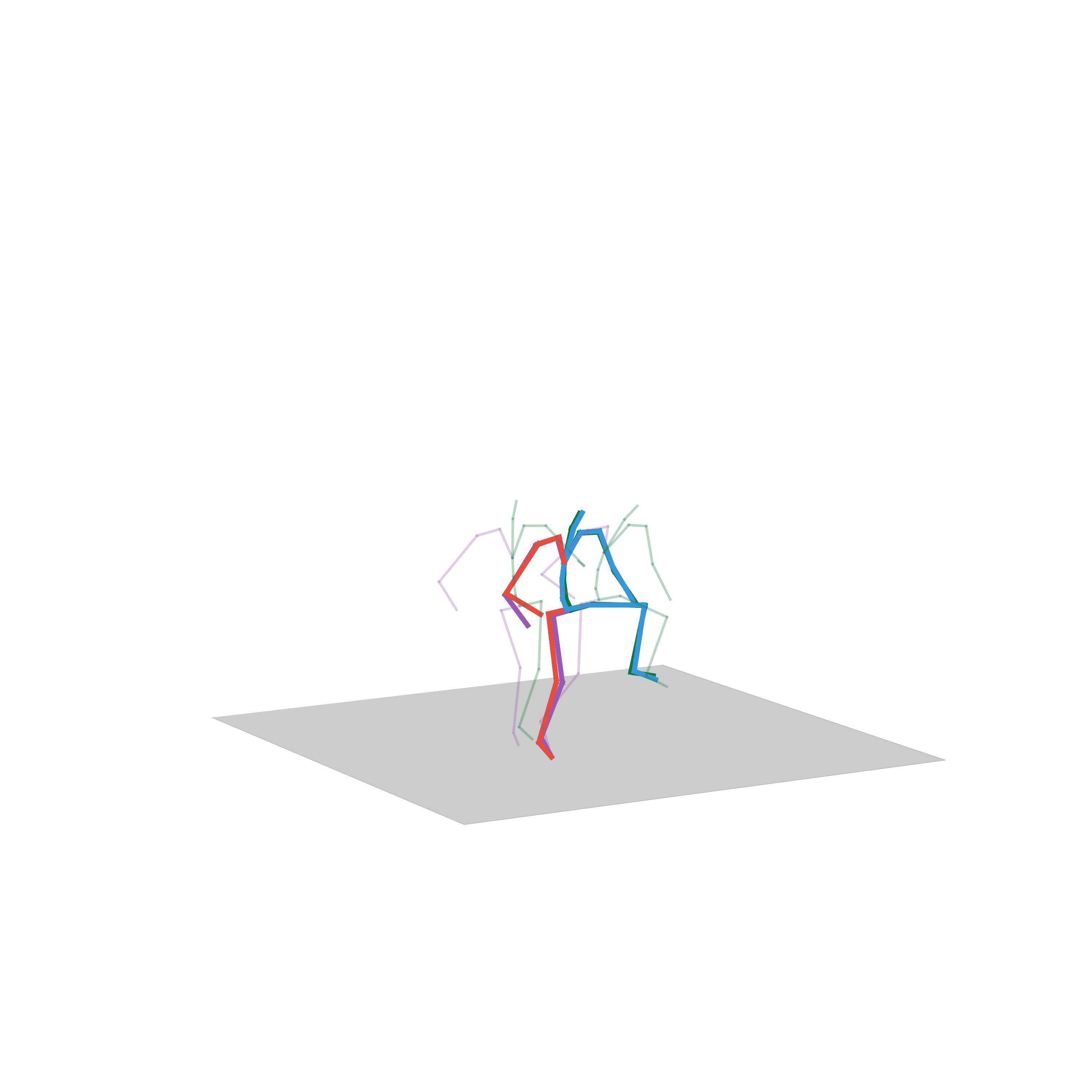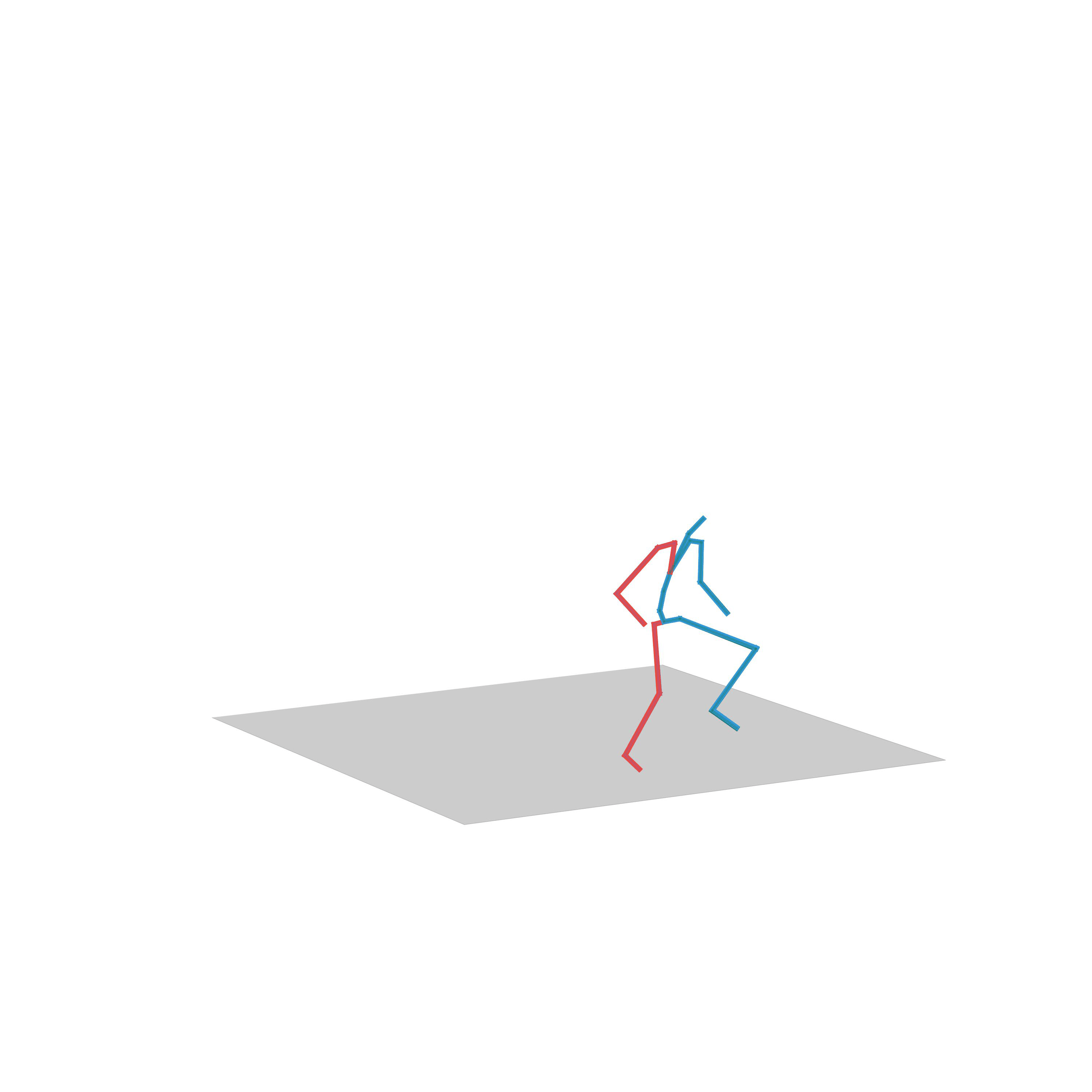
“Walking with a gun”
“Walking with a gun”
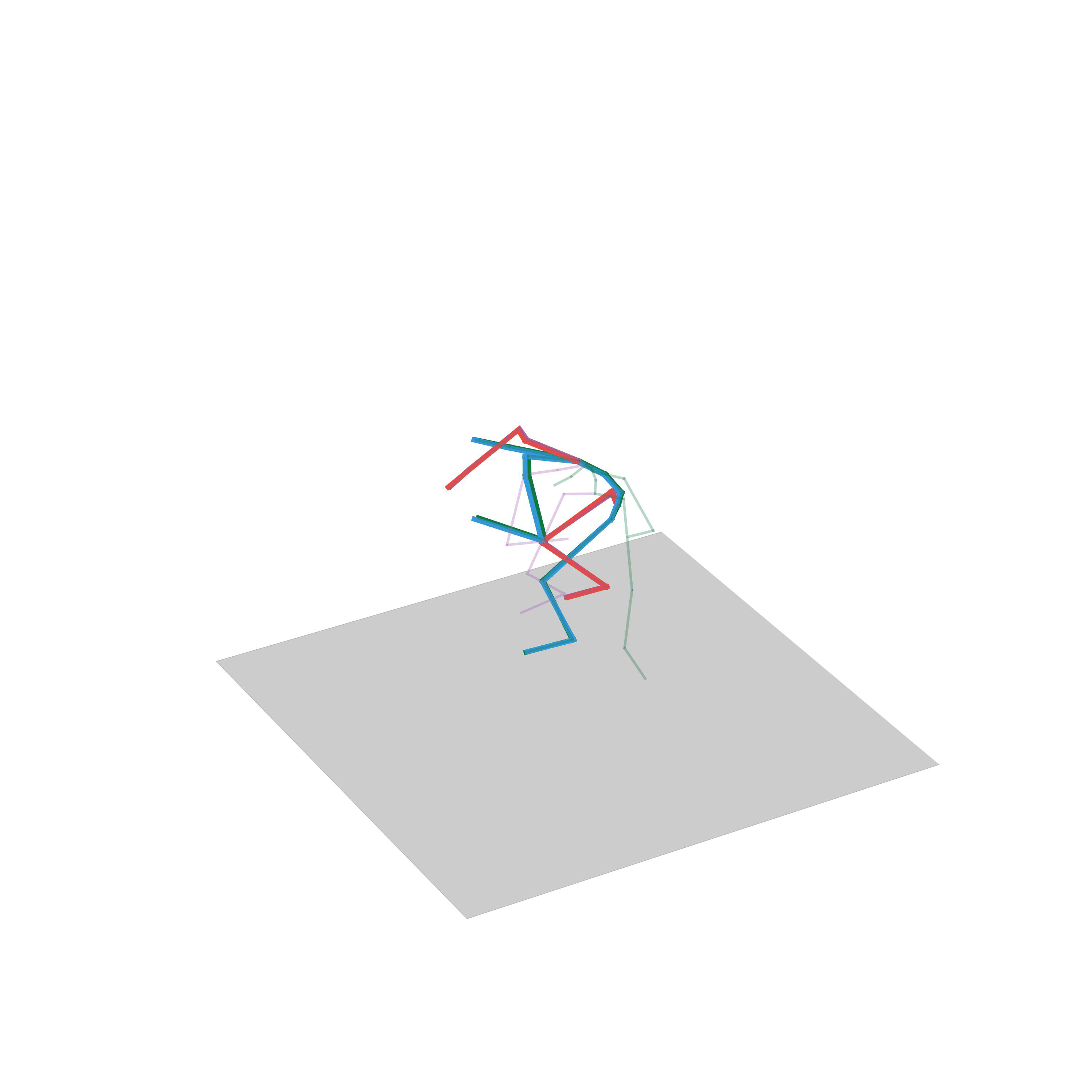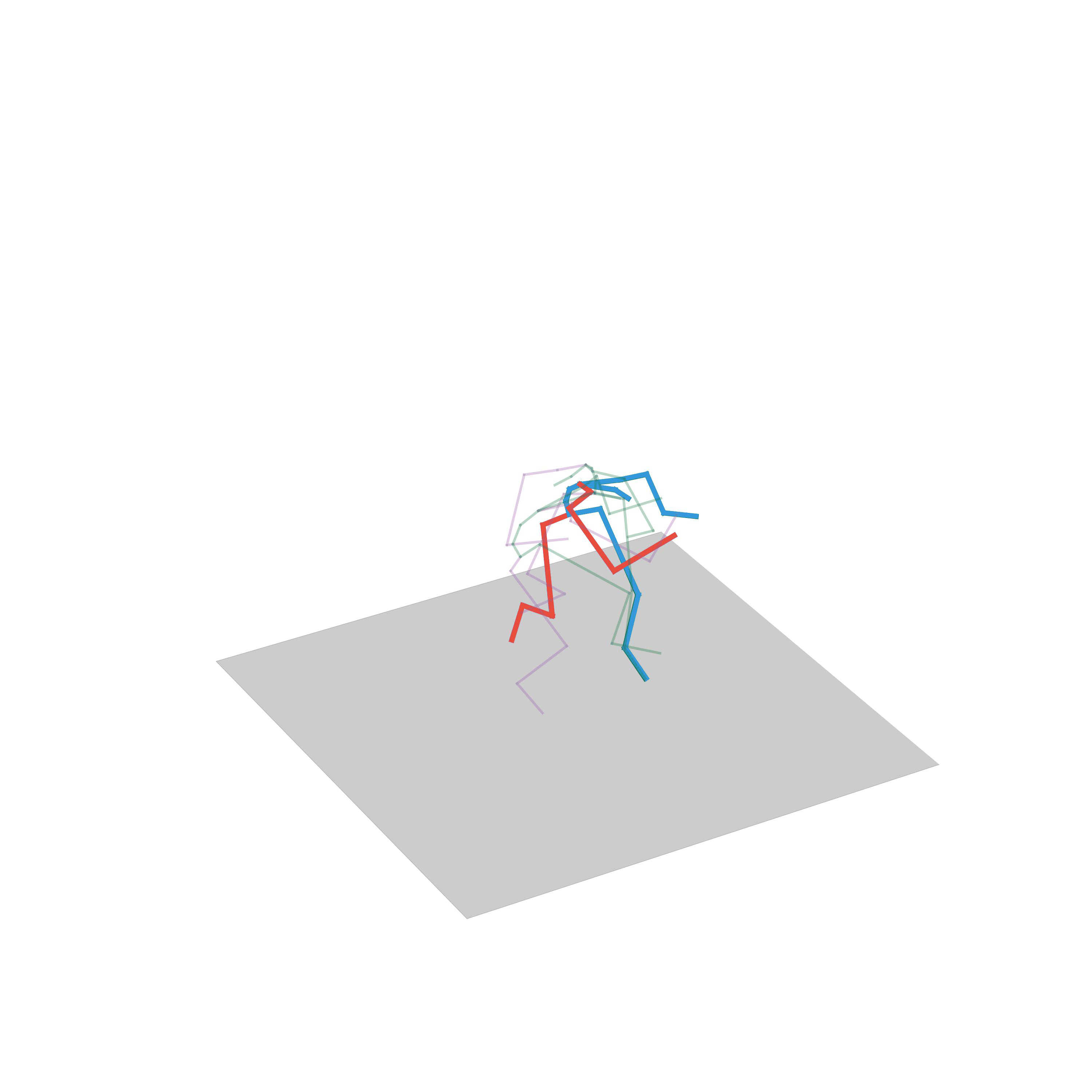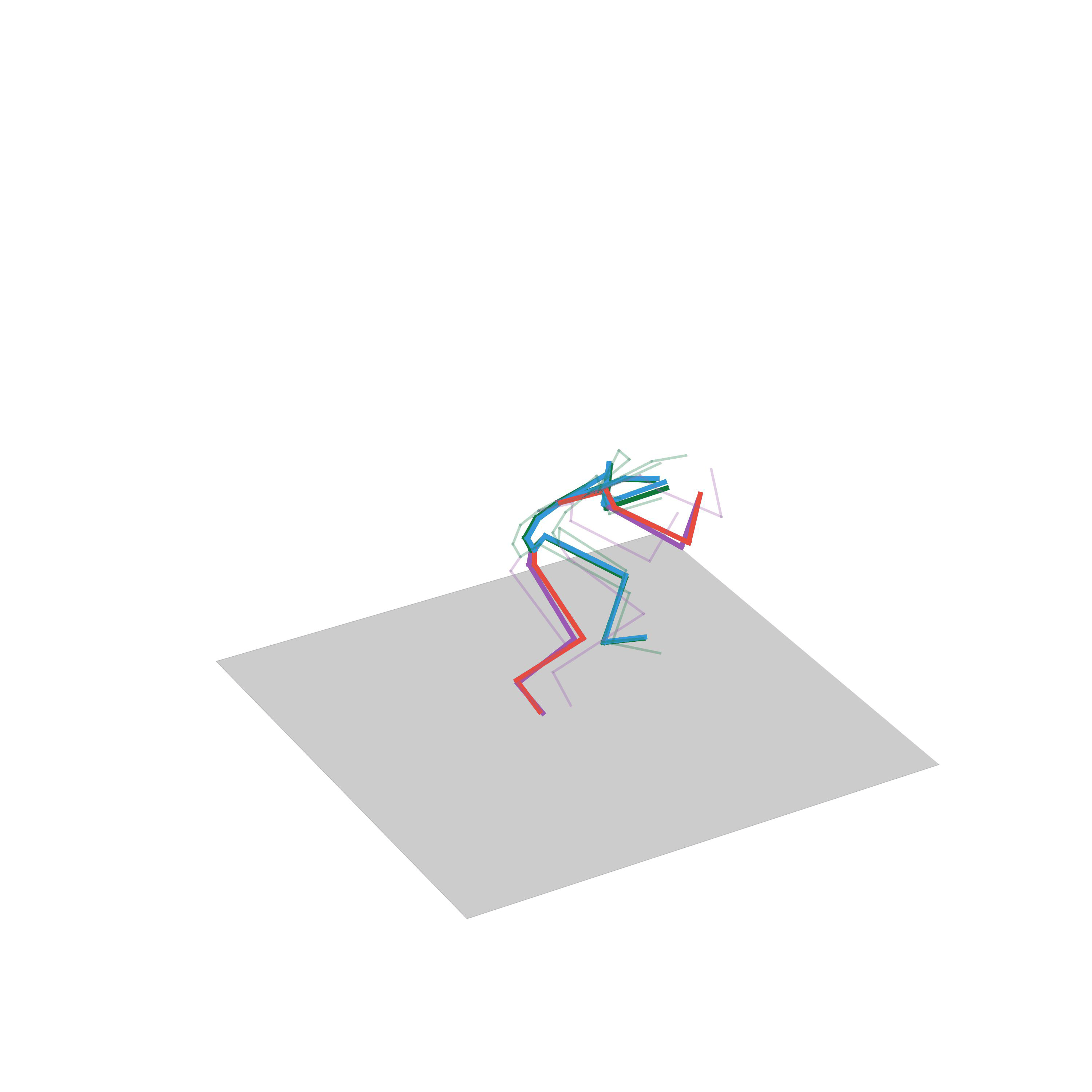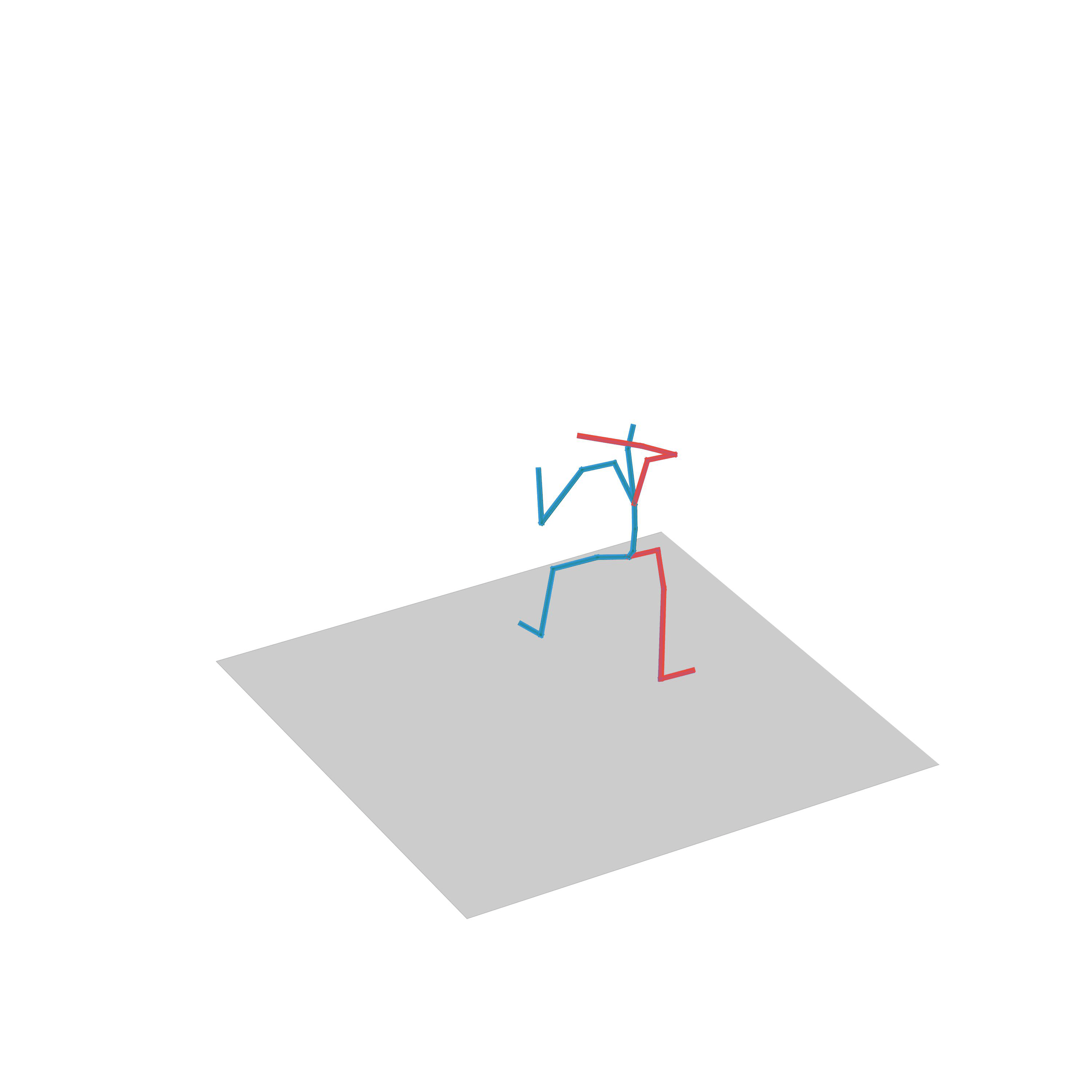
“Run, stop and go back”
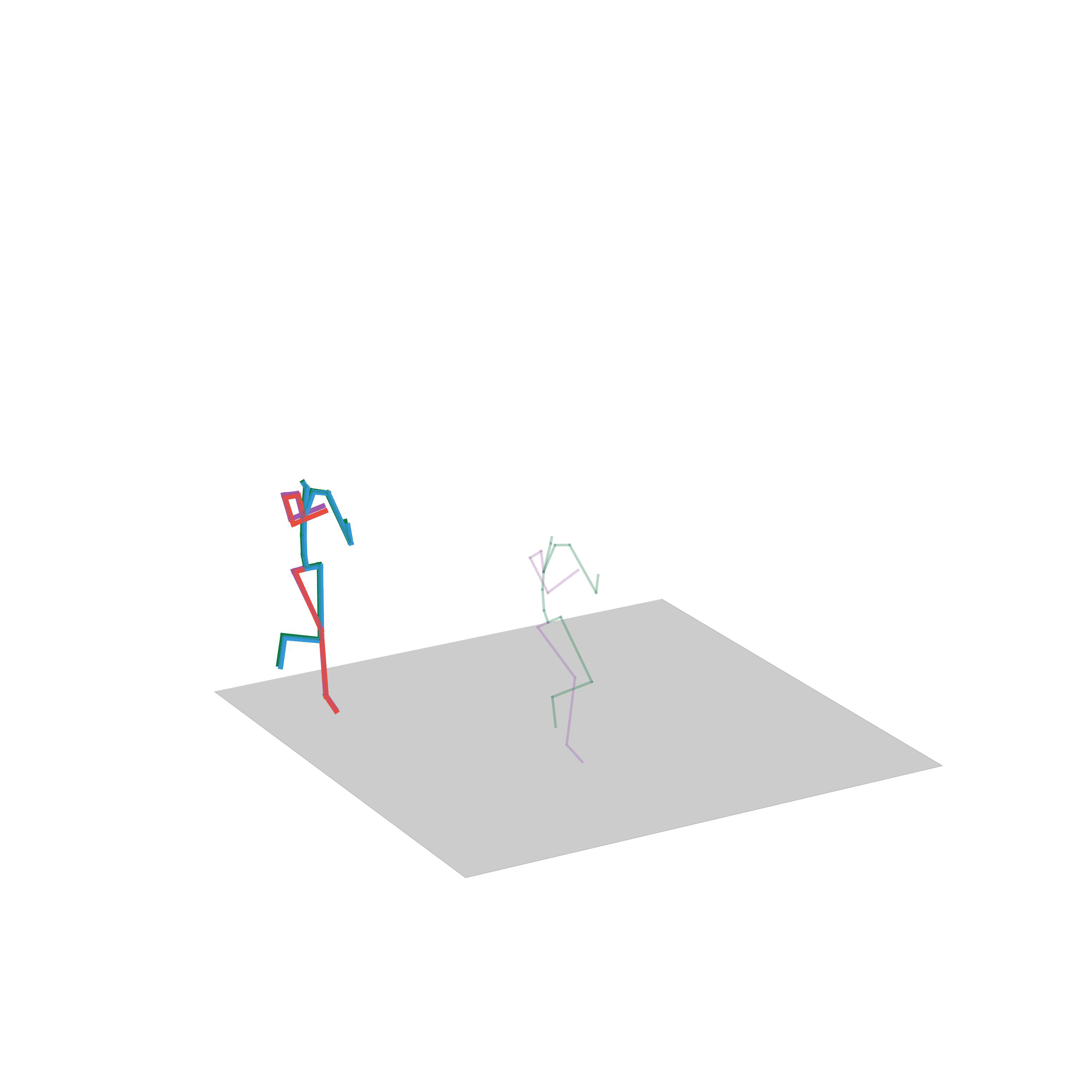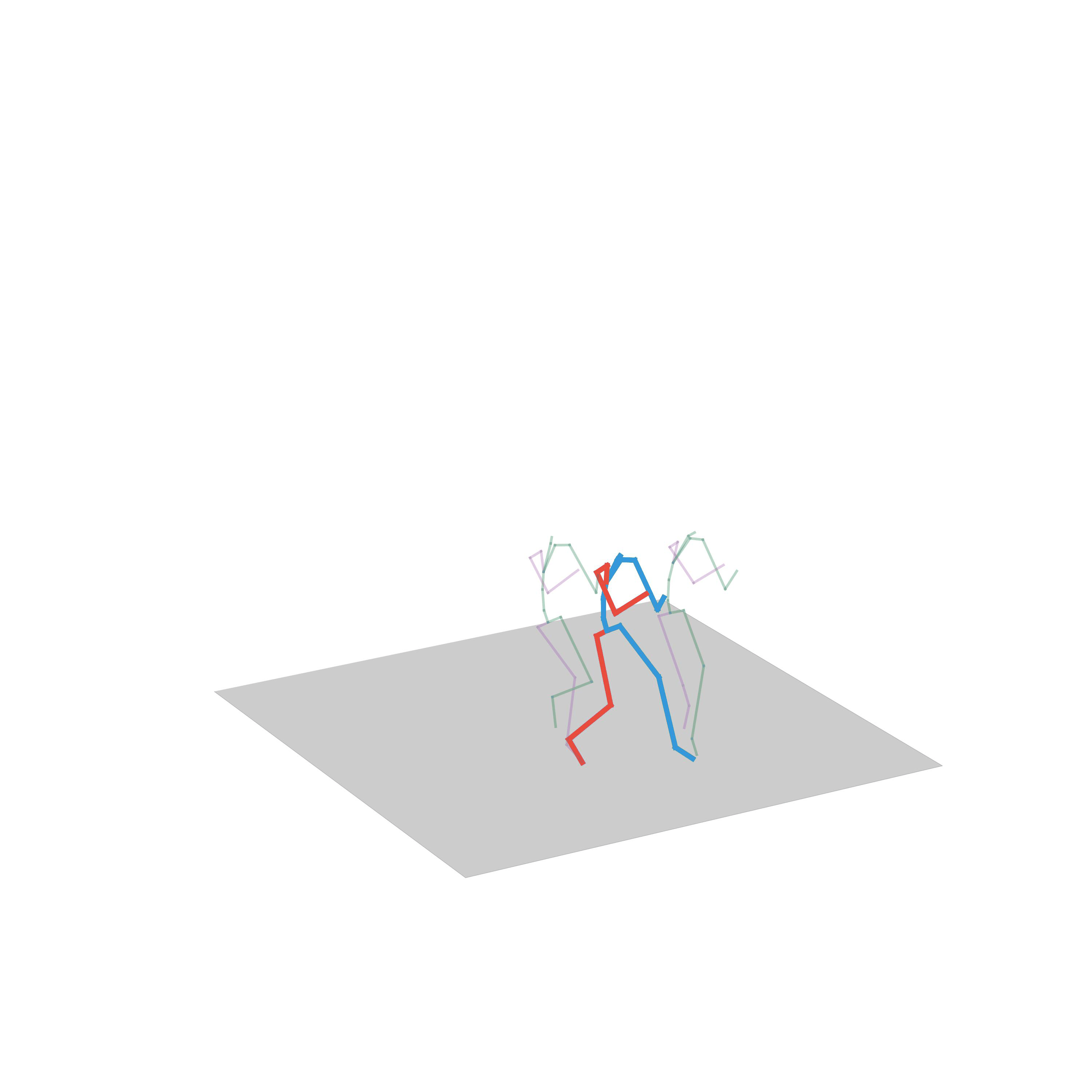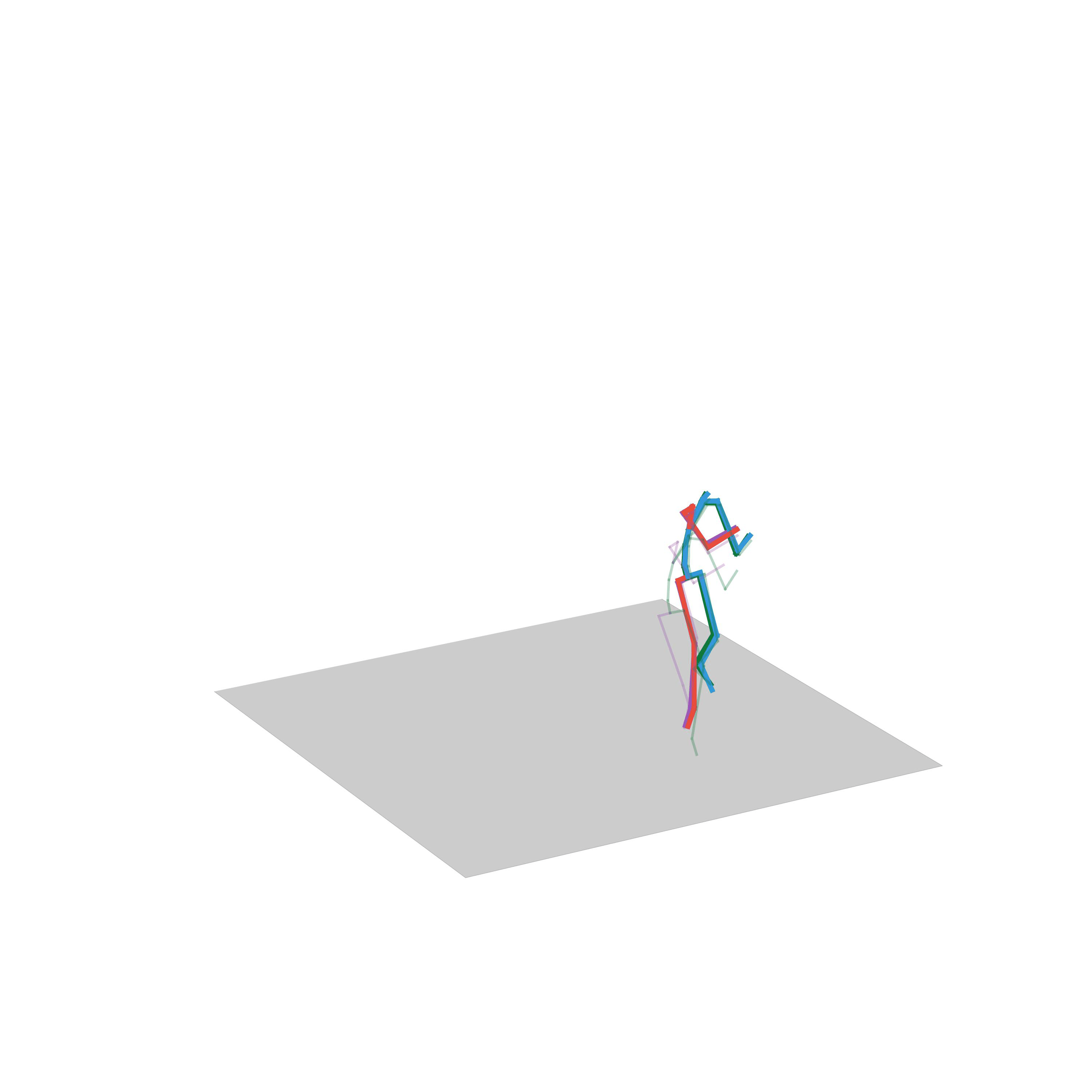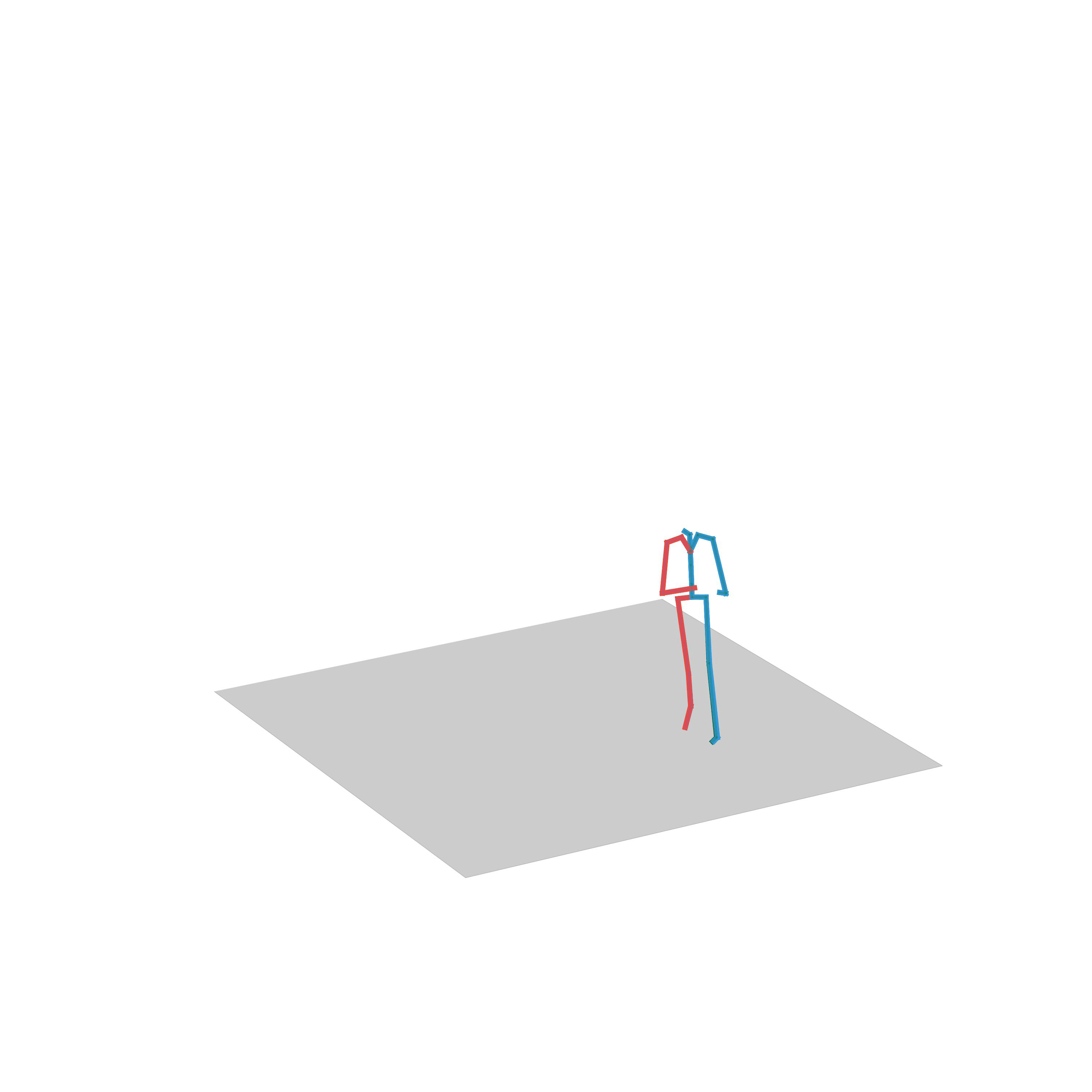
“Walking to crawling”
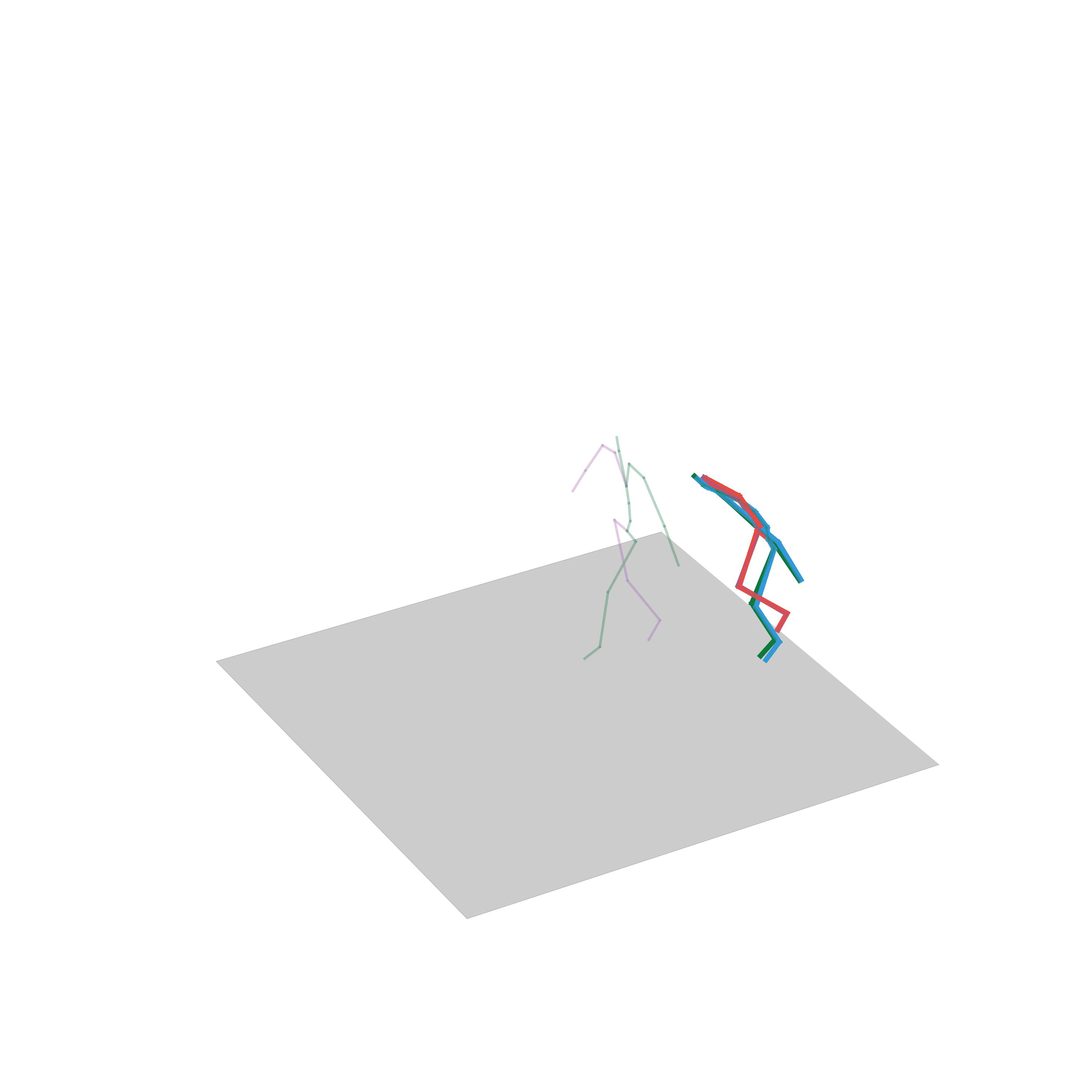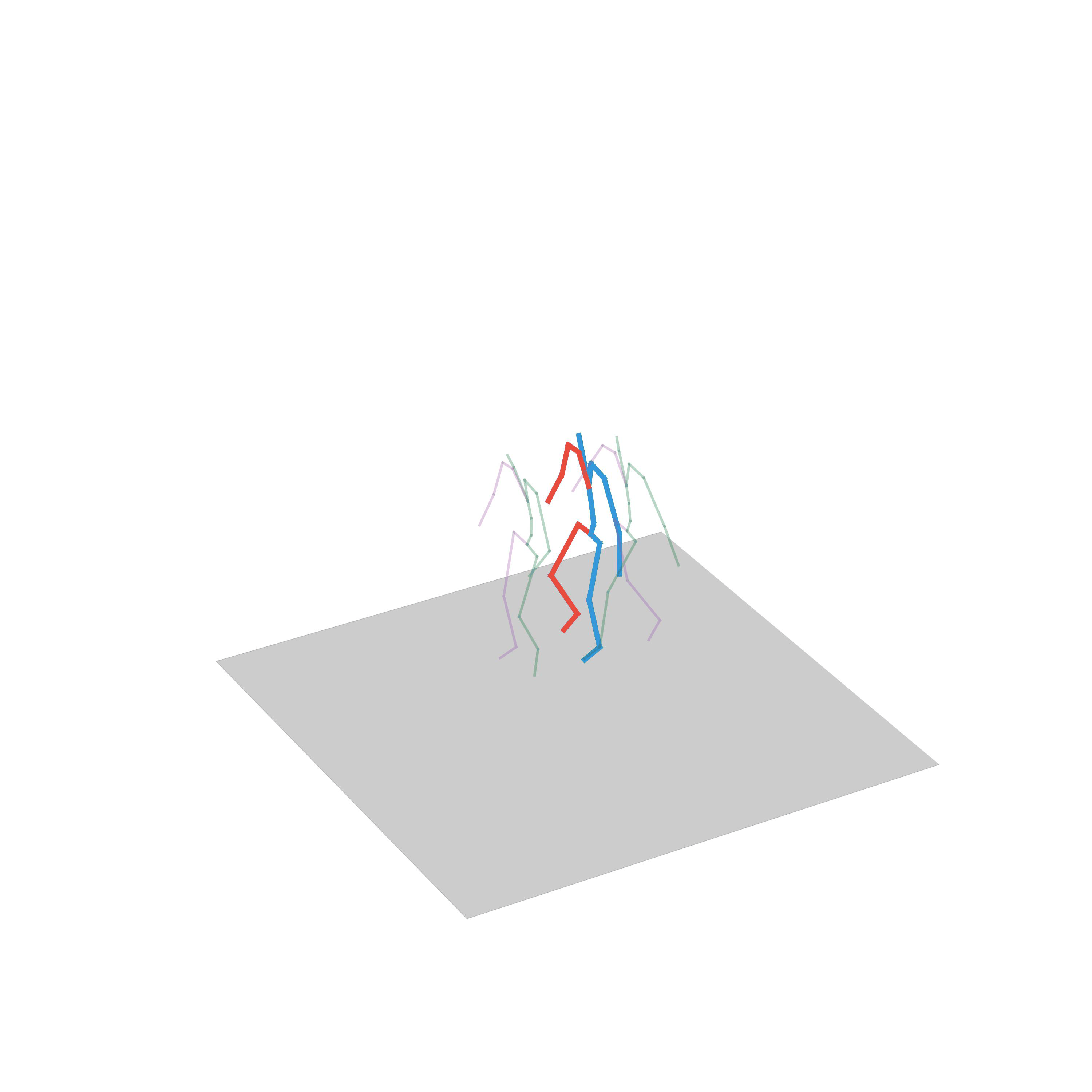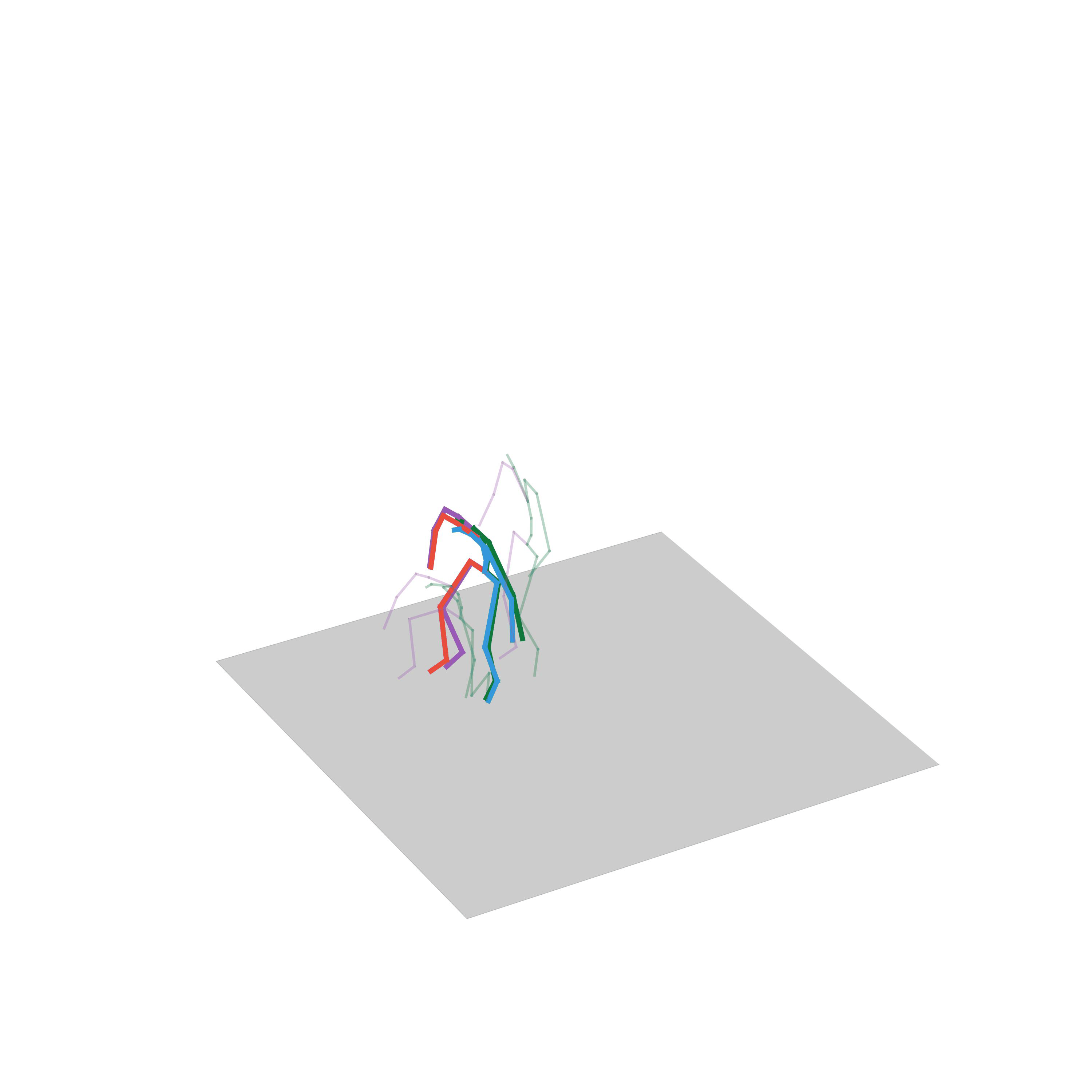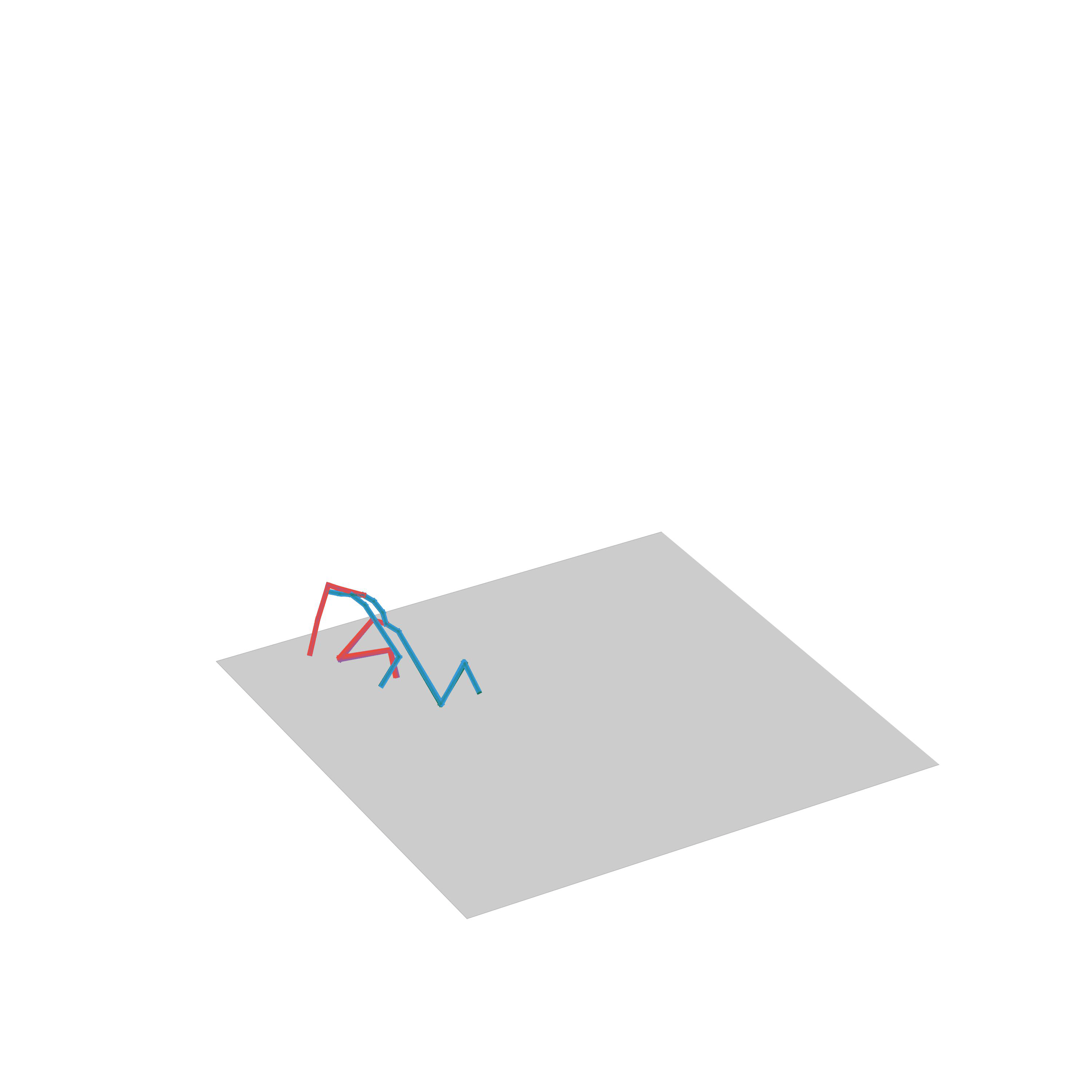
“Walking, but then being pushed”
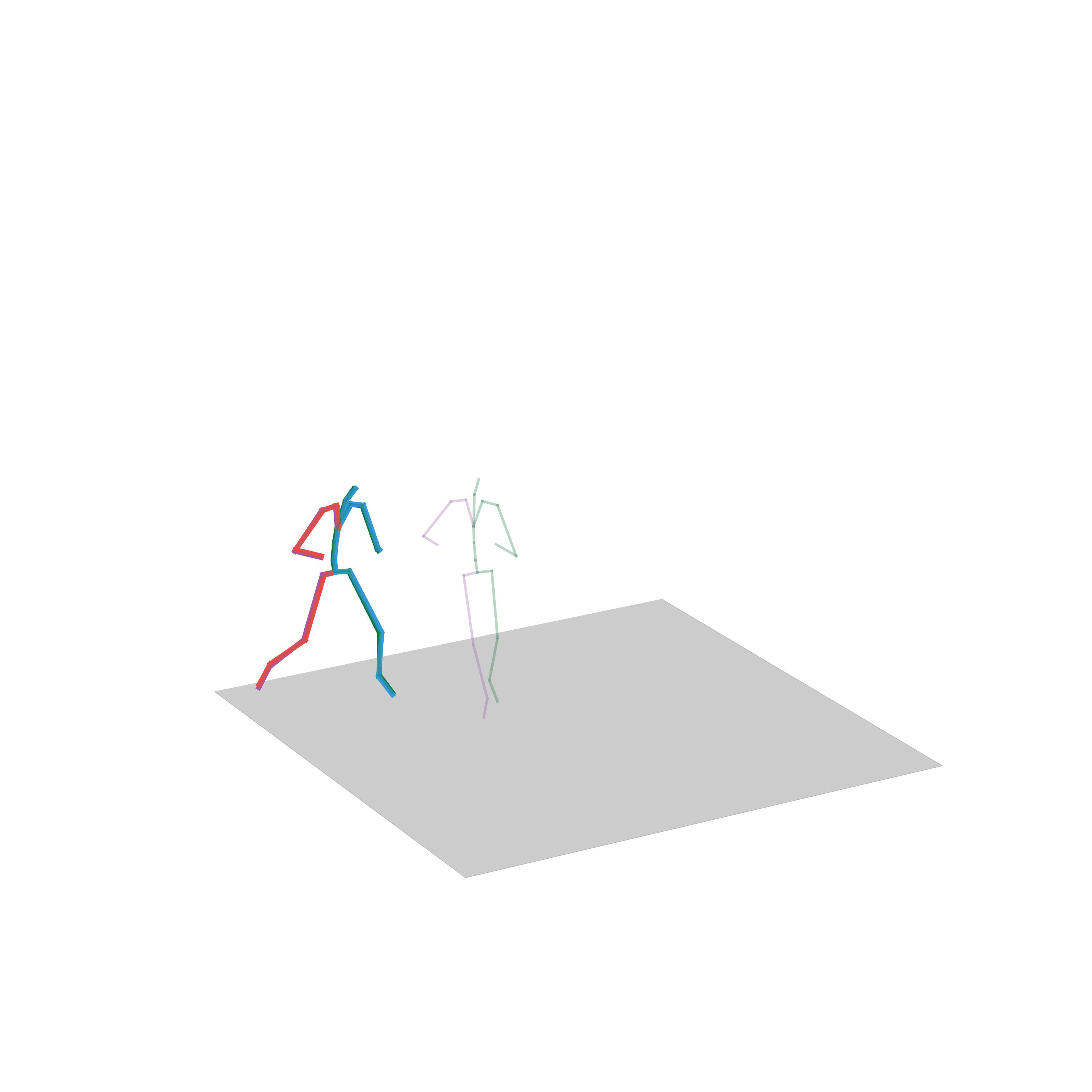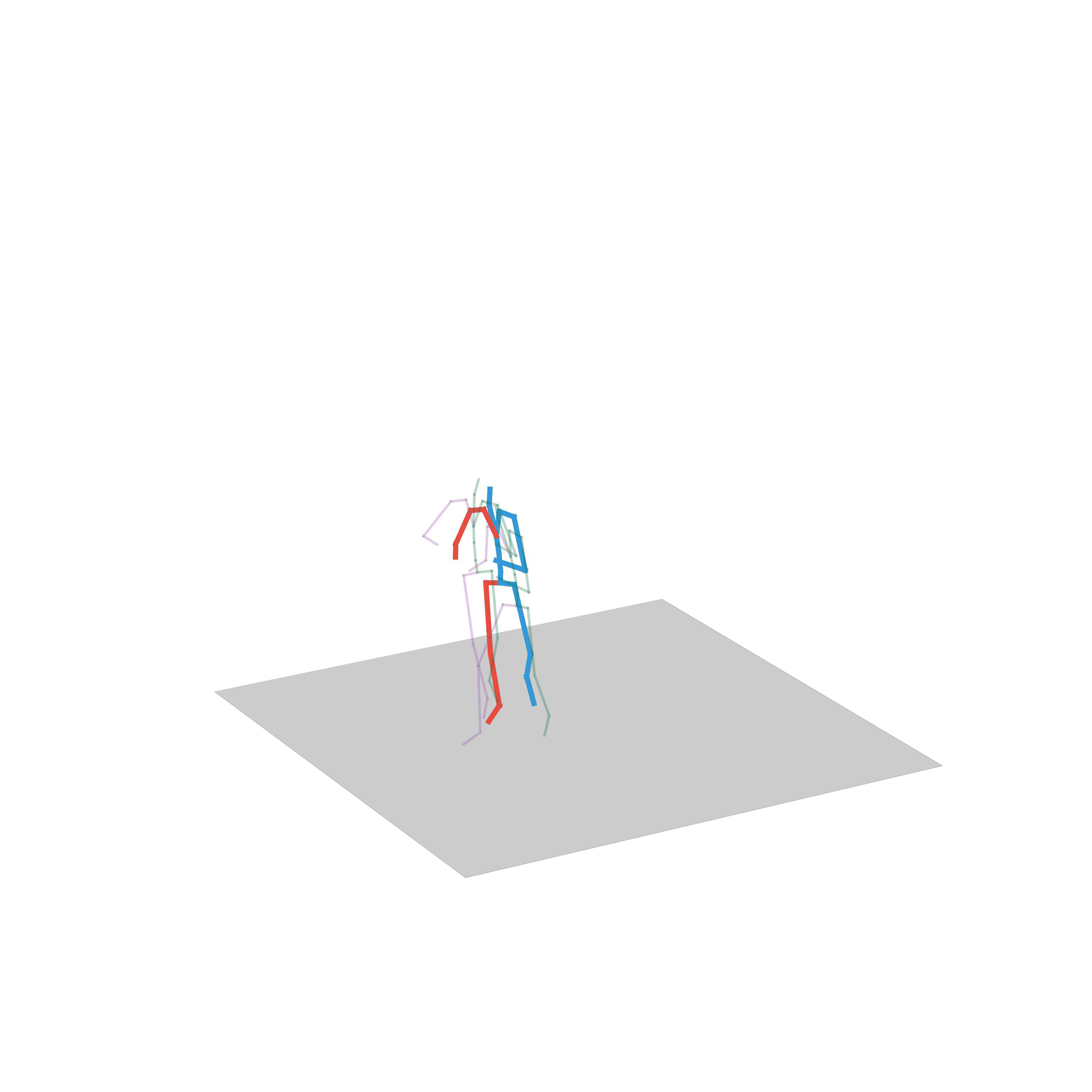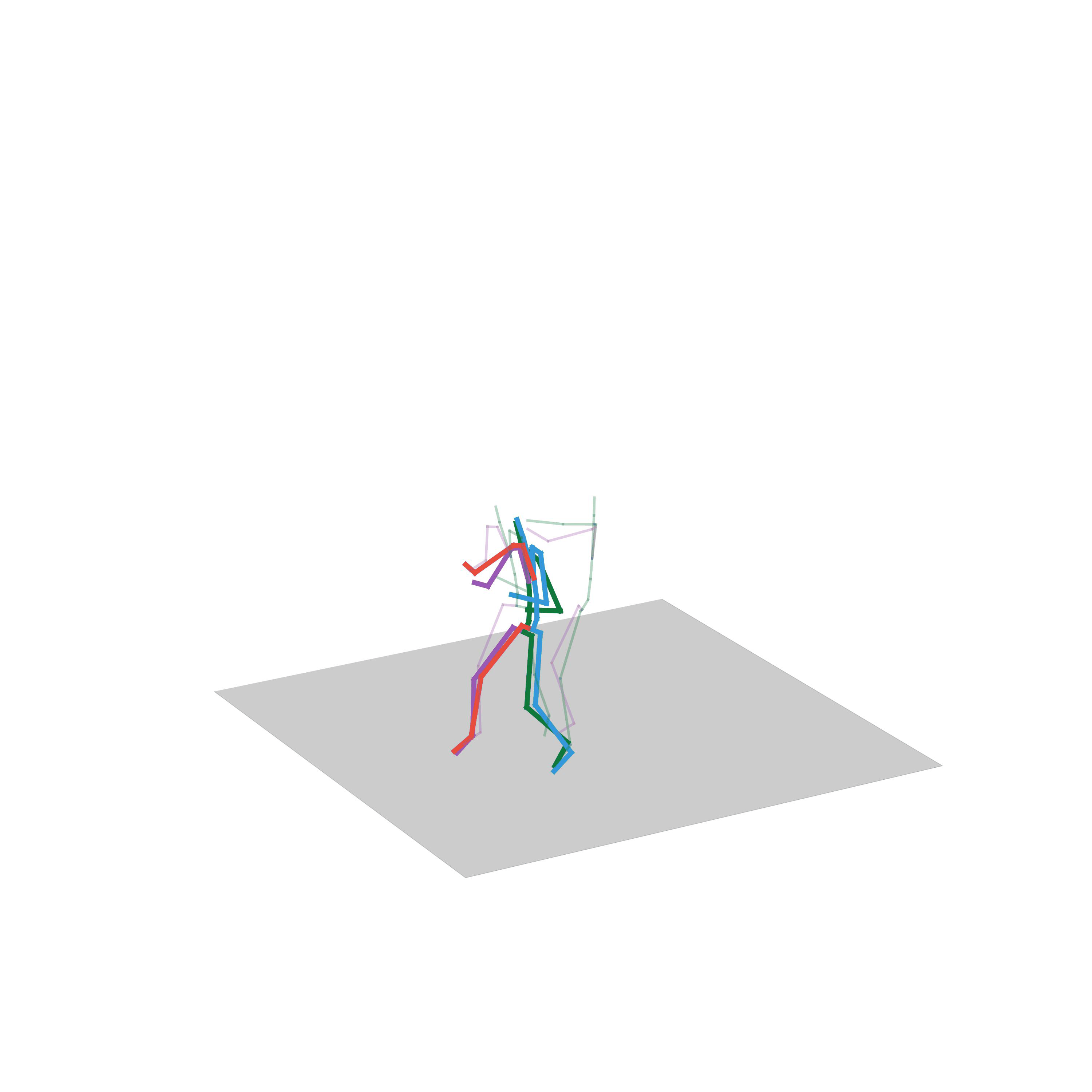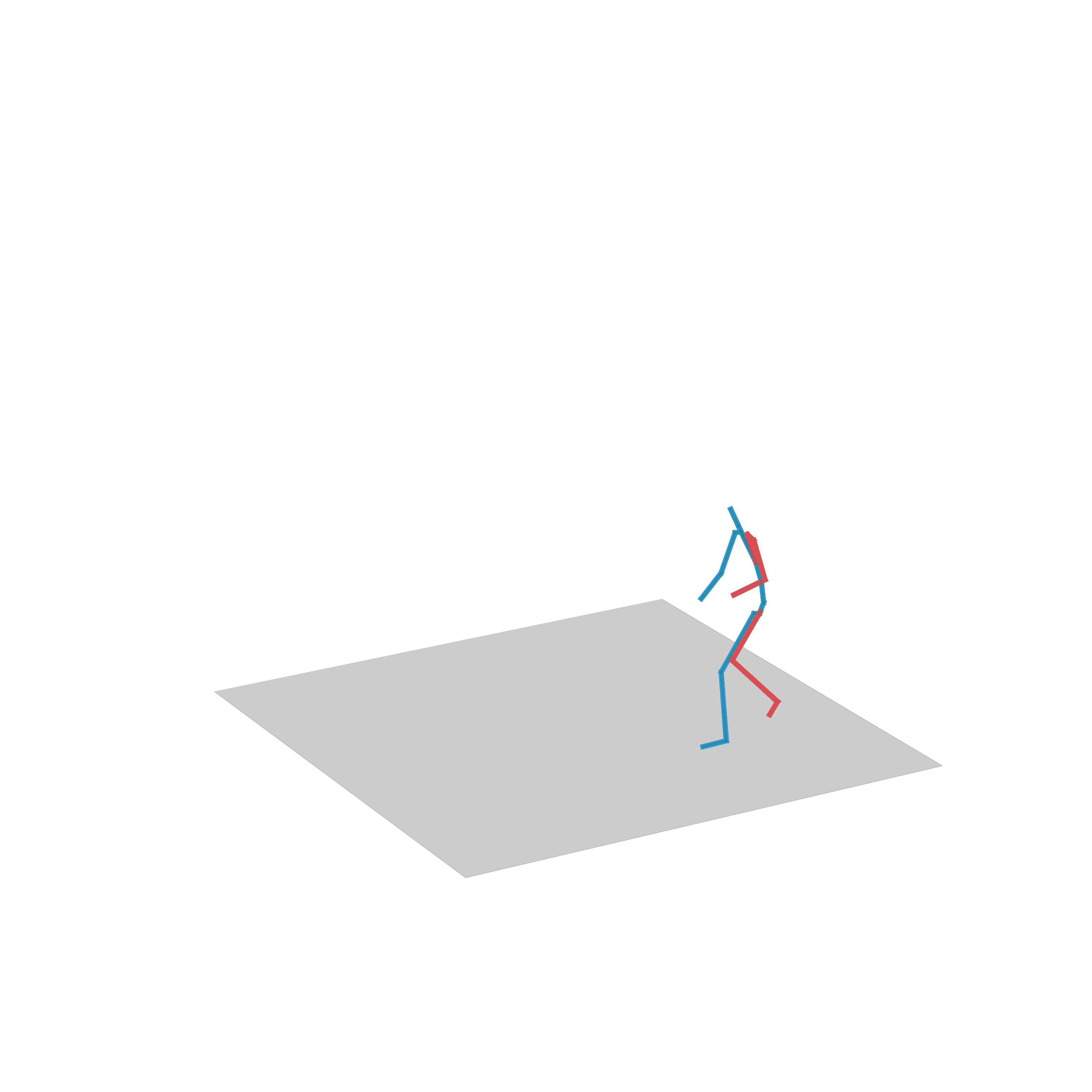
“Beting pushed”
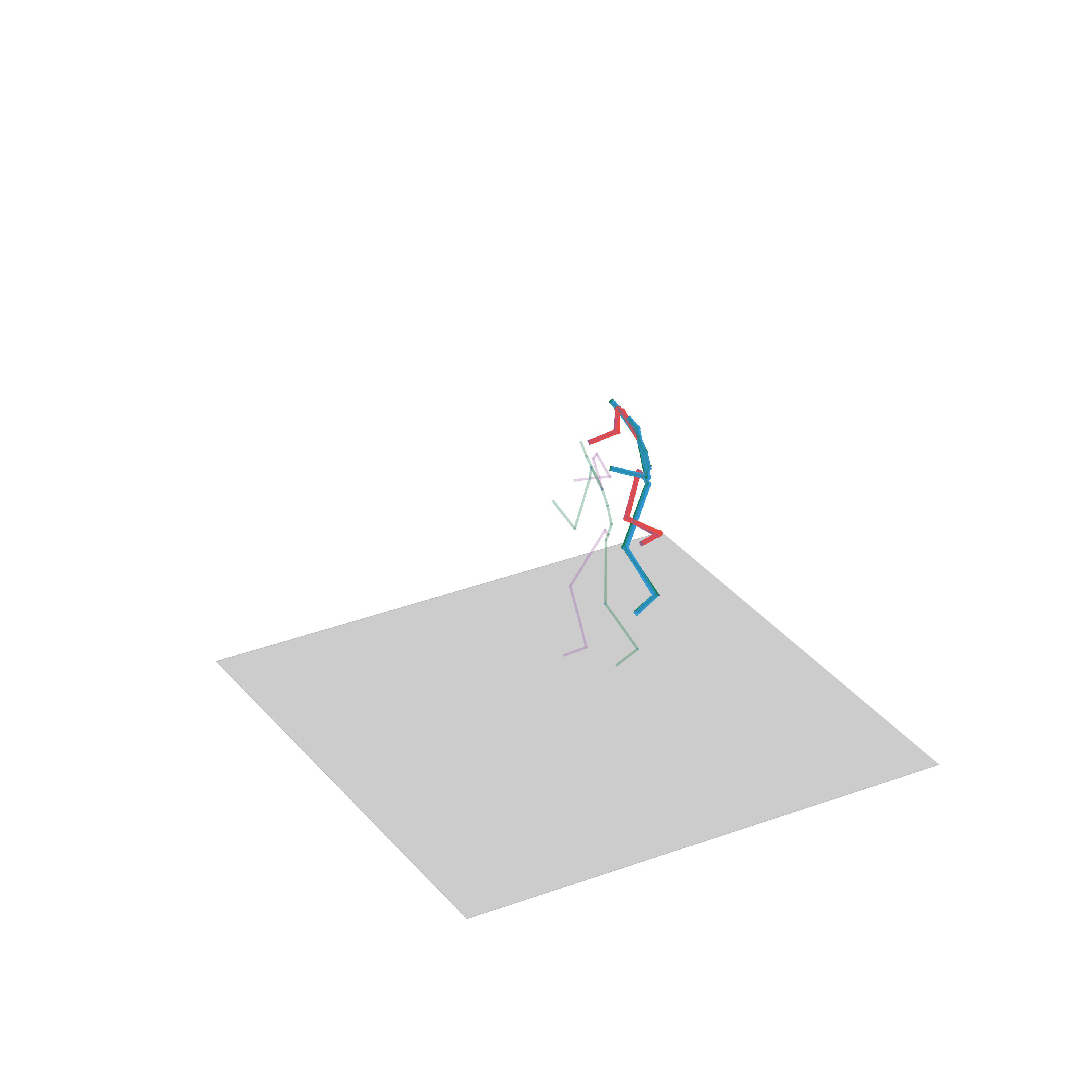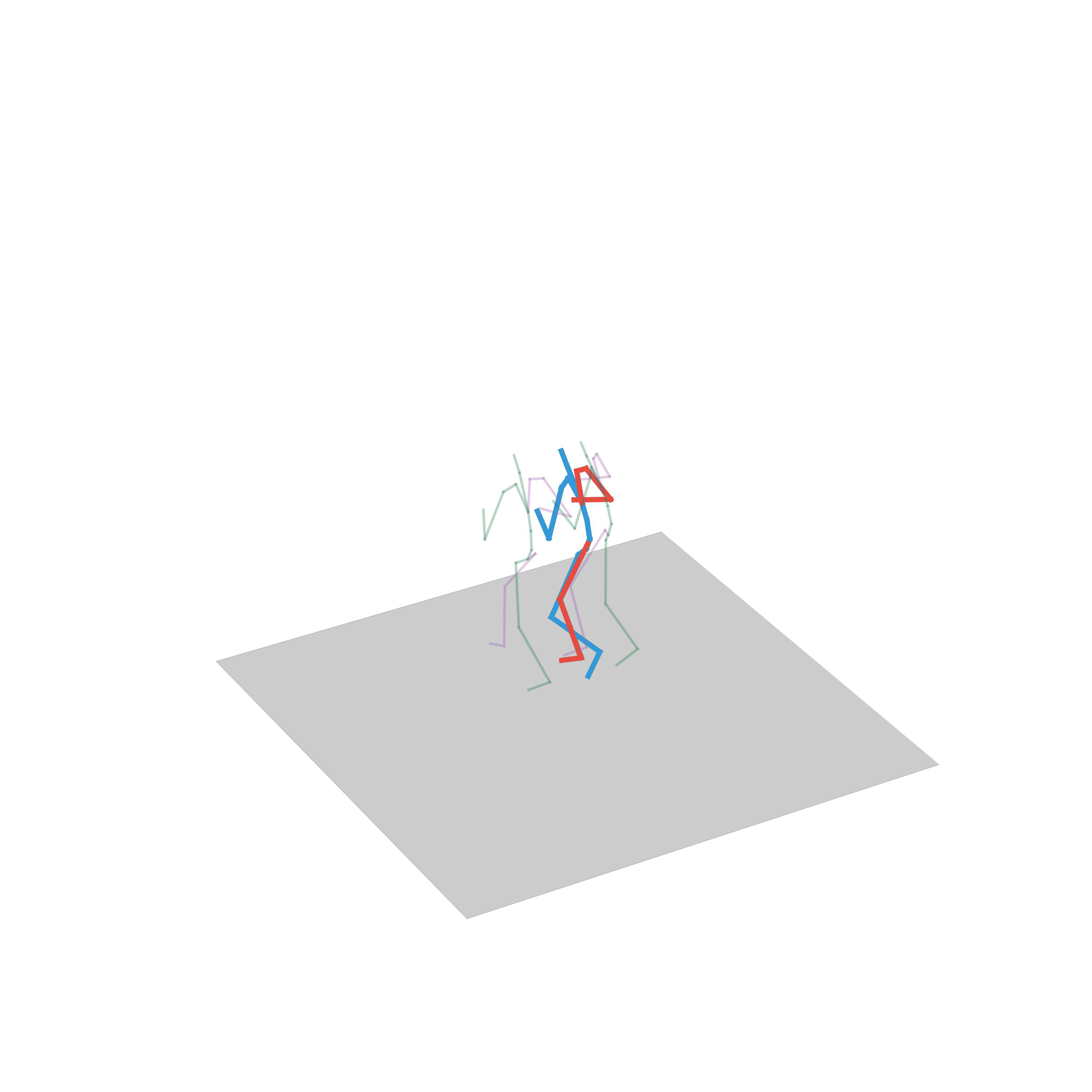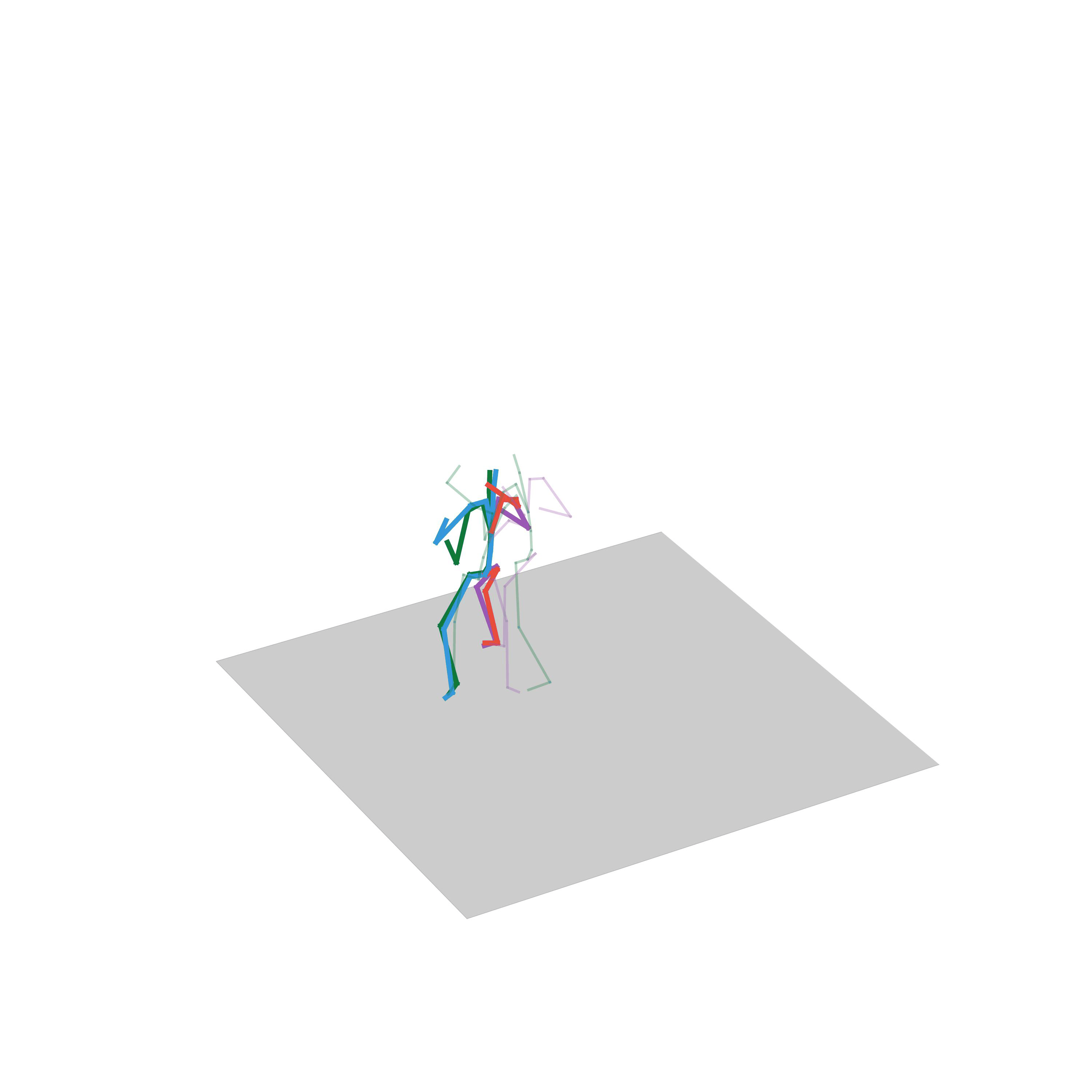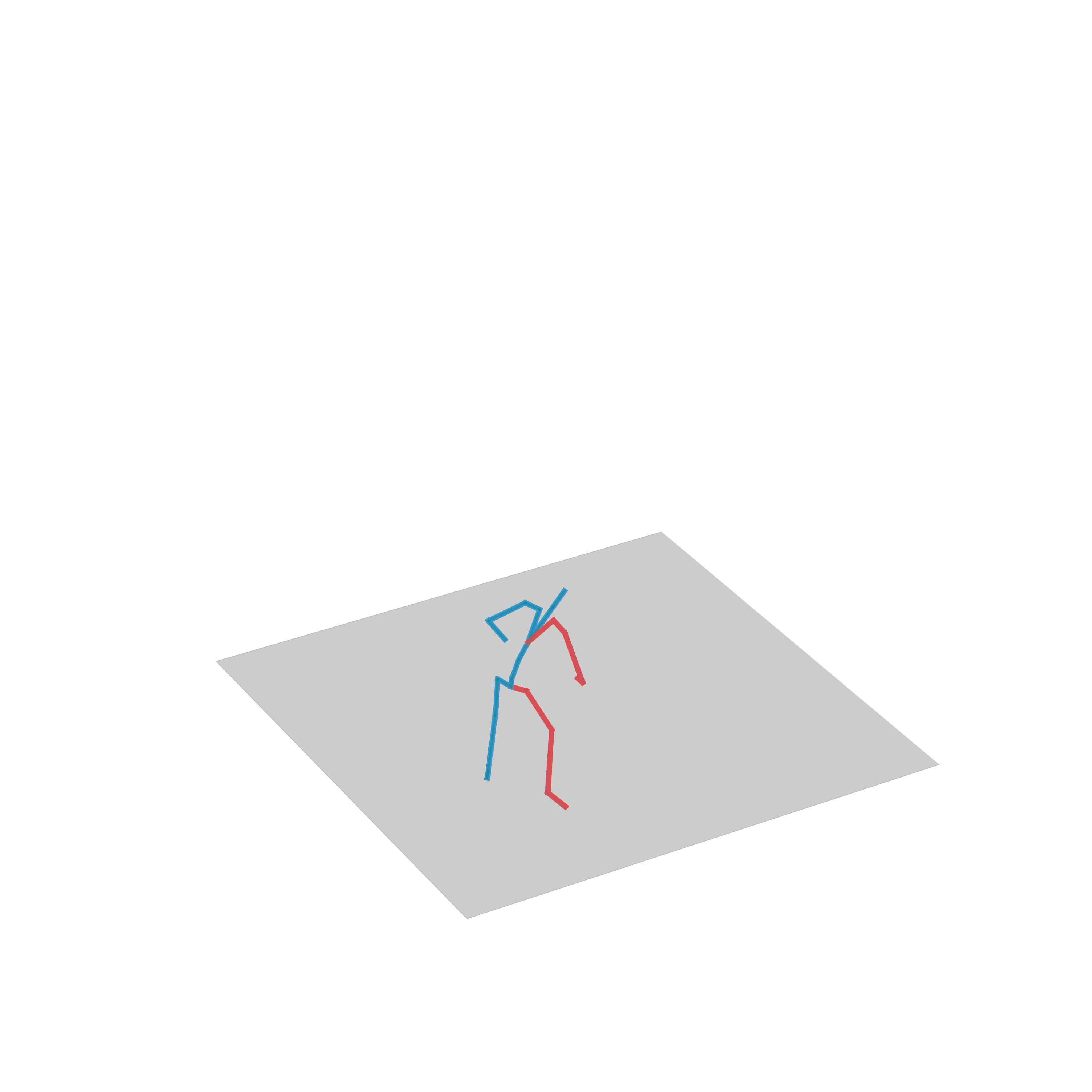
“Crawling”
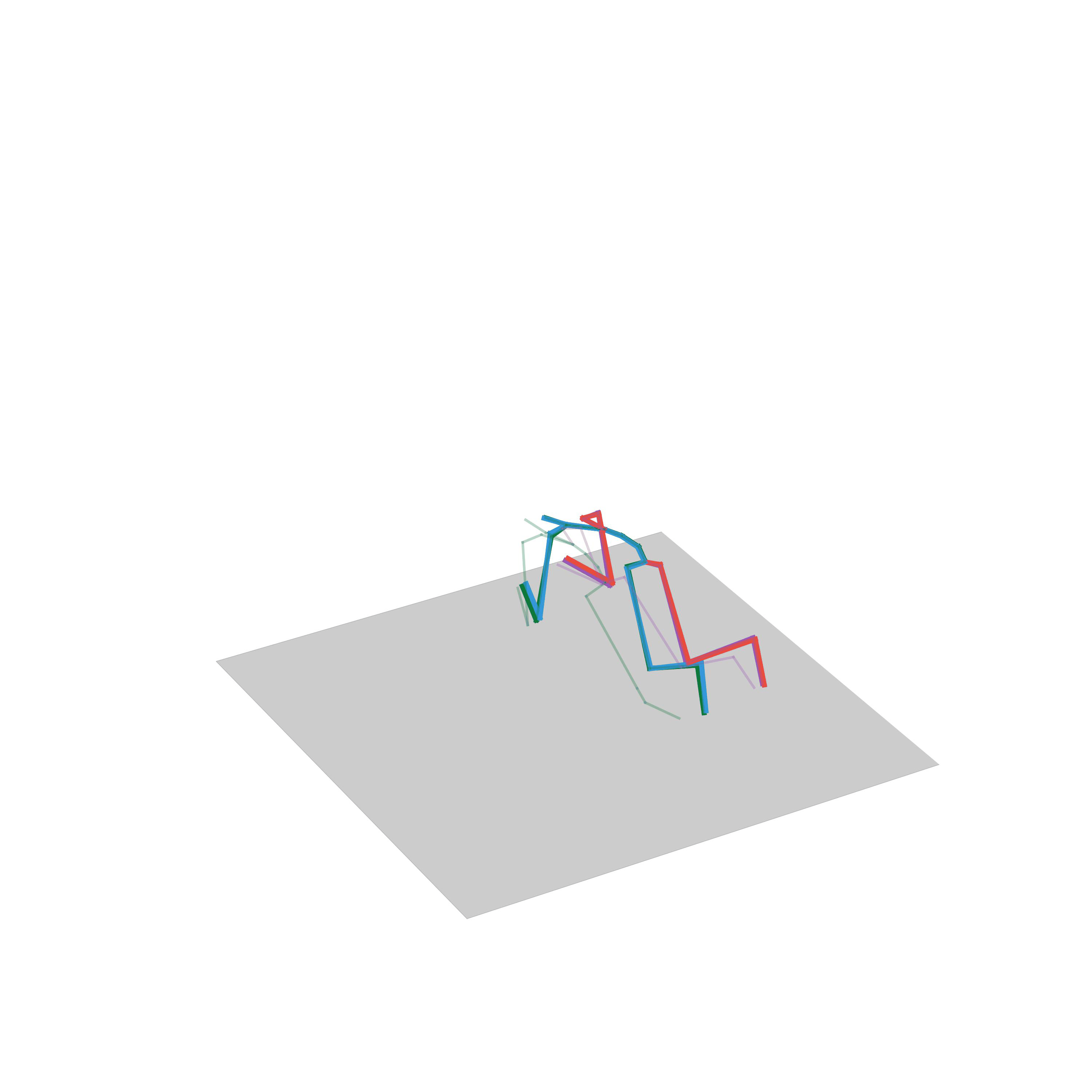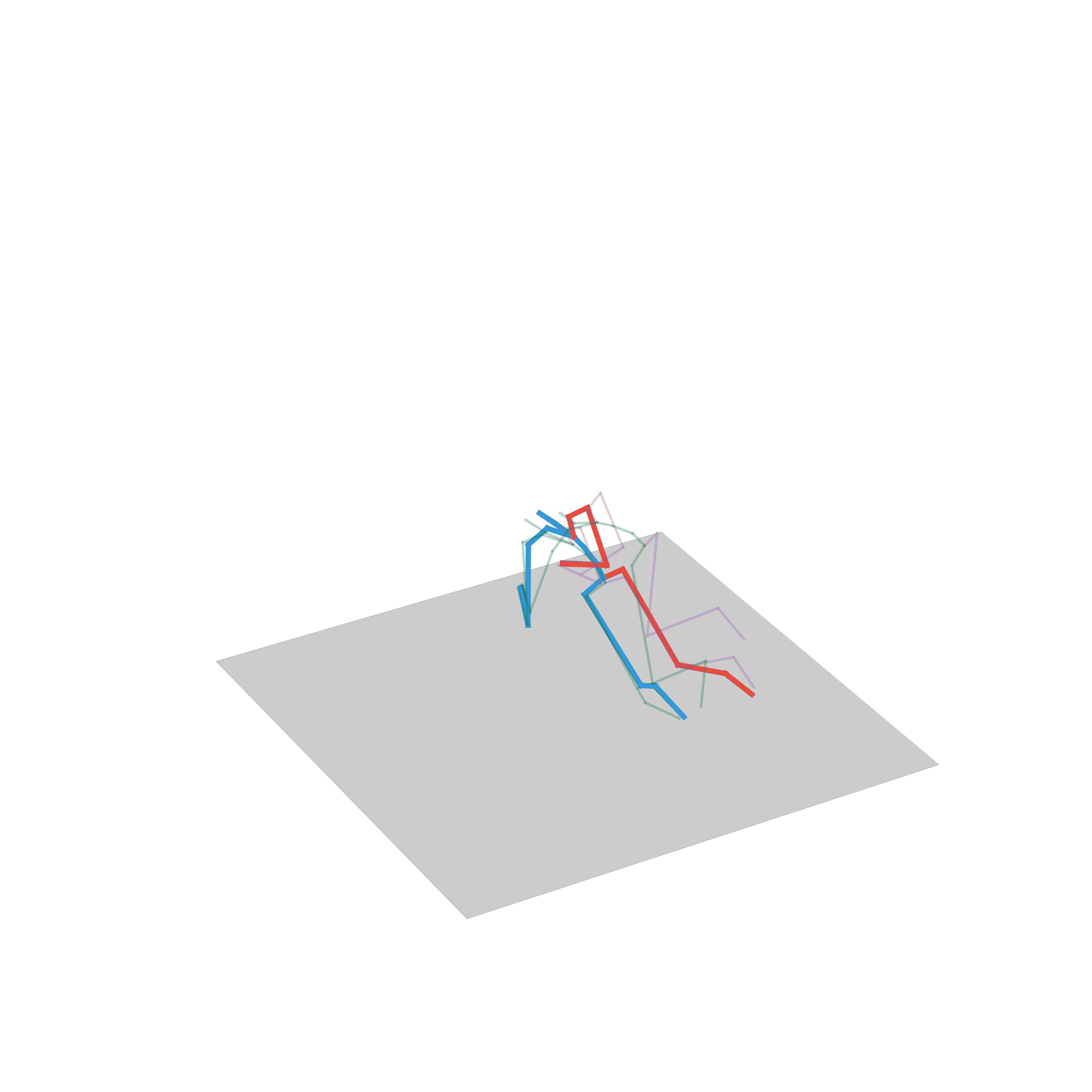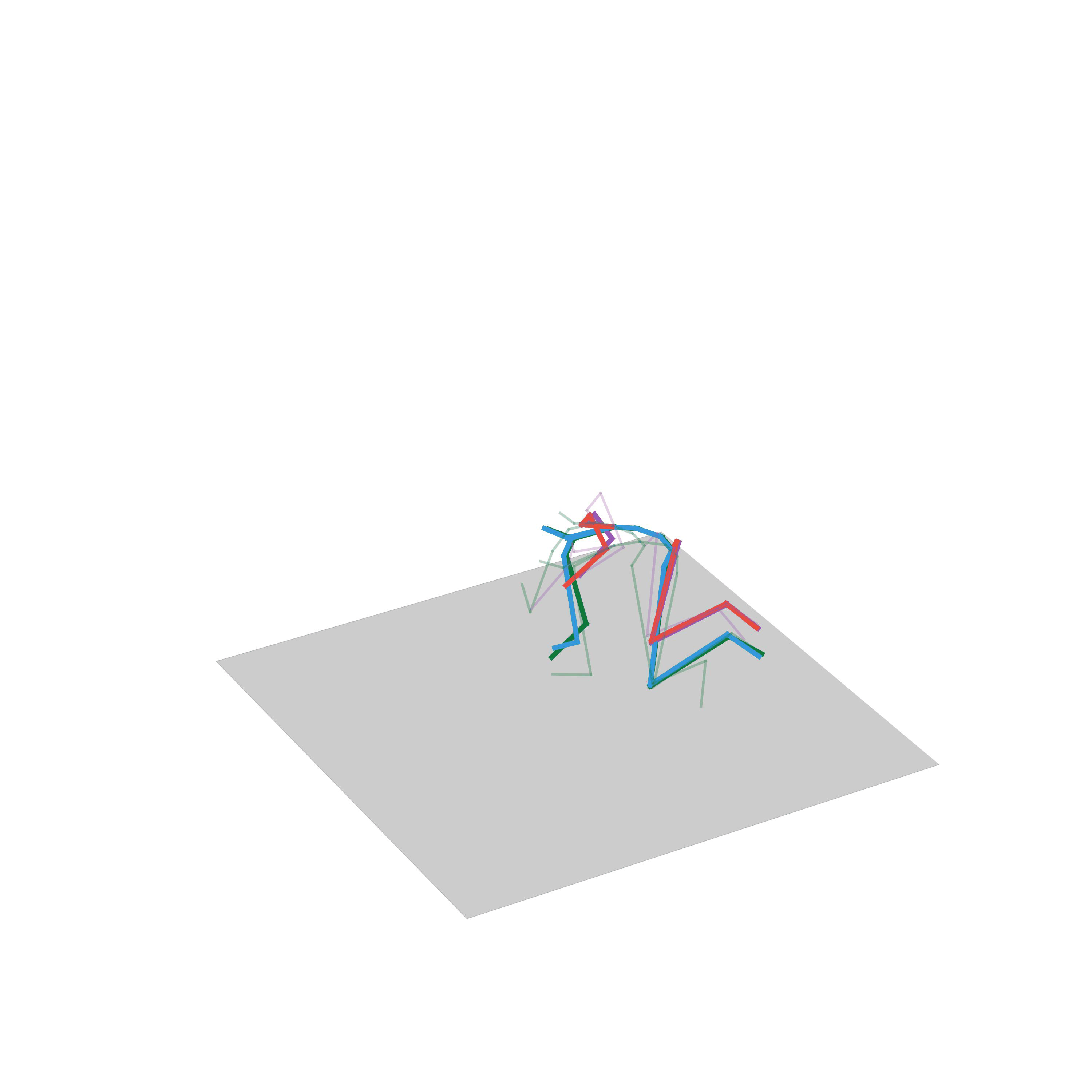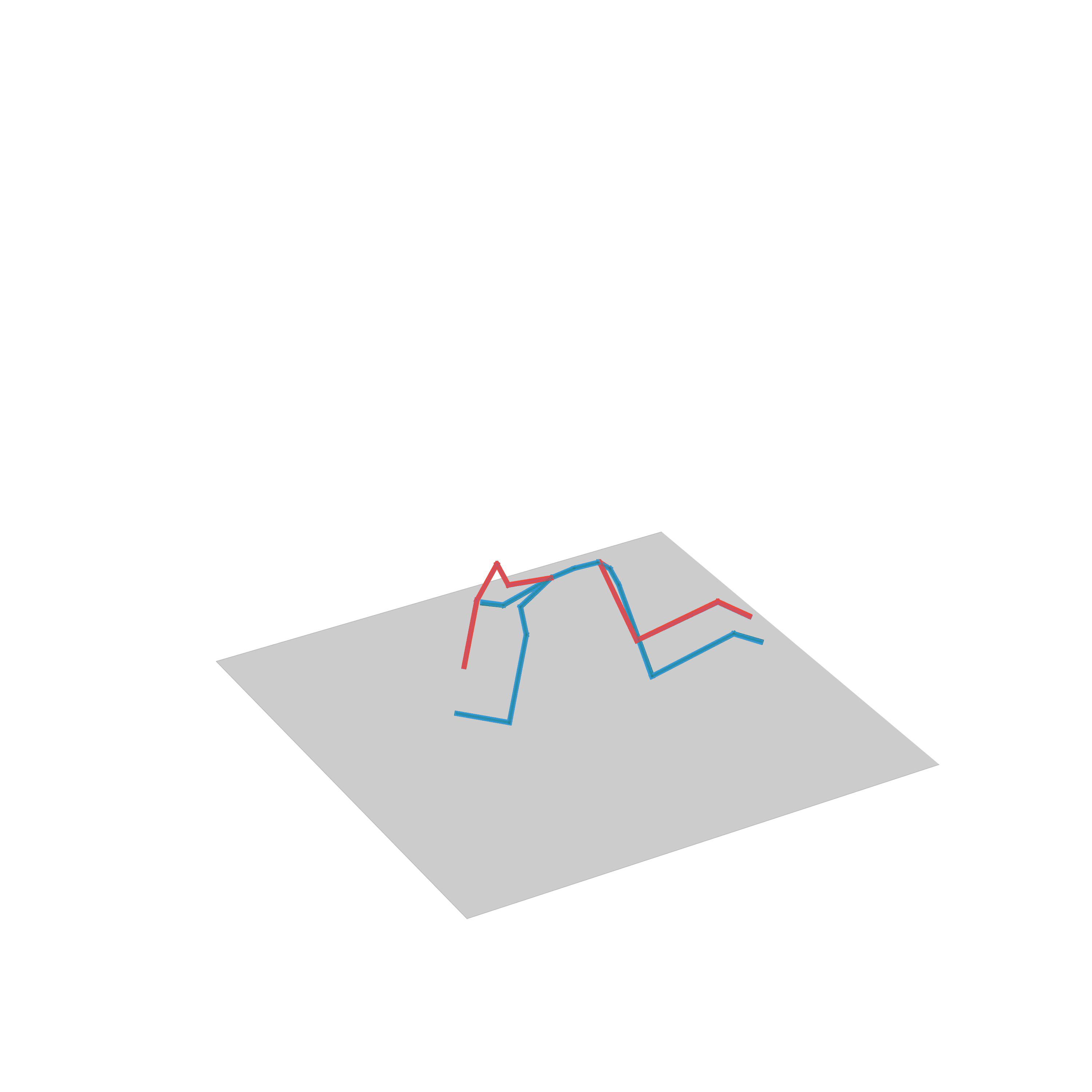
“Walking and then turning”
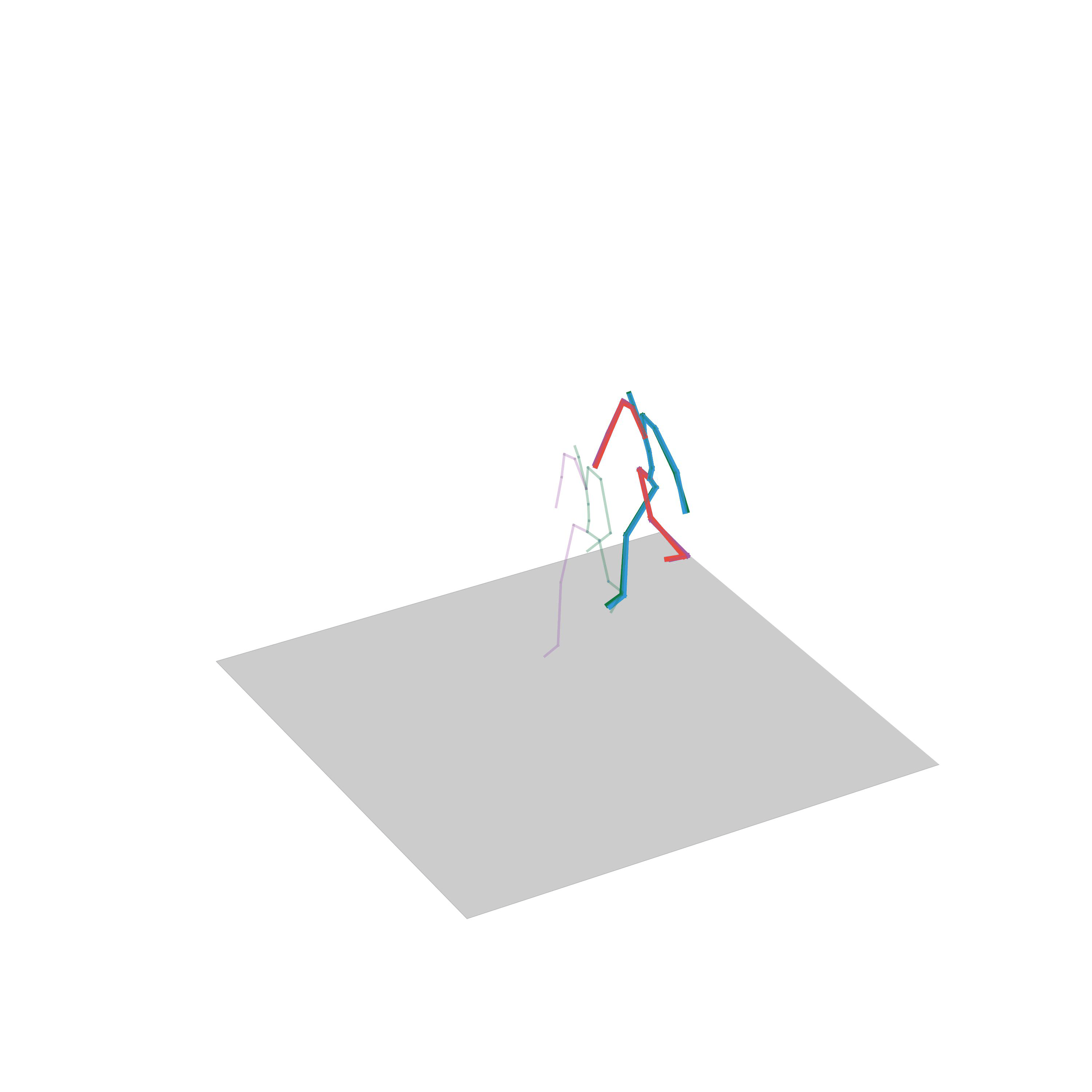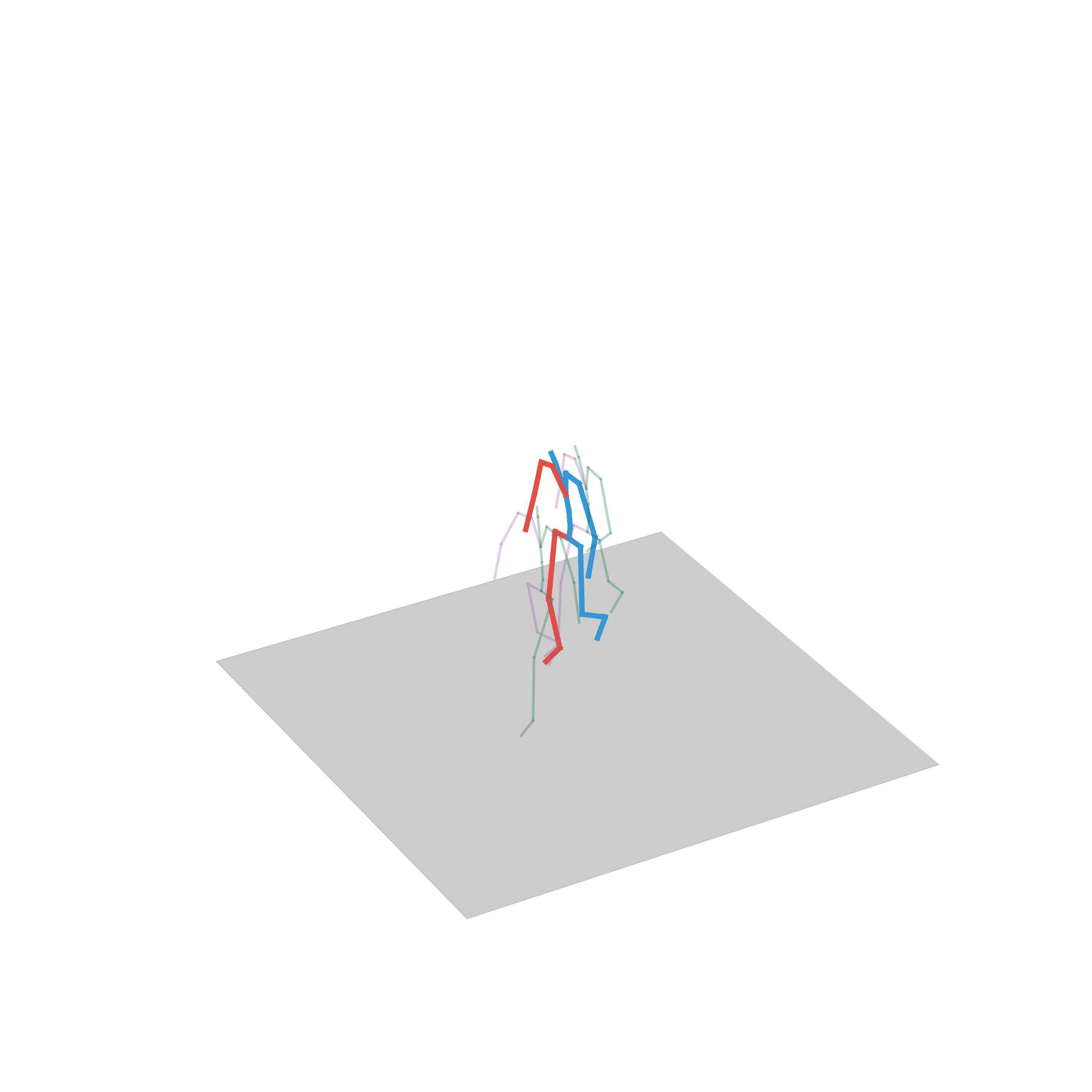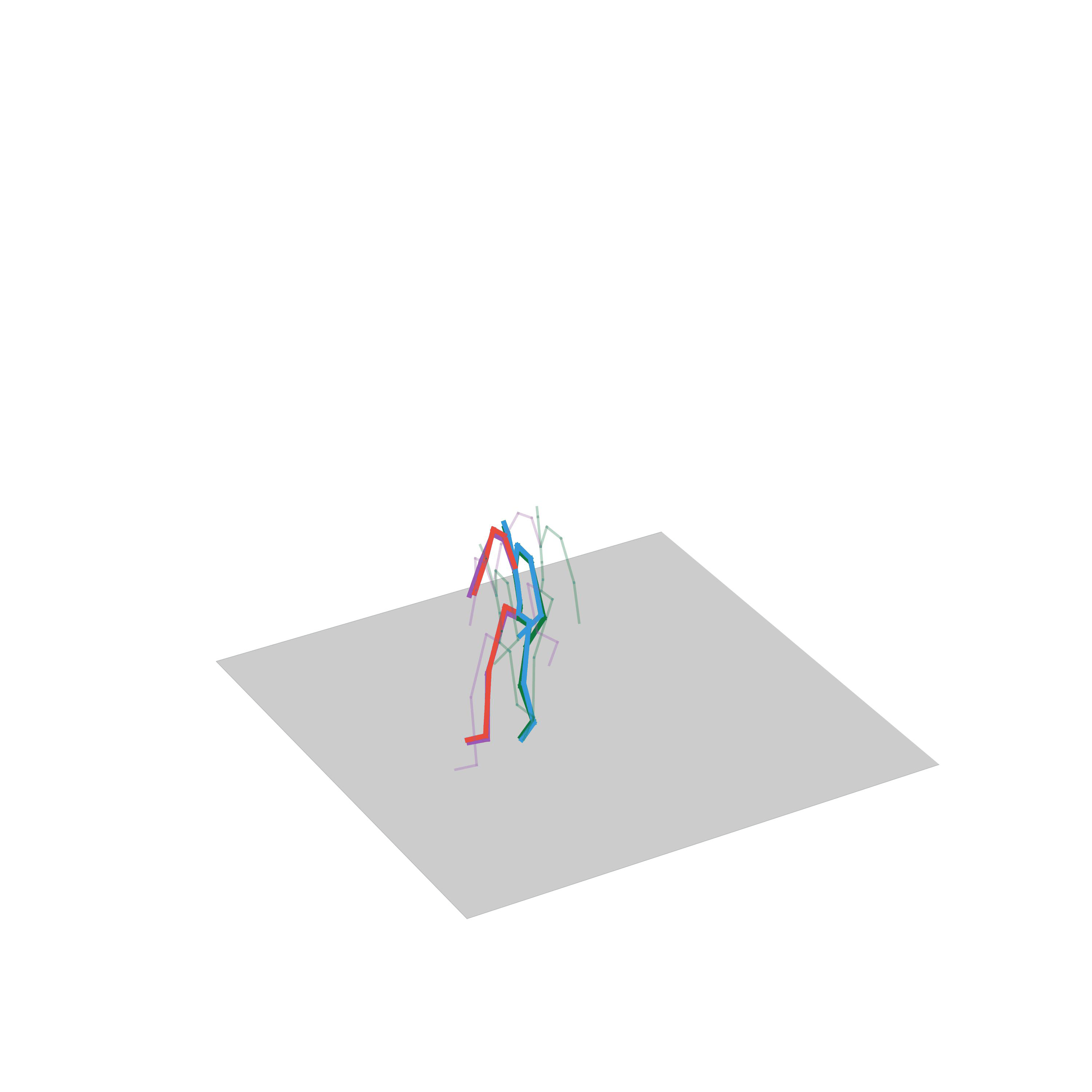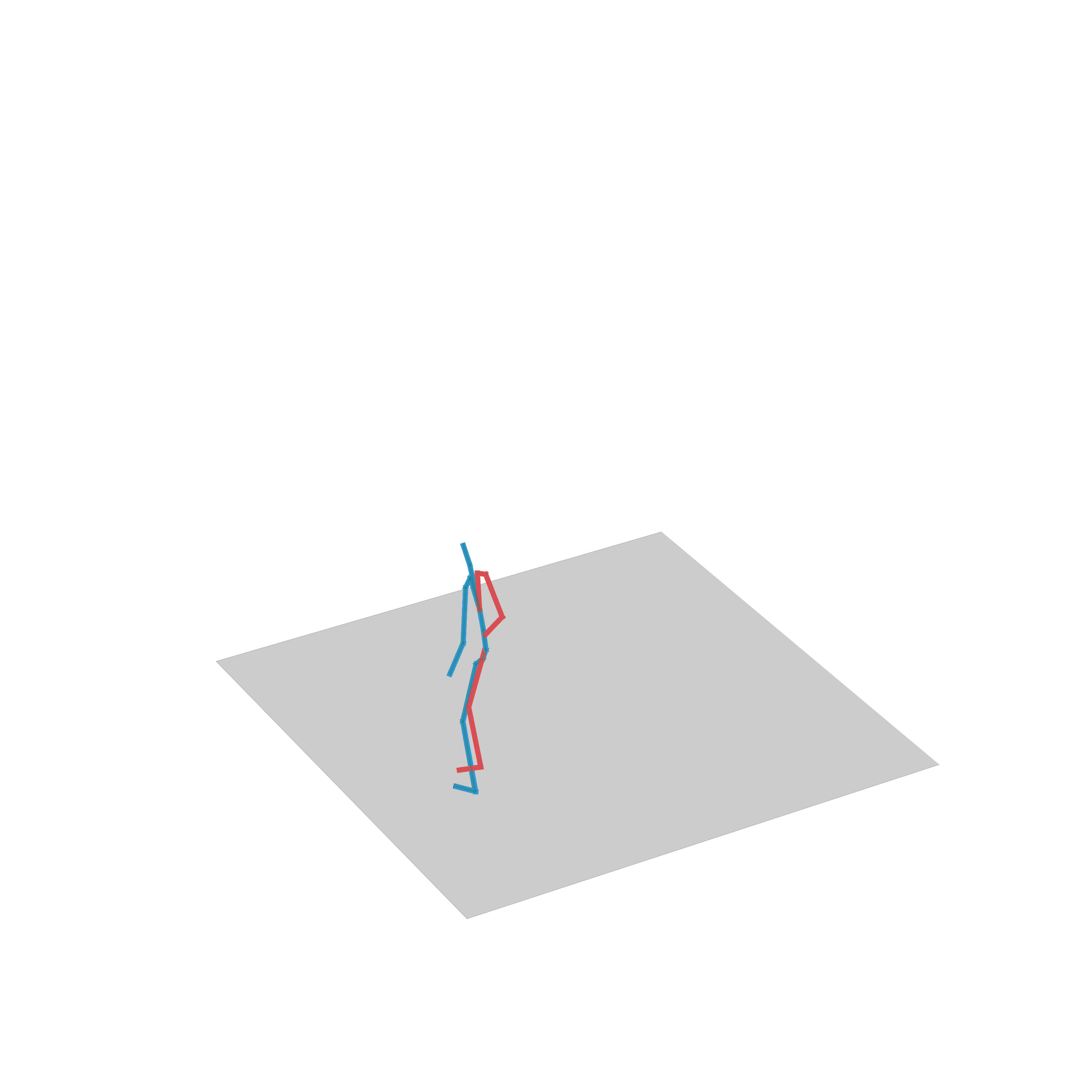
“Dancing freely”
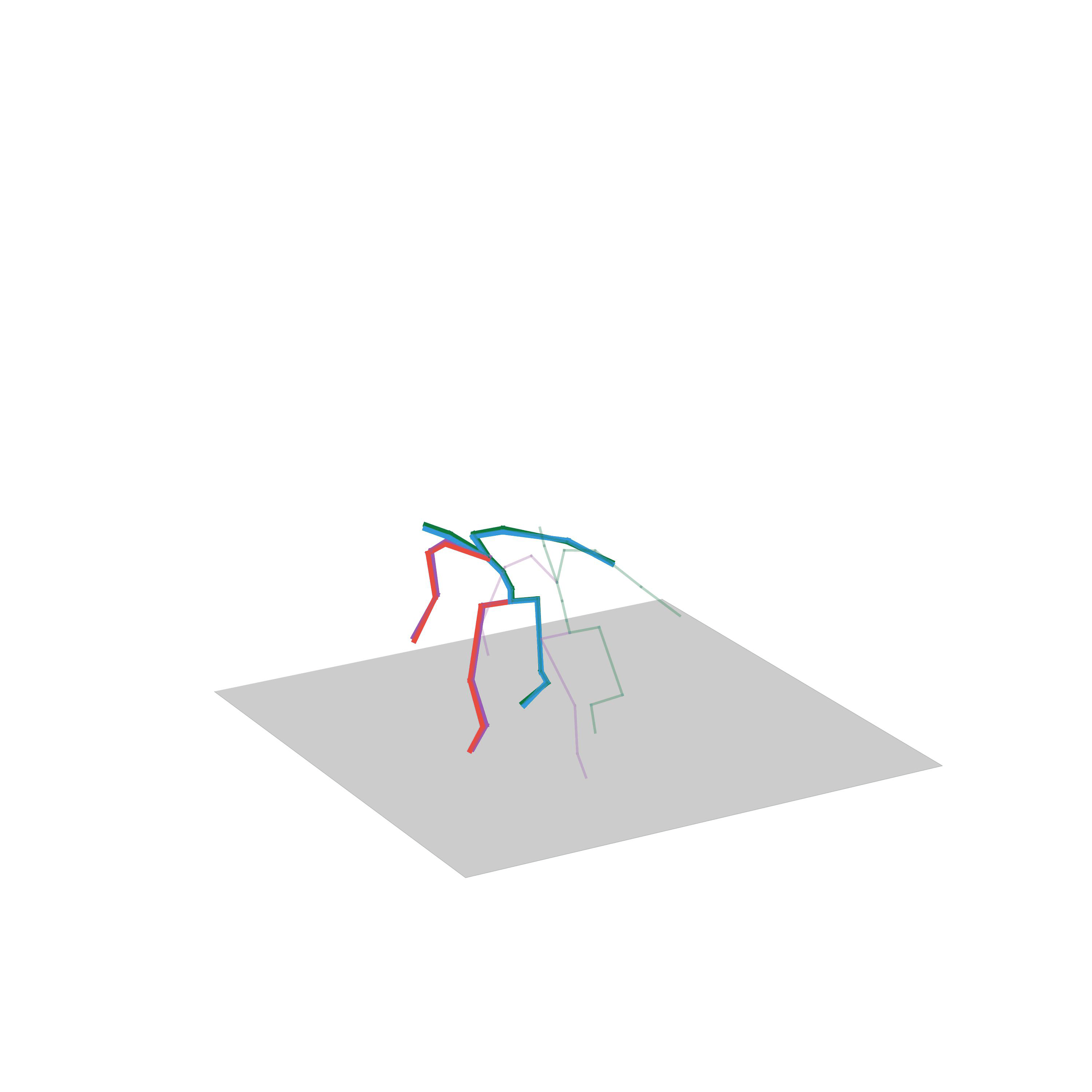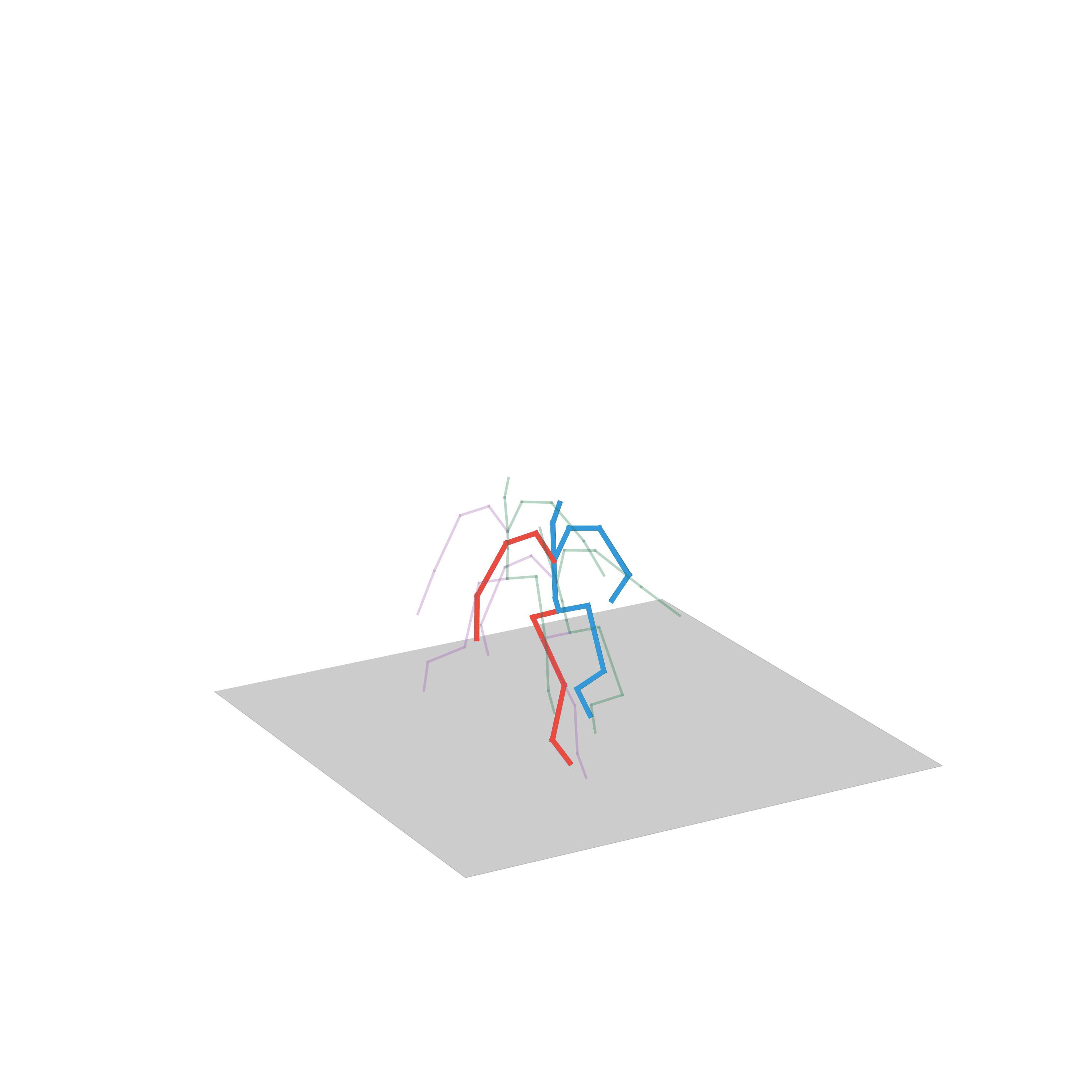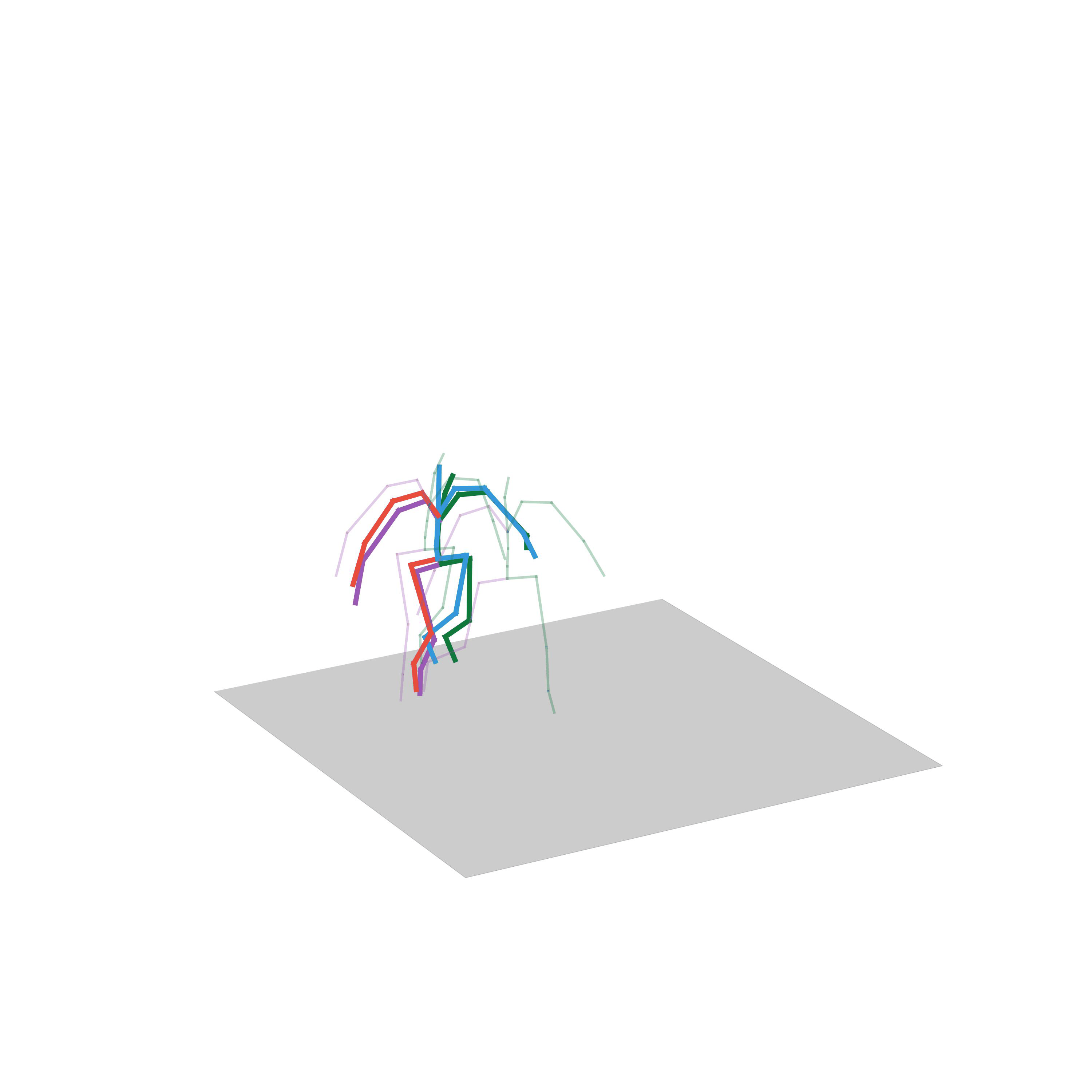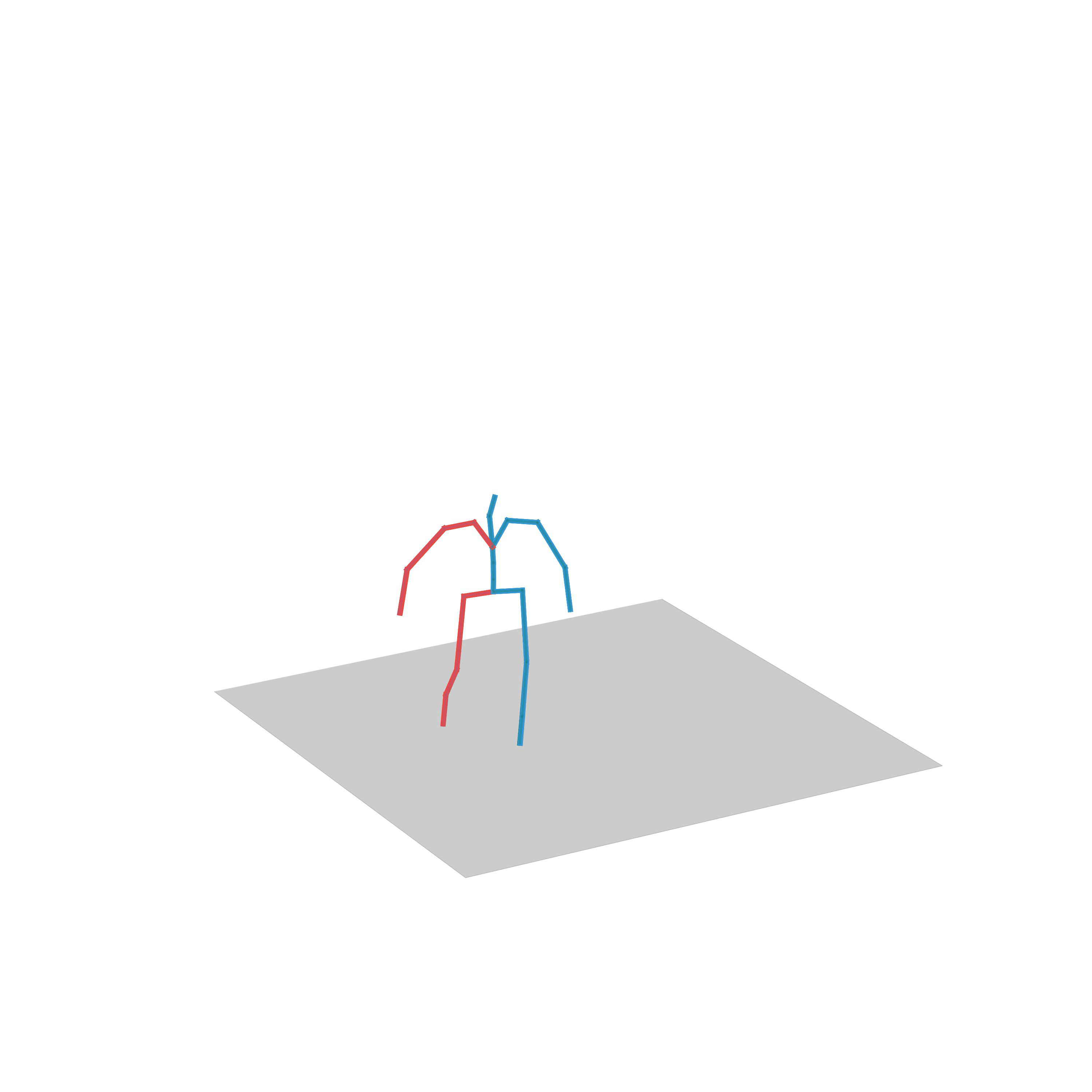
“Fighting”

“Crawling”
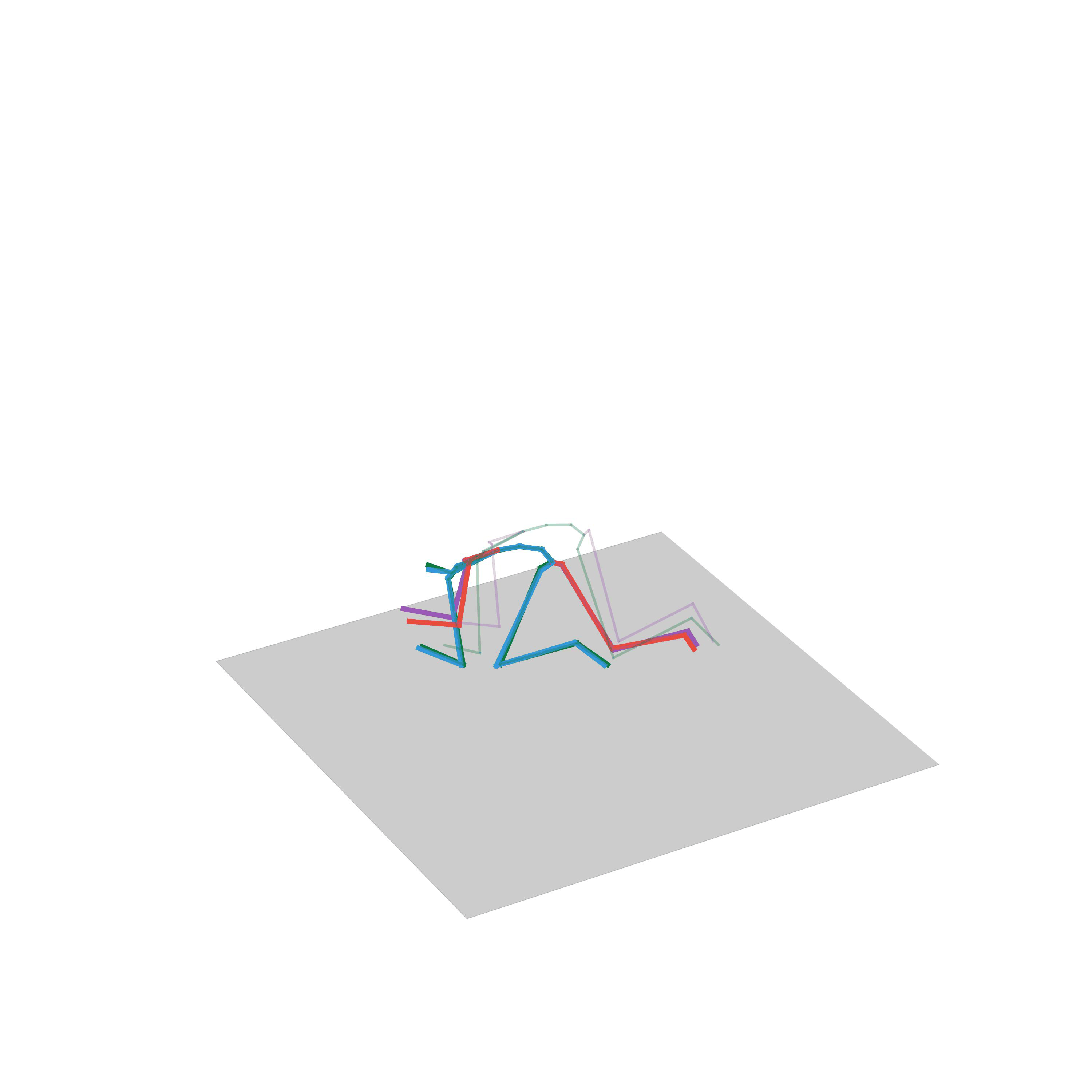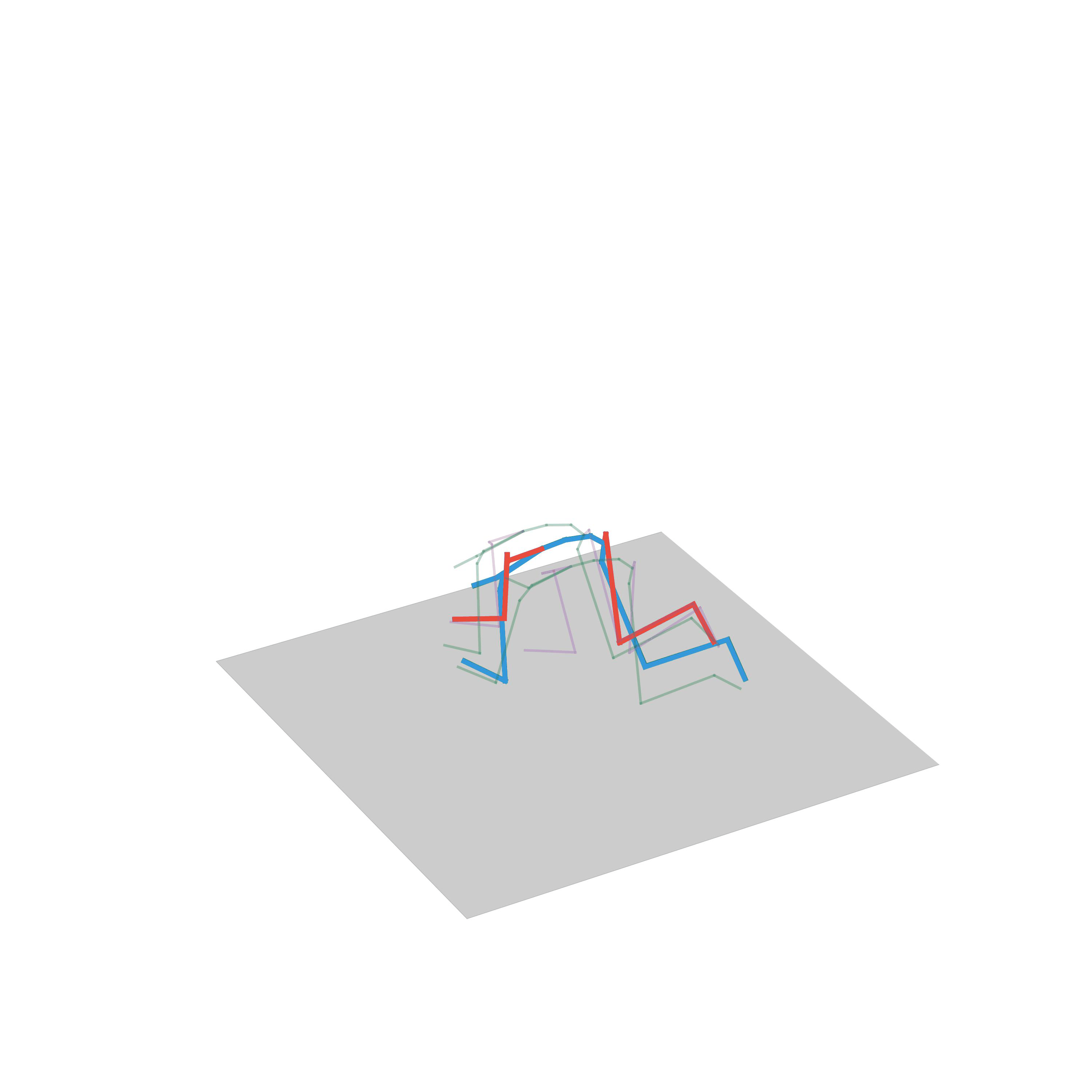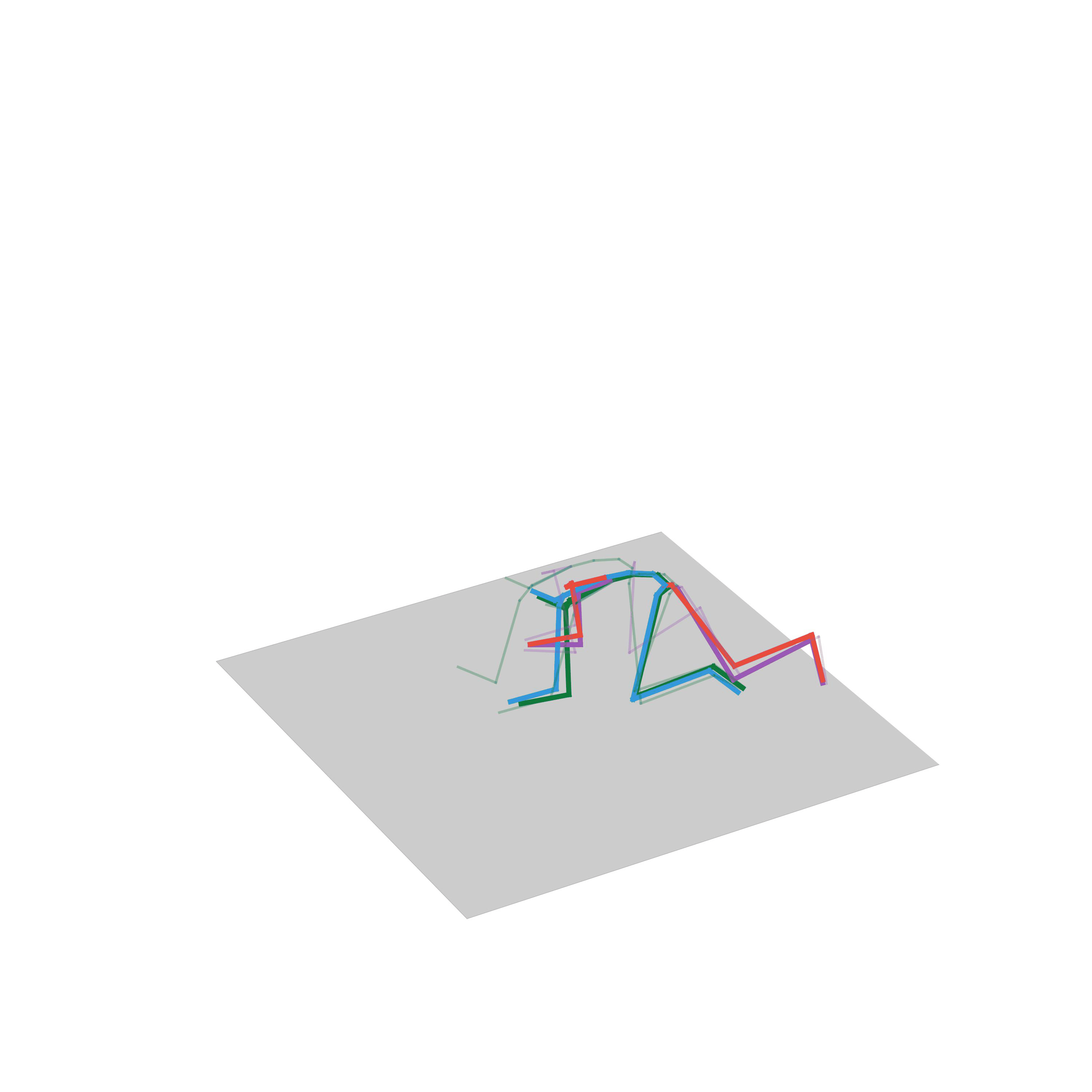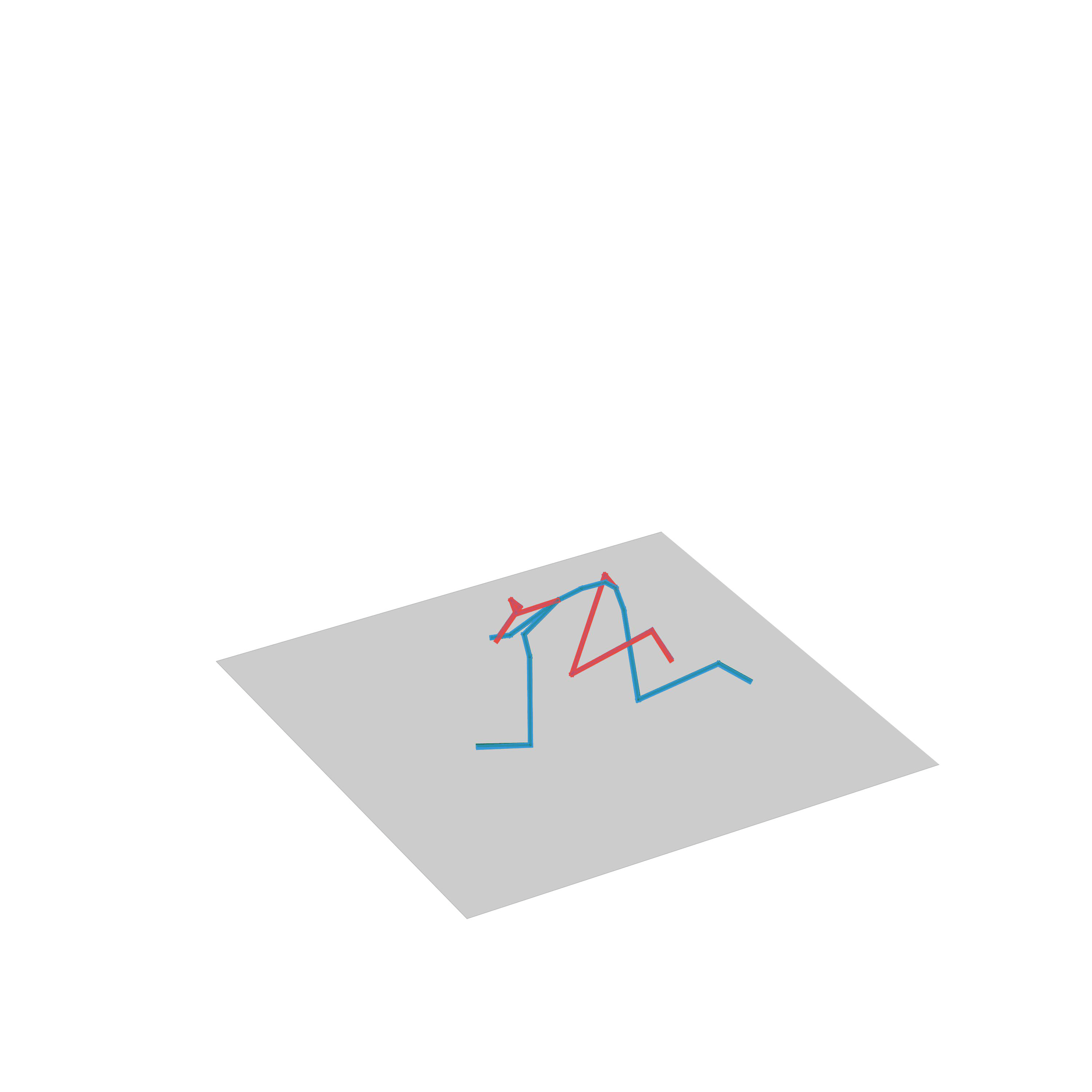
Human Motion Forecasting
In this task, the aim is to predict future human motion based only on past observations. We evaluate our UNIMASK-M model for motion forecasting in the Human3.6M dataset and demonstrate that our model obtains competitive results to the current state-of-the-art, while still being able to outperform in different motion synthesis tasks, such as motion completion or motion inbetweening.
“Sitting”
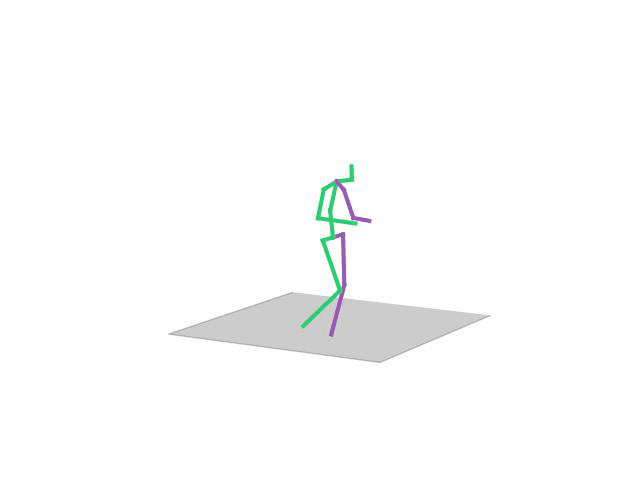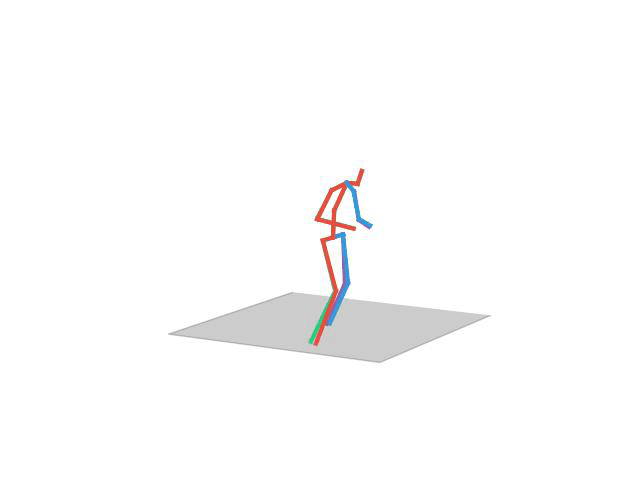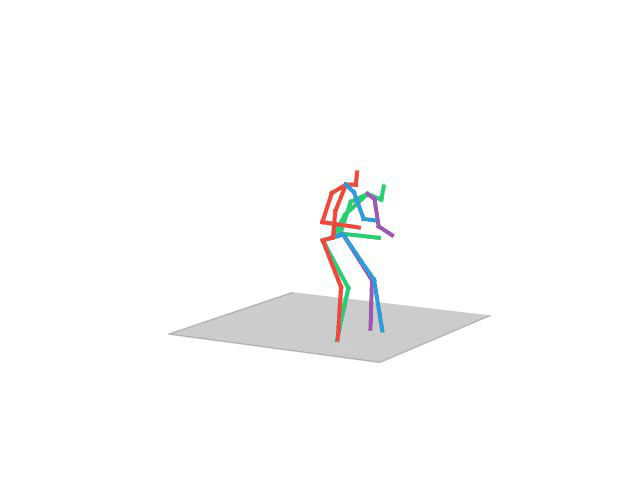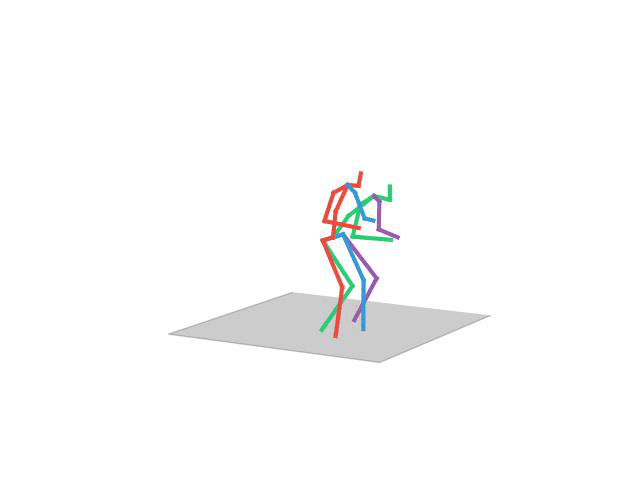
“Walking Together”
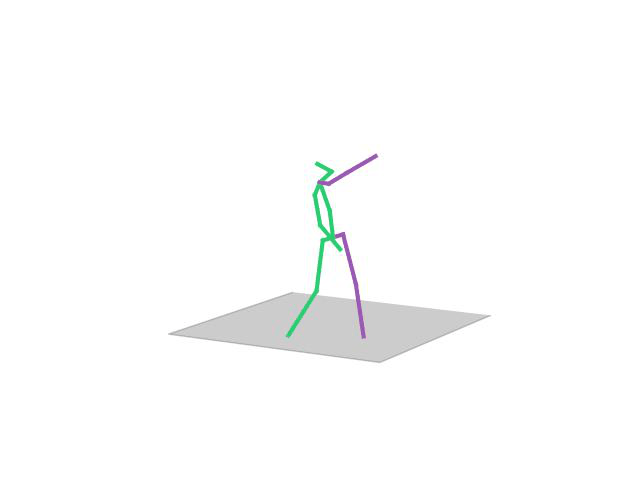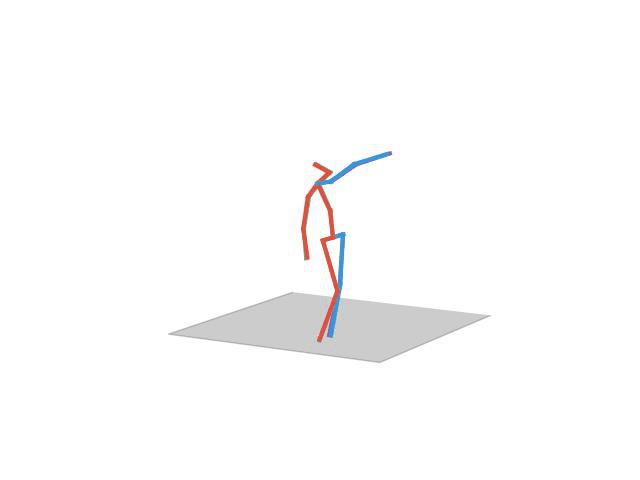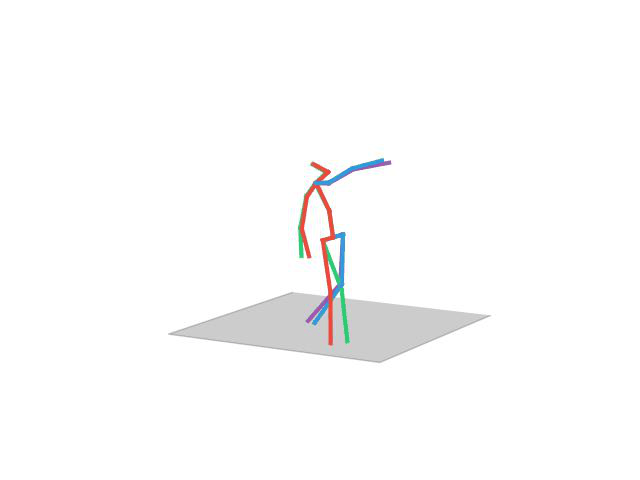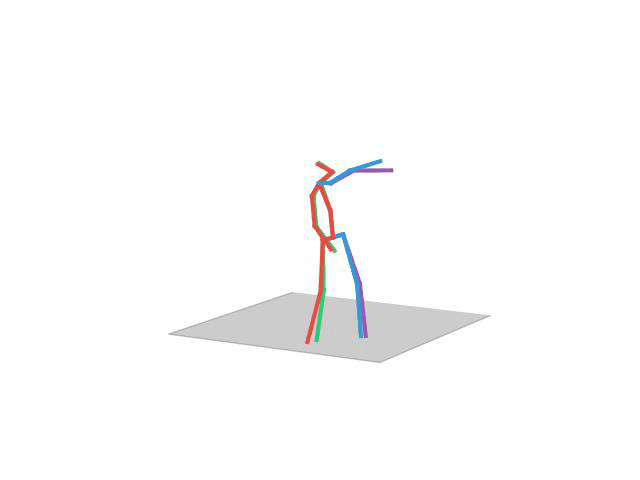
“Walking Dog1”
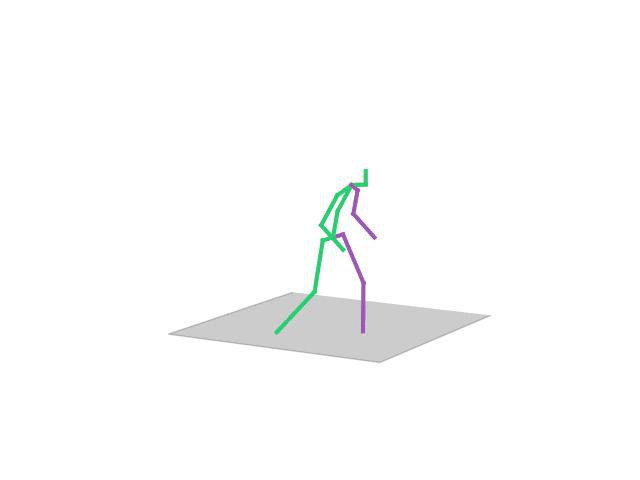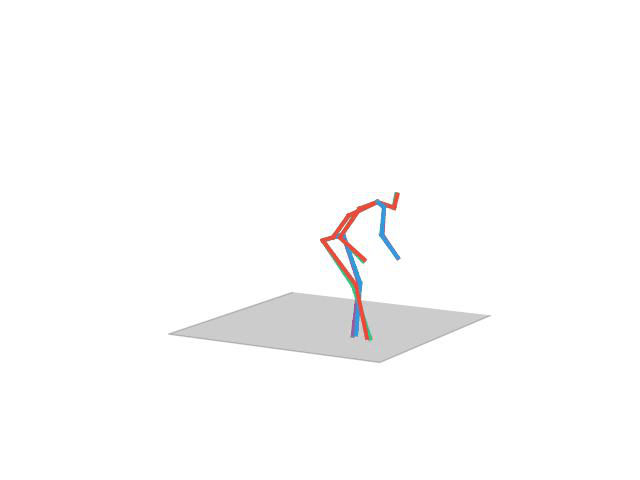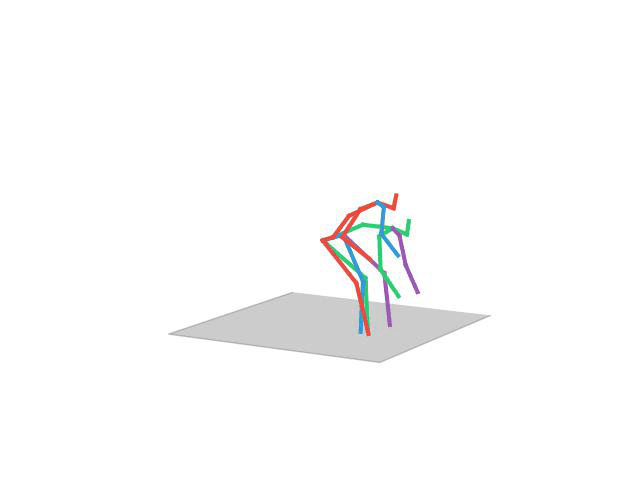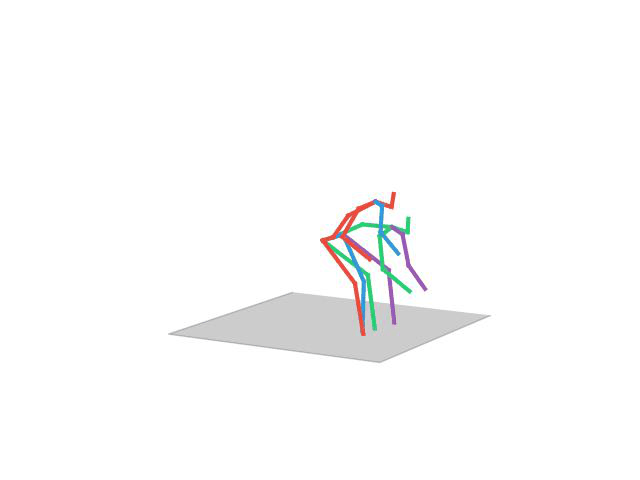
“Posing”
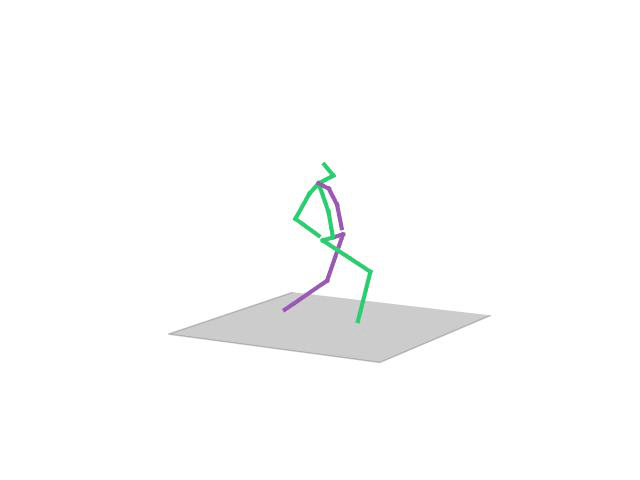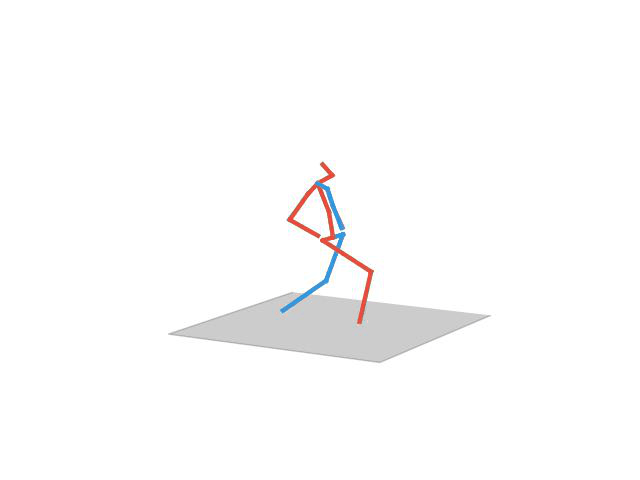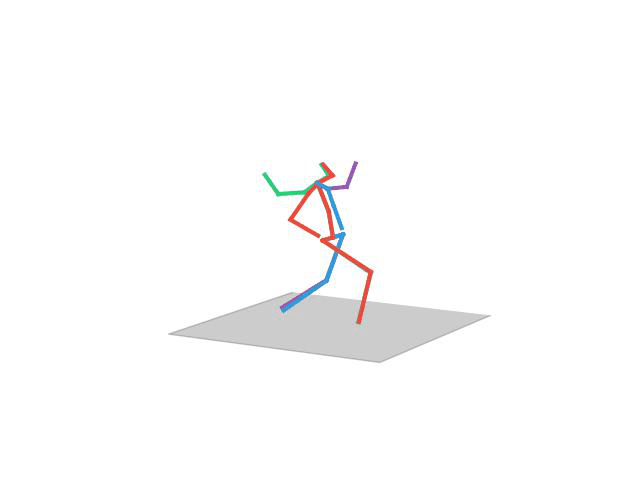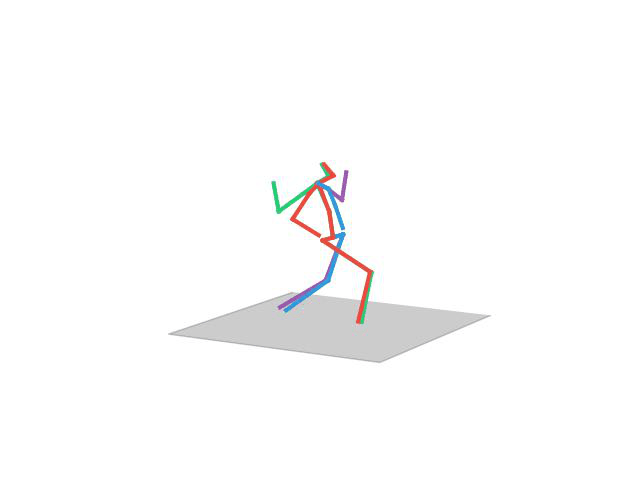
“Walking Dog”
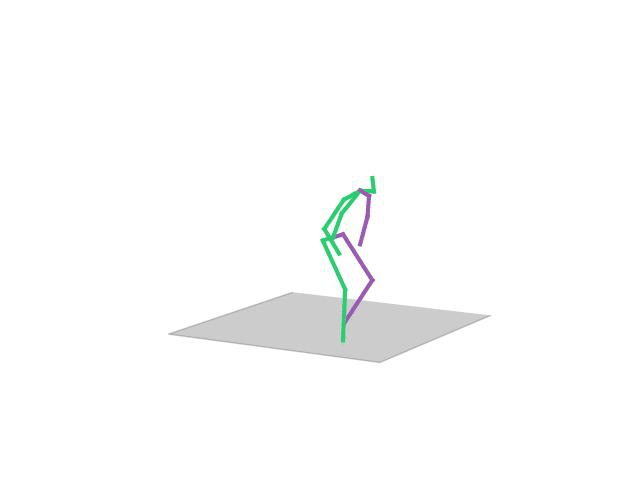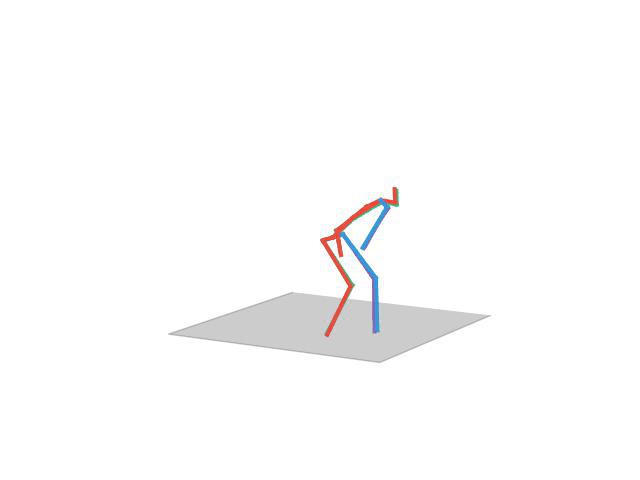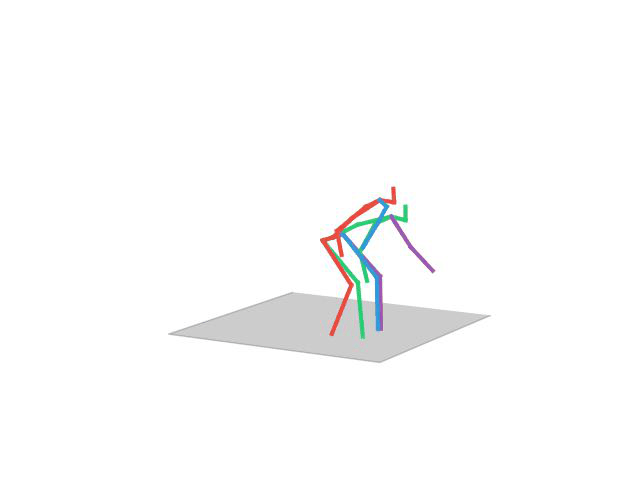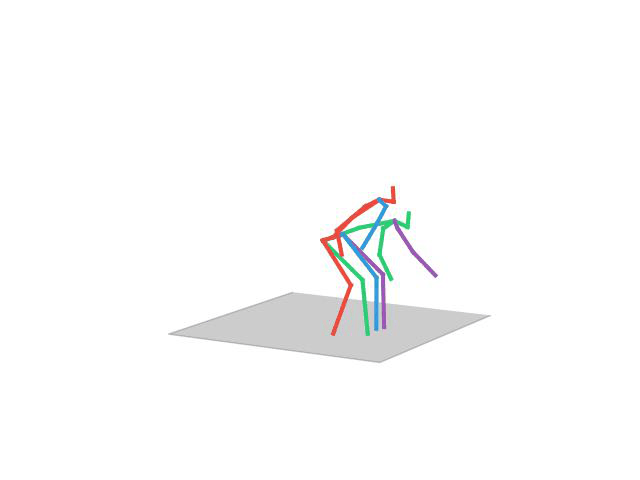
“Taking Photo”
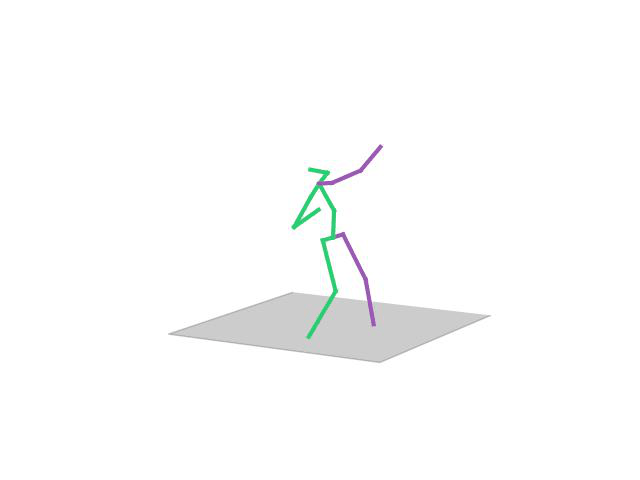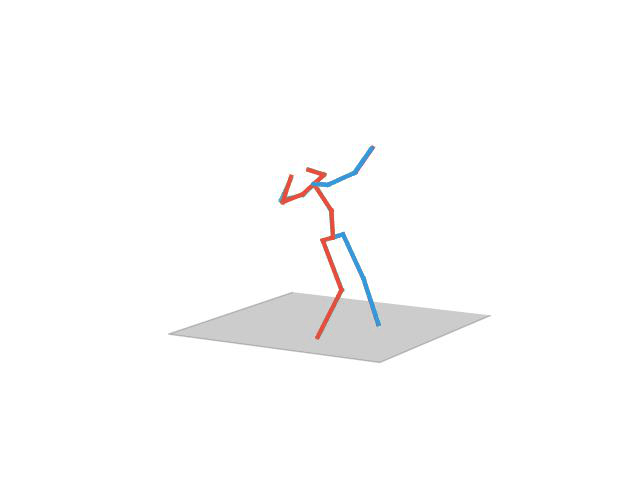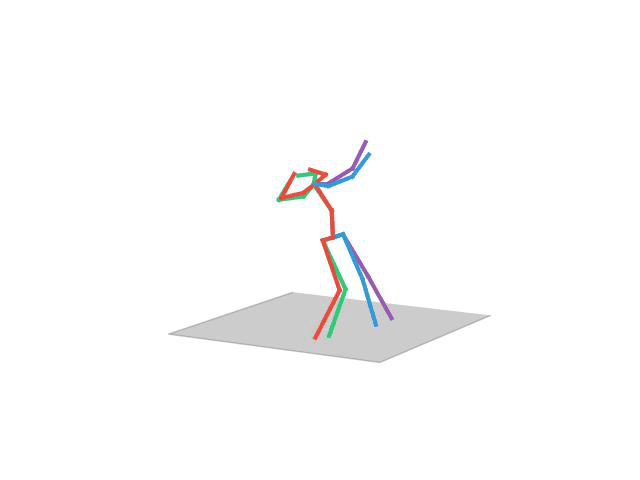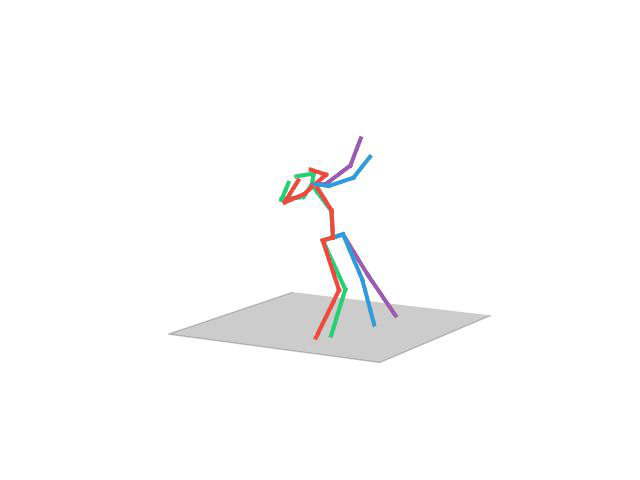
“Walking Dog”
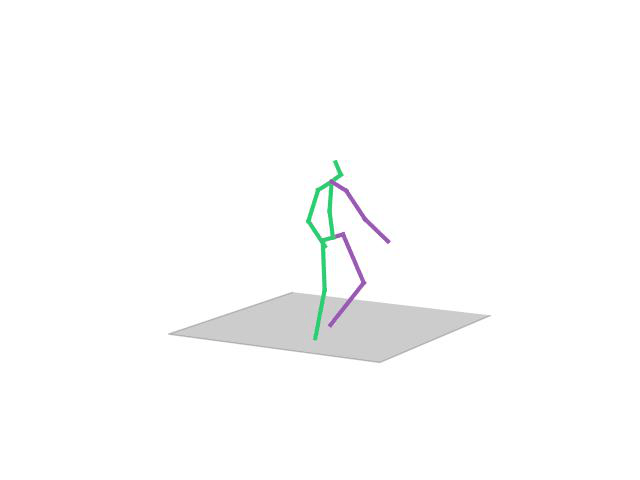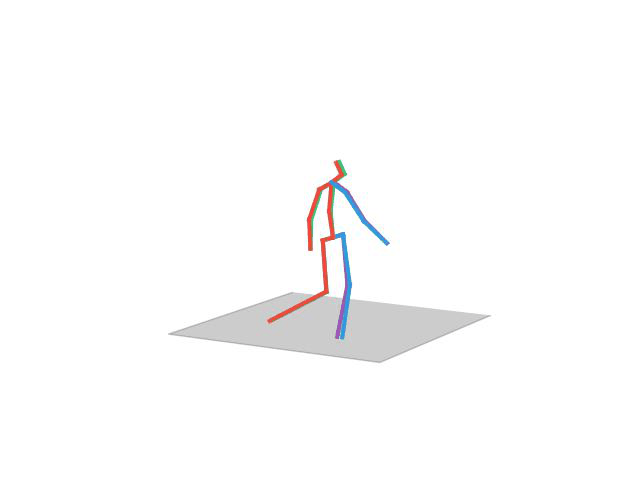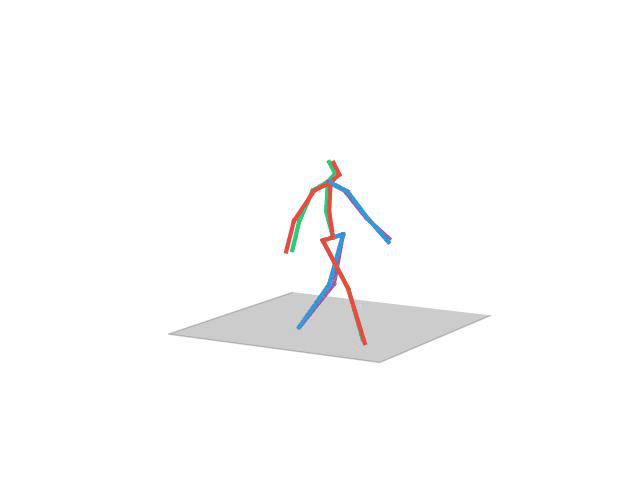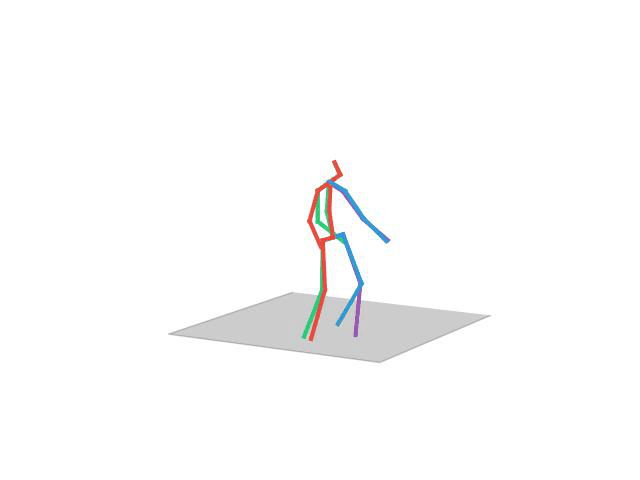
“Posing”
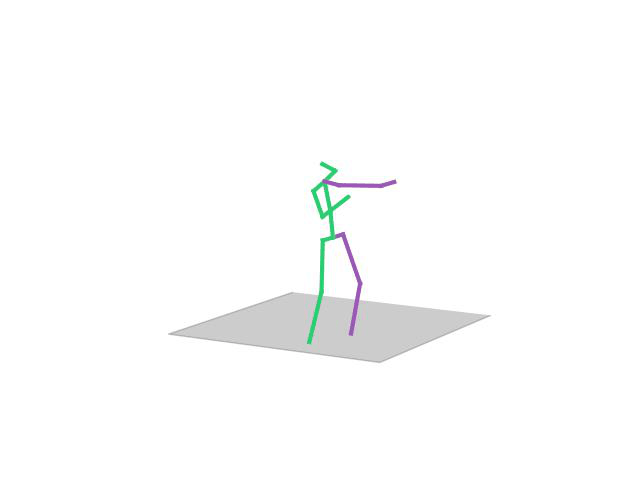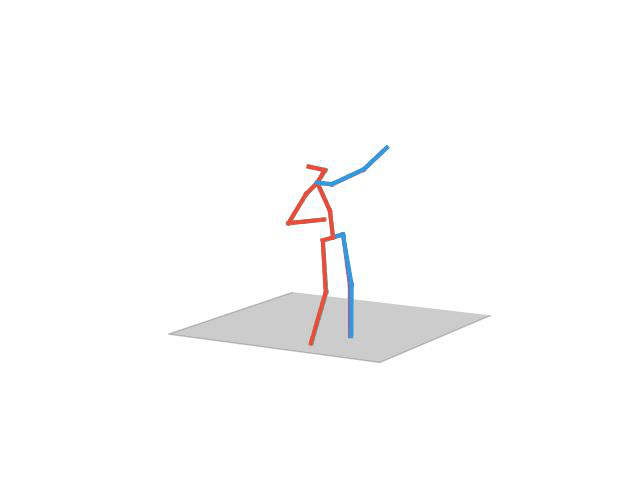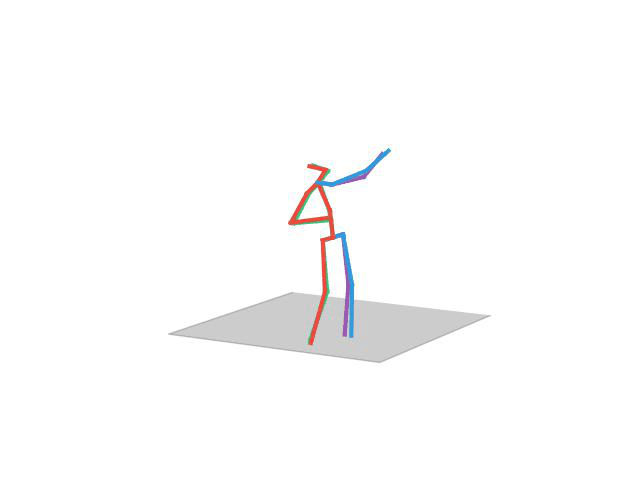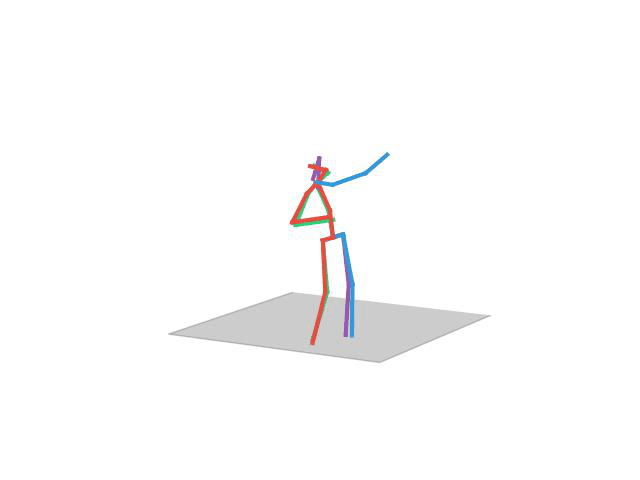
“Discussion”
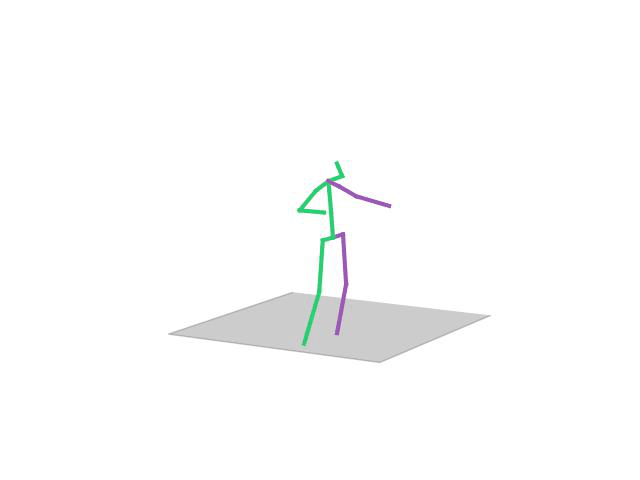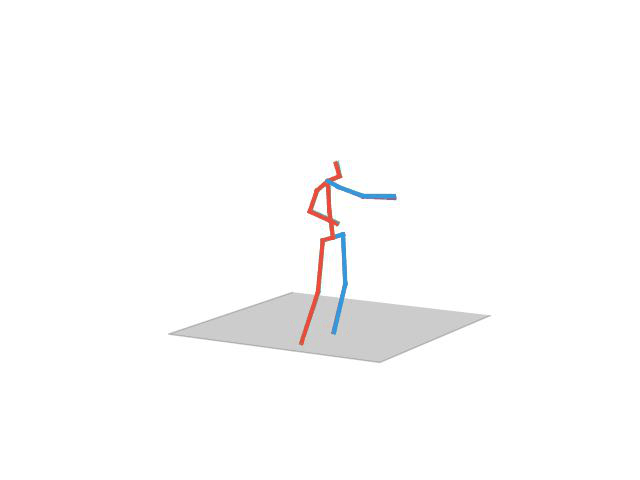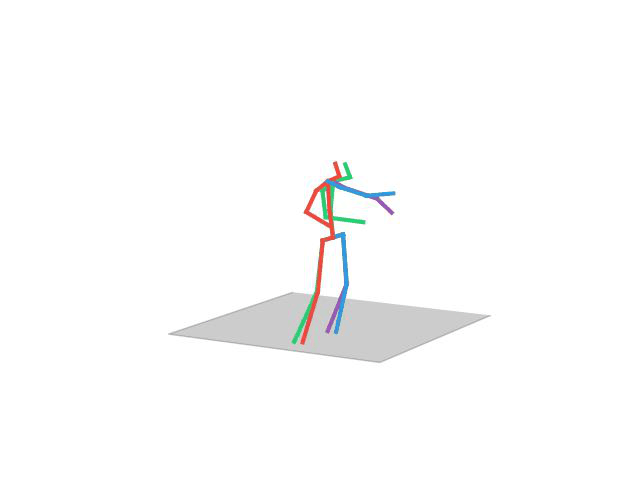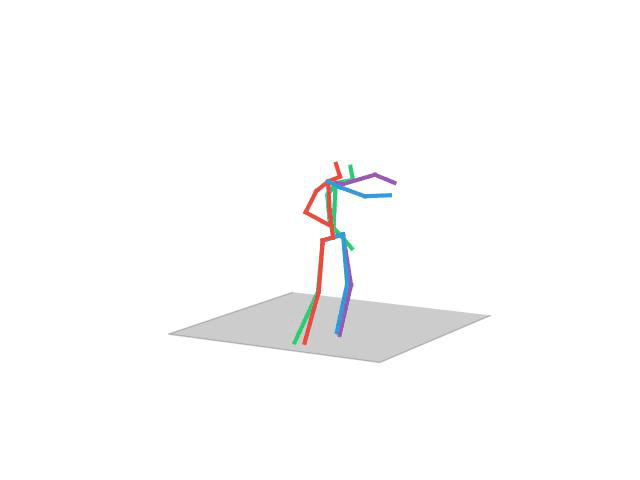
“Sitting”
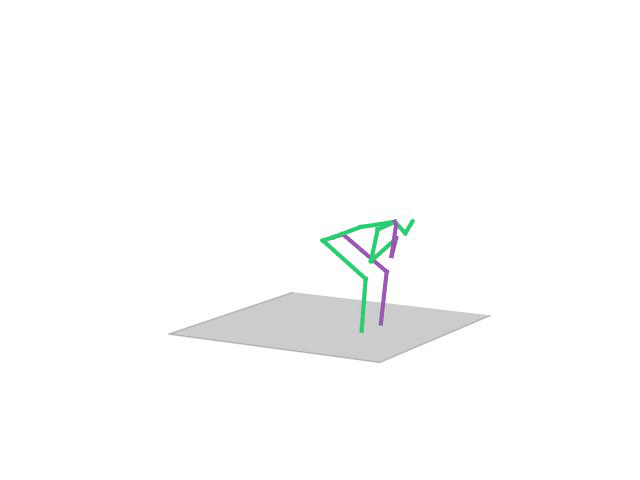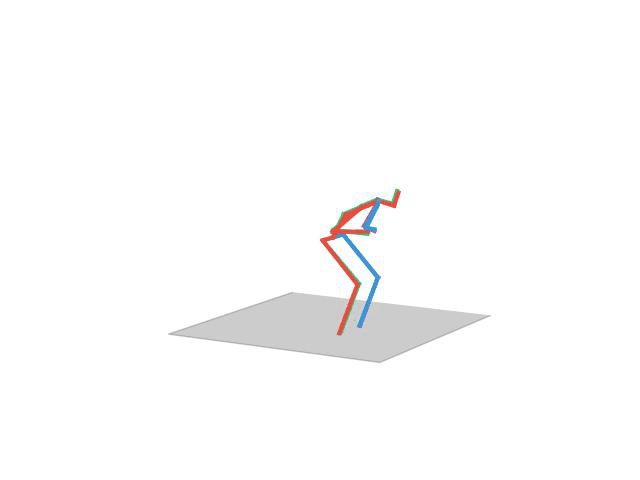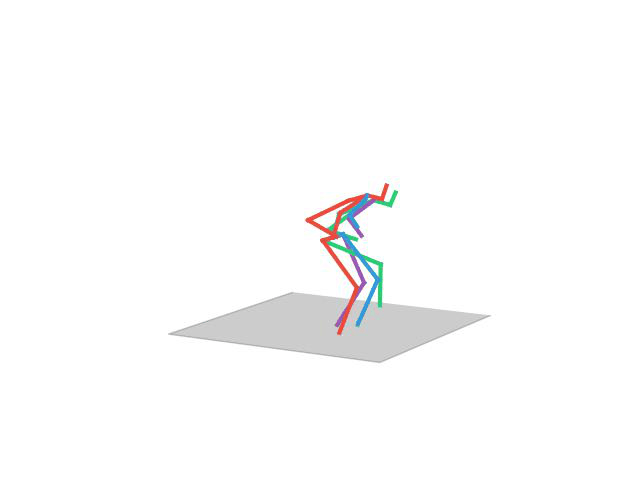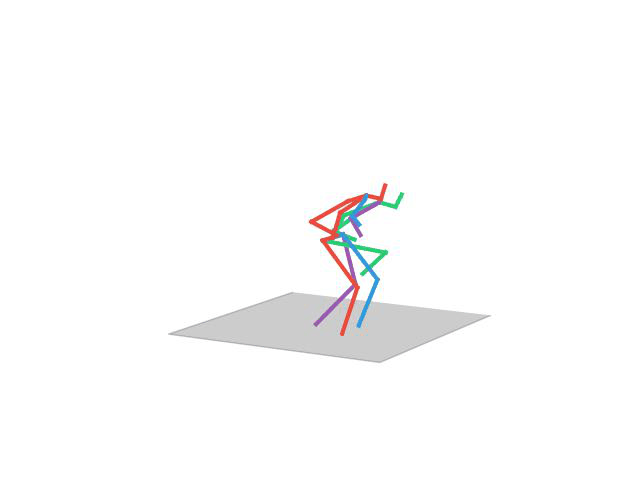
“Eating”
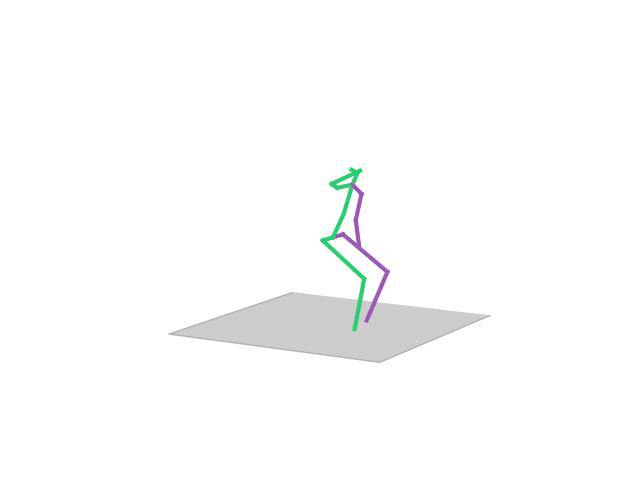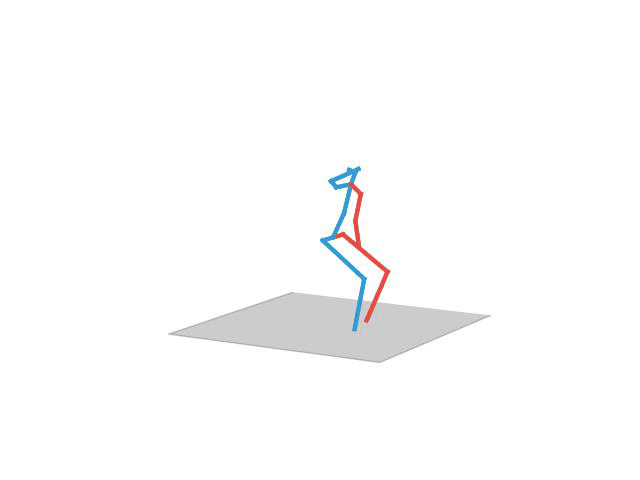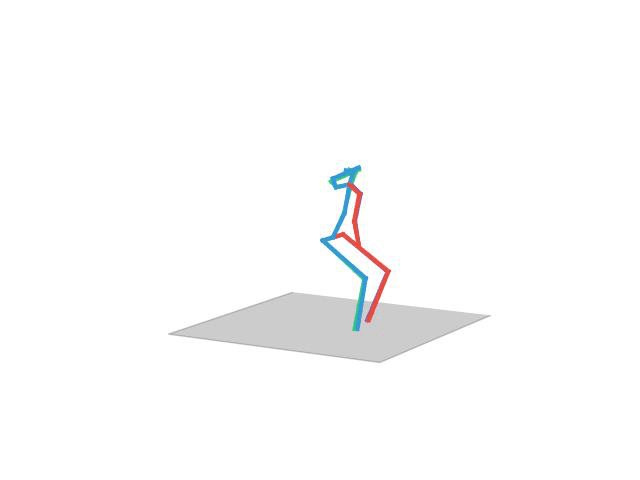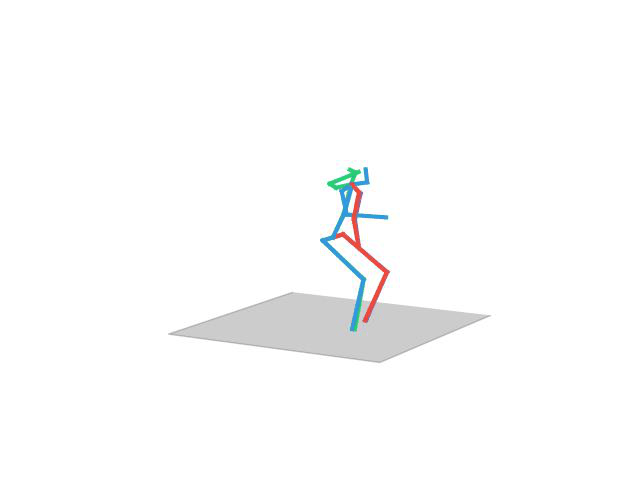
“Walking”
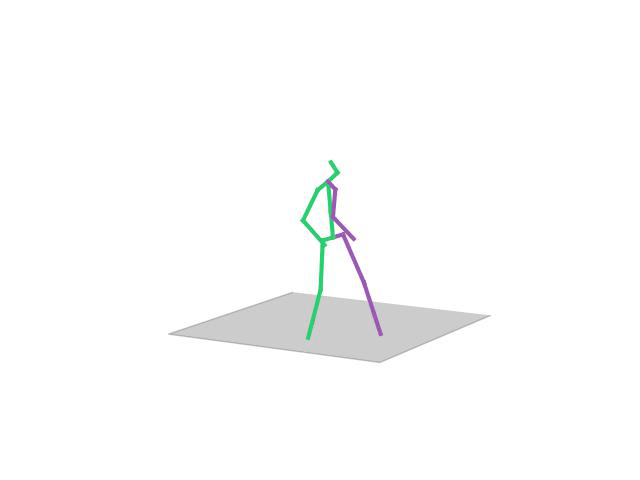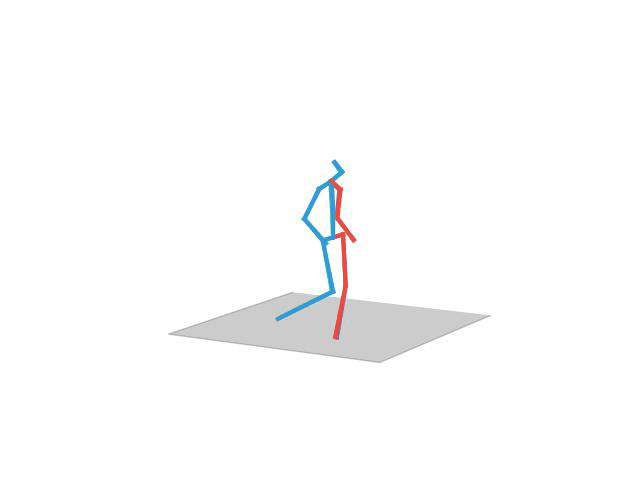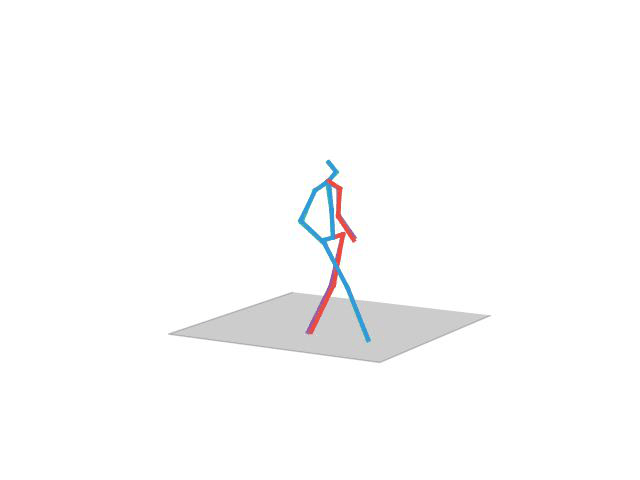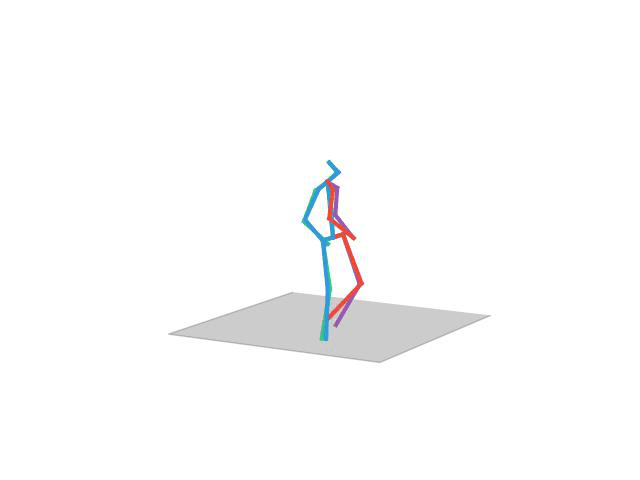
“Directions”
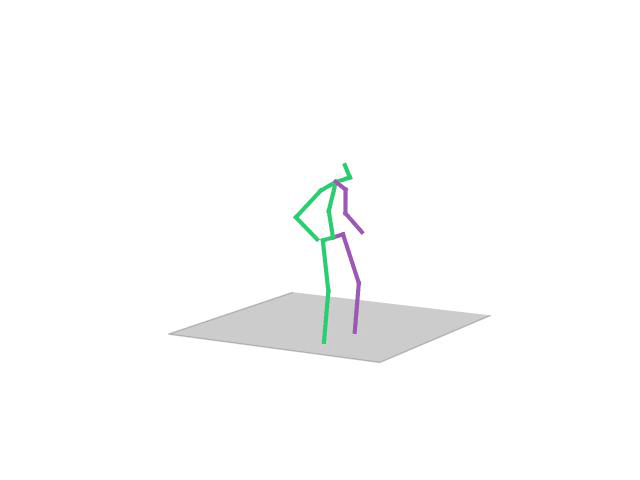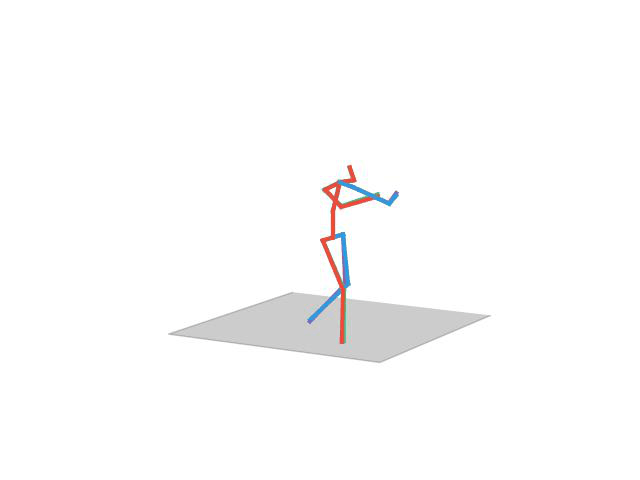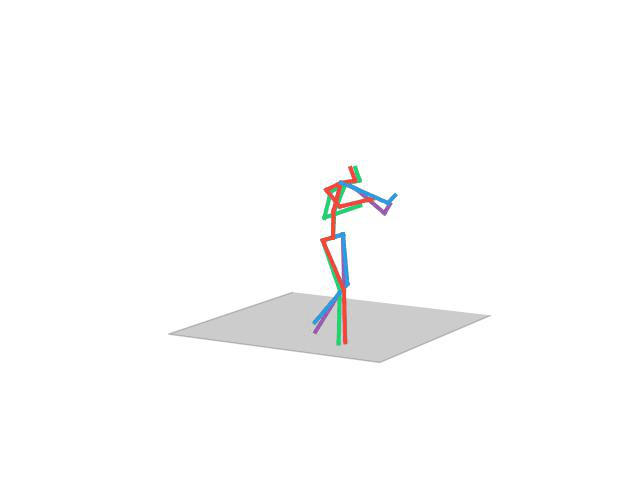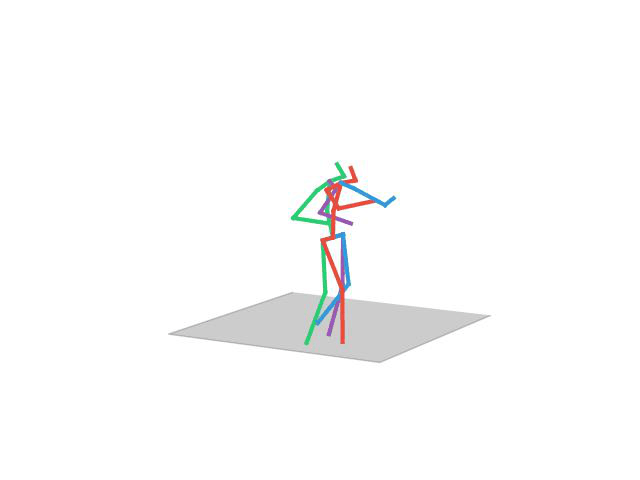
“Posing”
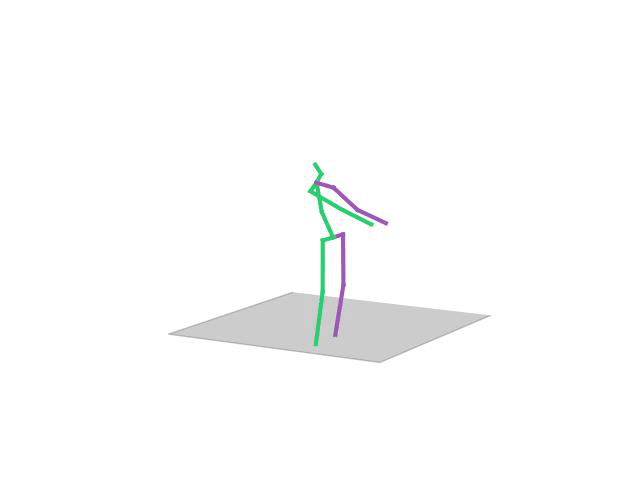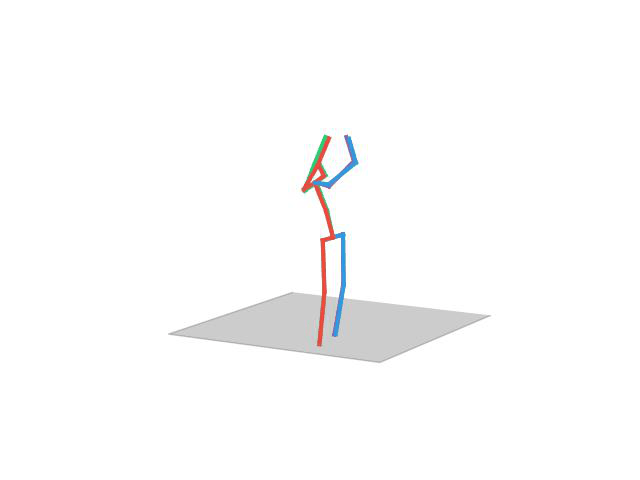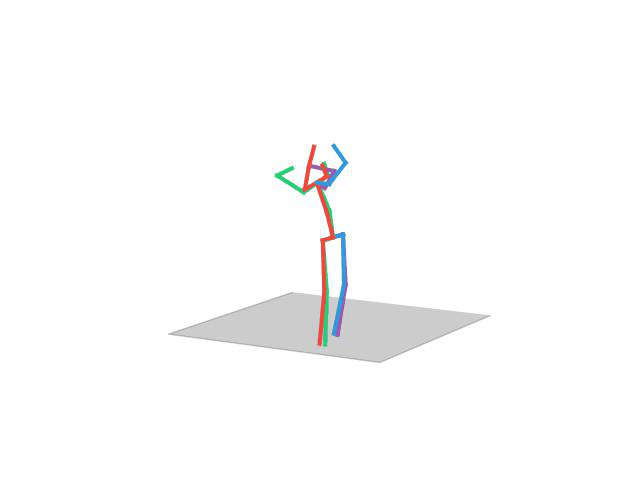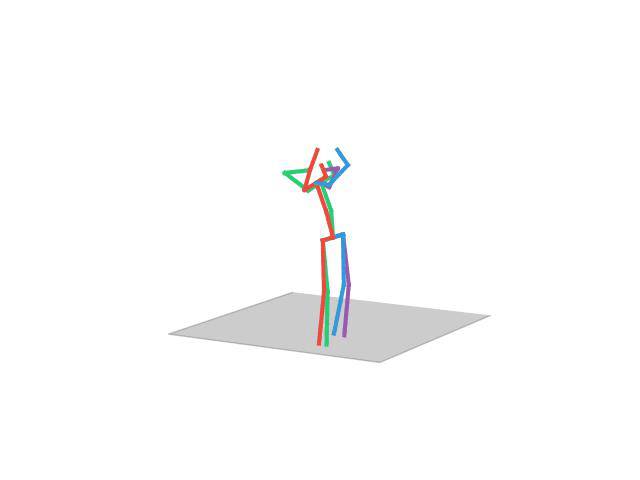
“Smoking”
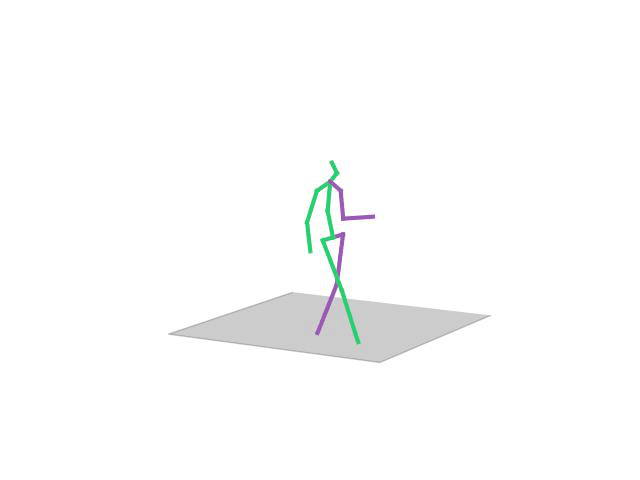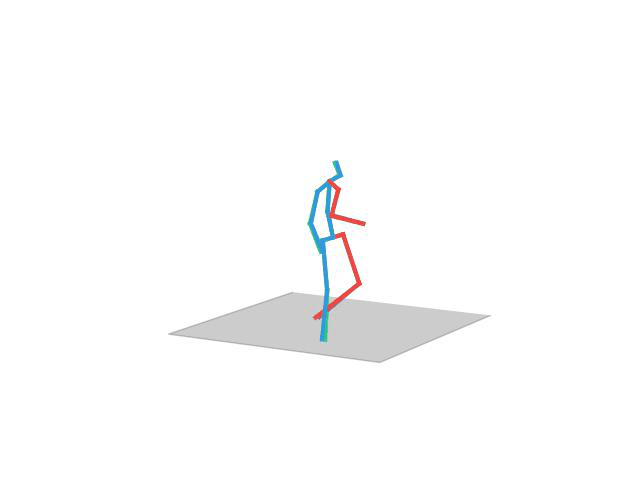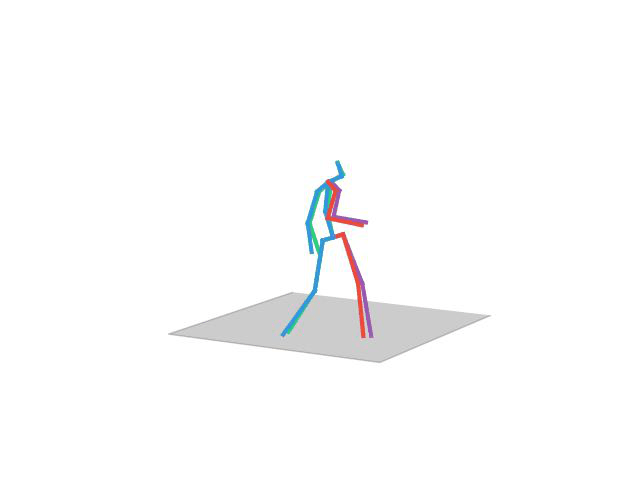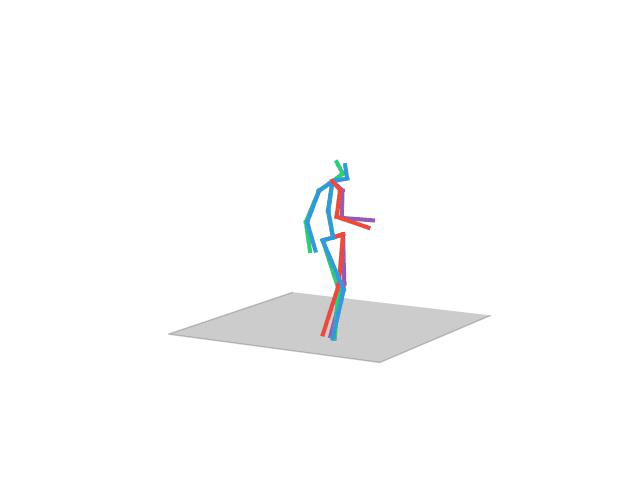
“Waving”

“Directions”
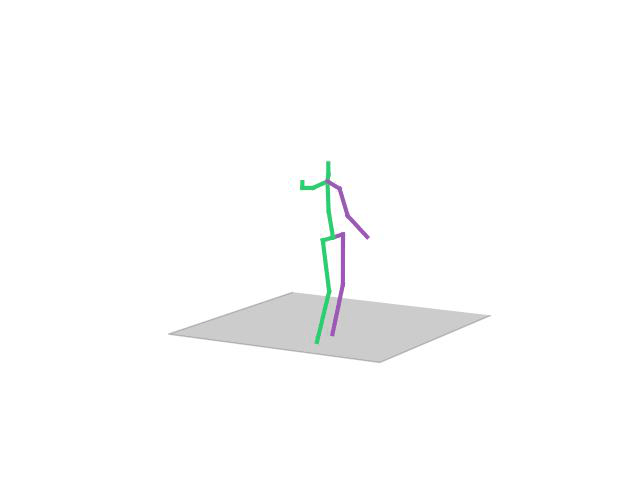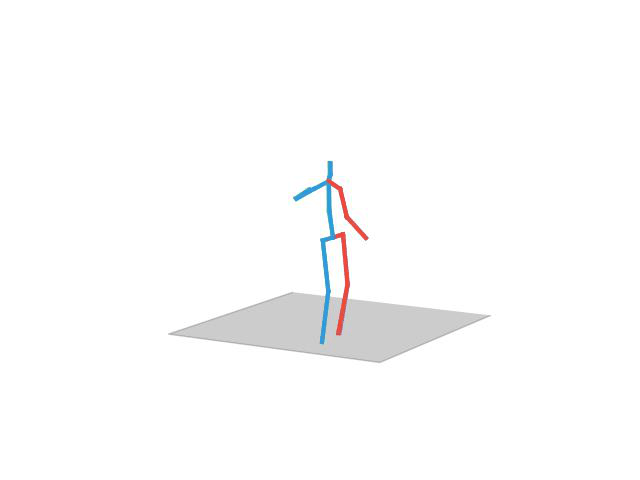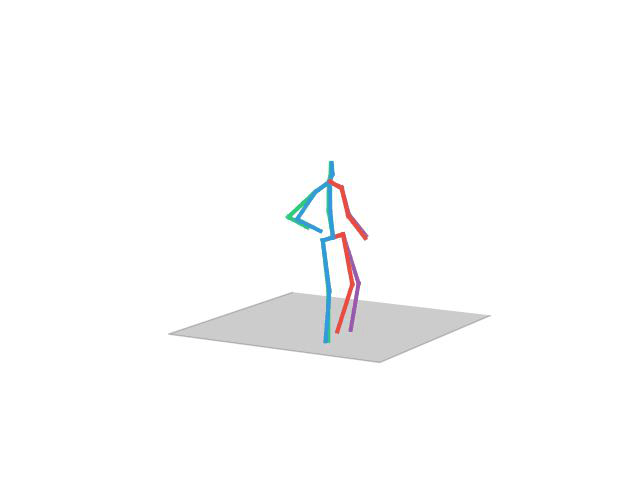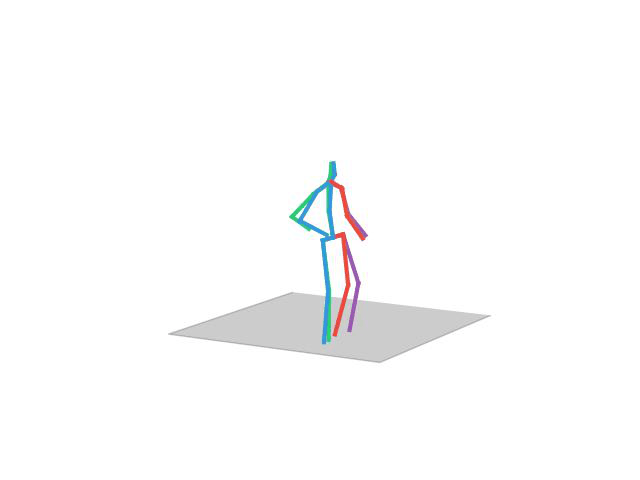
“Sitting”
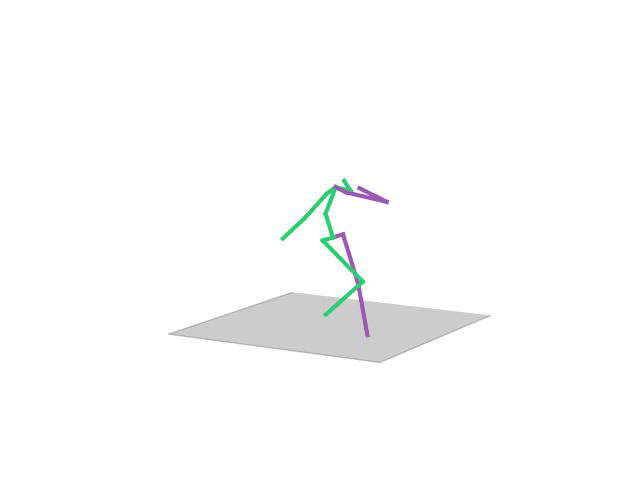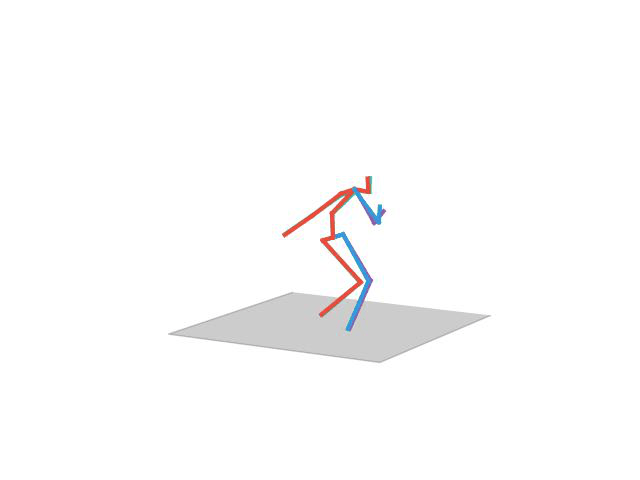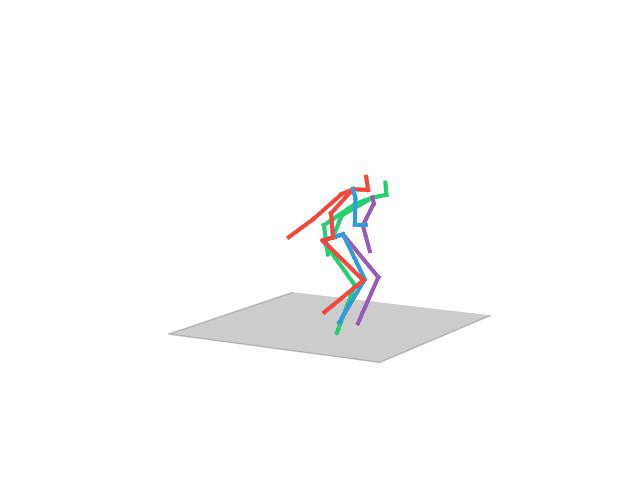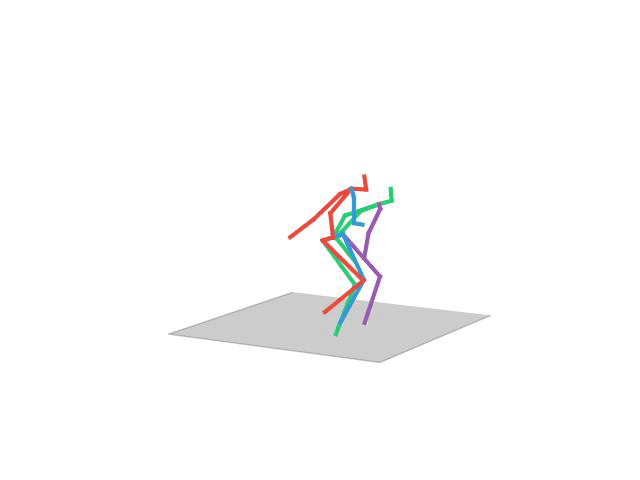
“Eating”

“Eating”
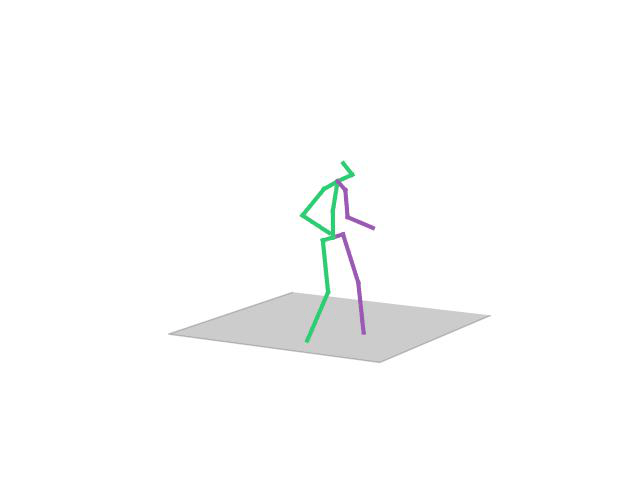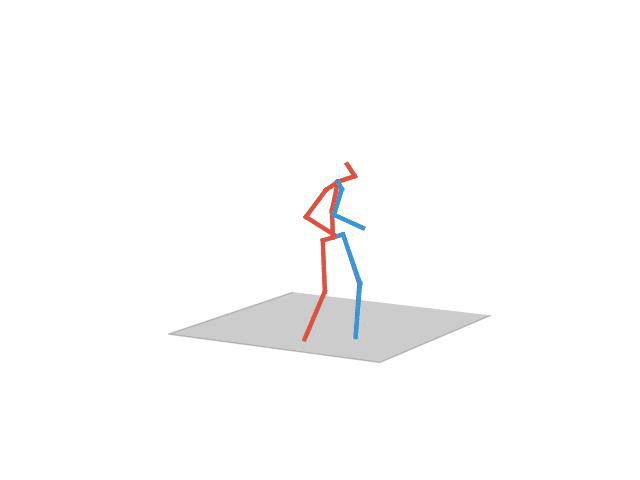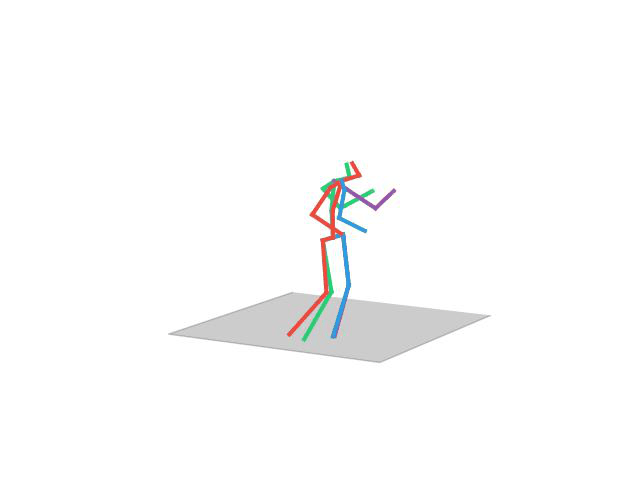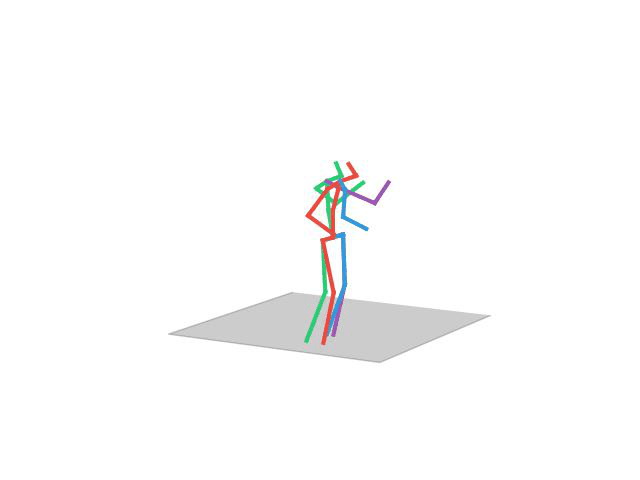
Human Motion Completion
In this task, the aim is to predict future human motion based on past observations as well as conditions that the model needs to satisfy, such as raising the hand or extending your arm. This trick allows the user to have much more control over the synthesized motions. We compare motion forecasting with completion and observe how providing additional cues to the model helps to perform more controlled and accurate motions based on instructed conditions (shown in black in the qualitative results).
“ Posing”
“ Posing”
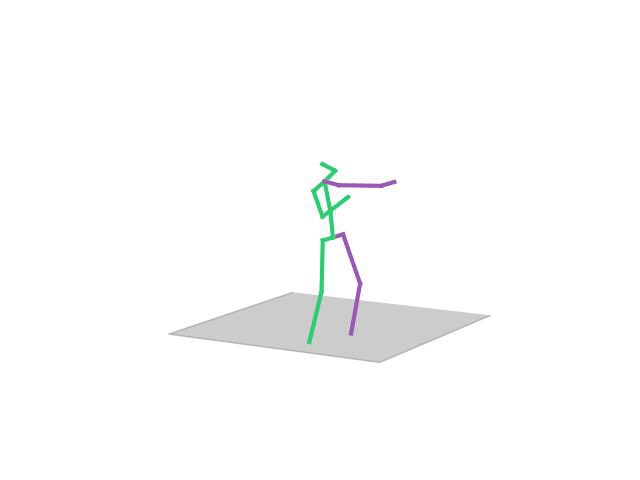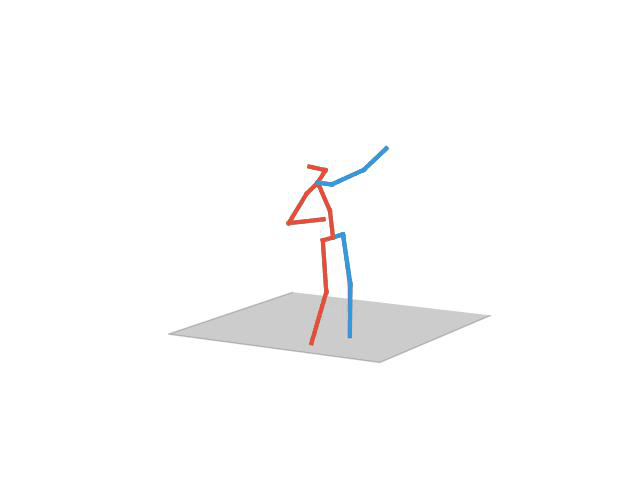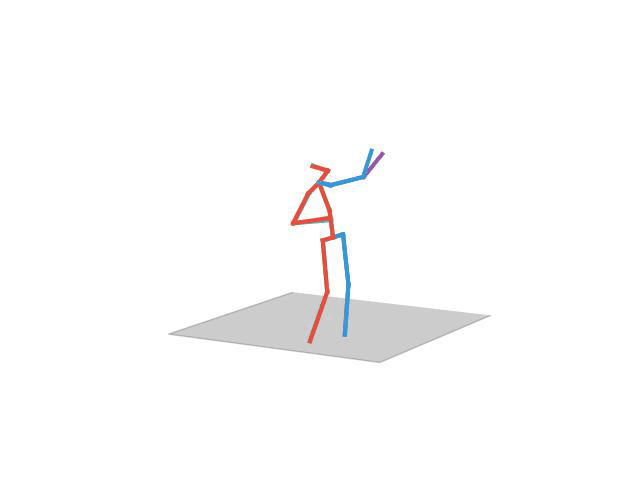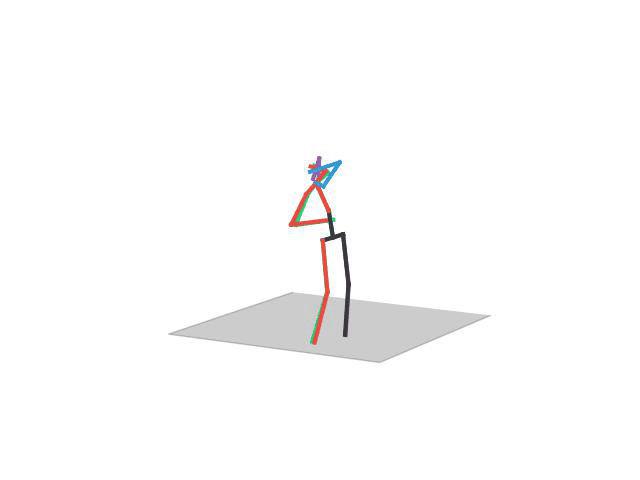
“ Taking Photo”
“ Taking Photo”
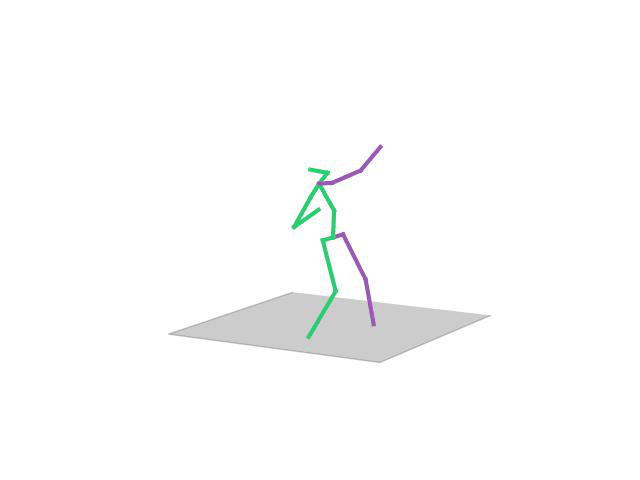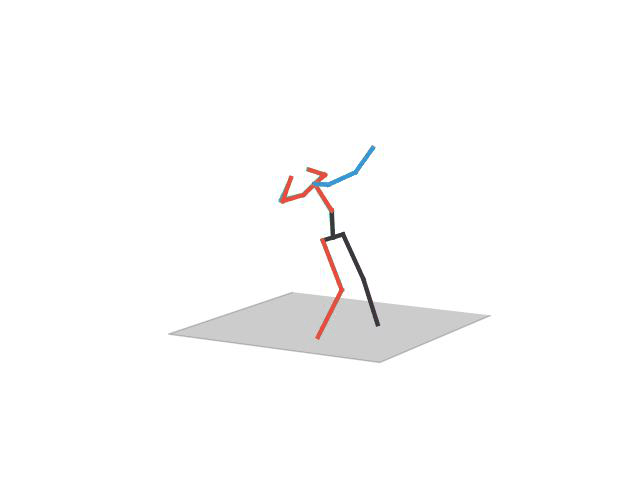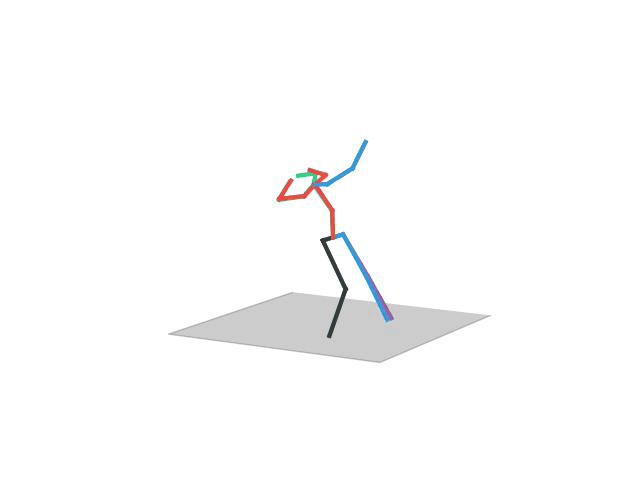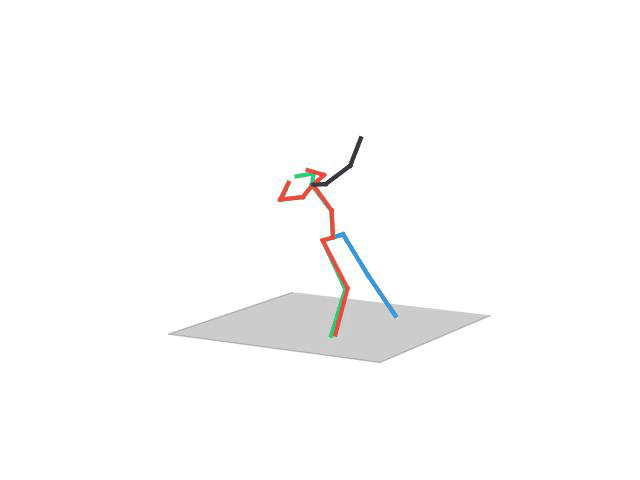
“ Directions”
“ Directions”
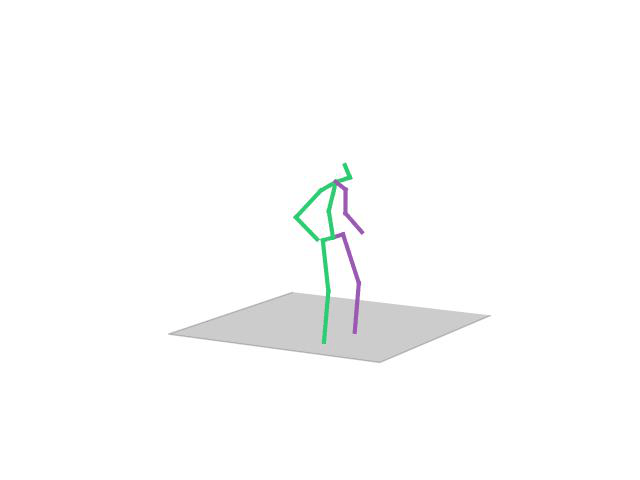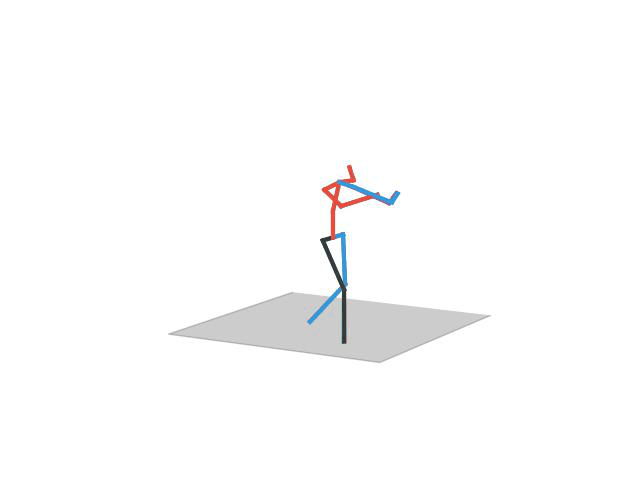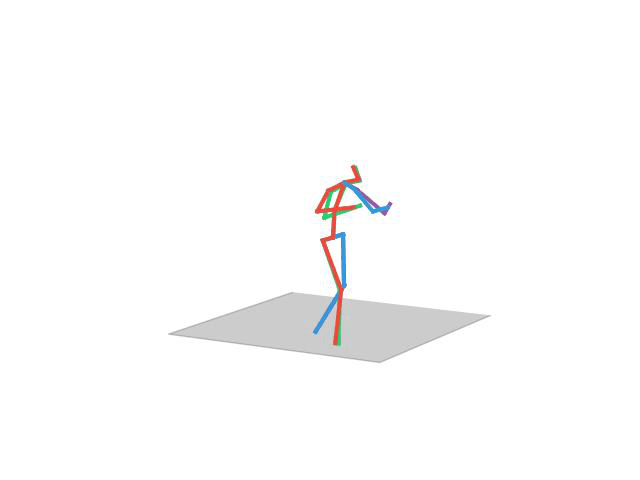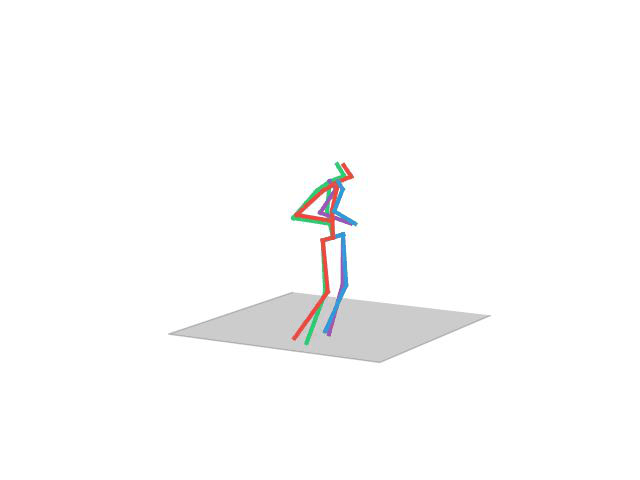
“ Phoning”

“ Phoning”
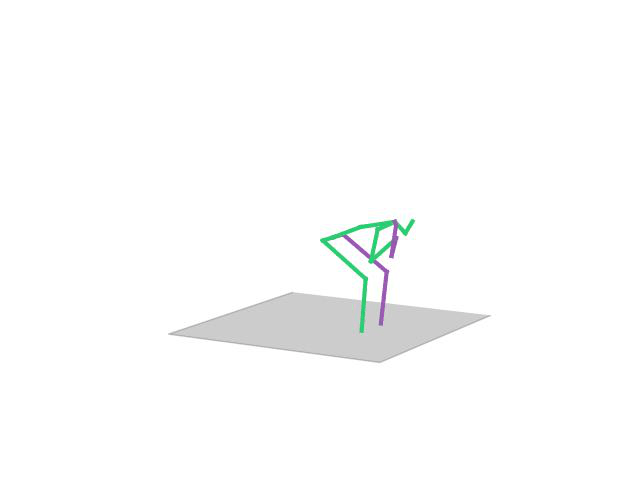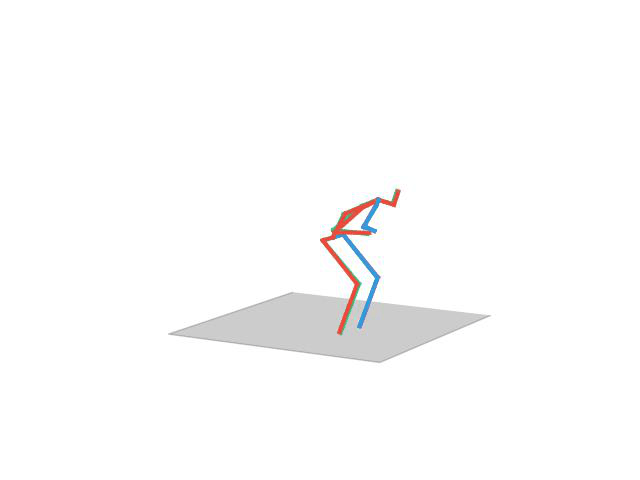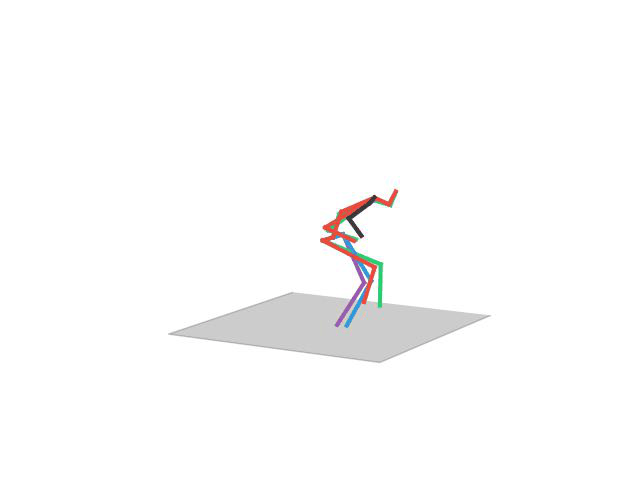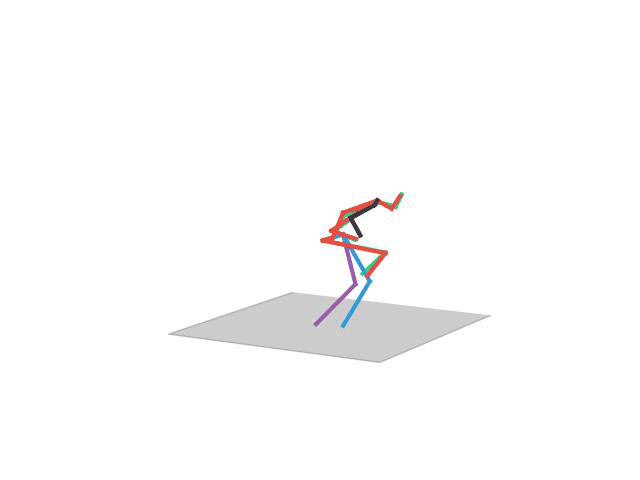
“ Posing1”
“ Posing1”
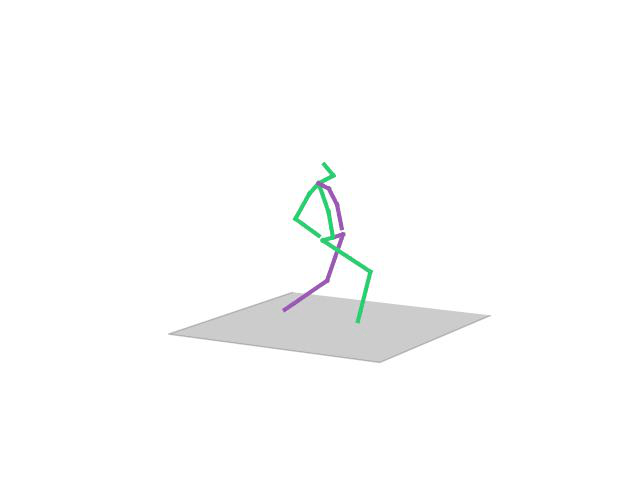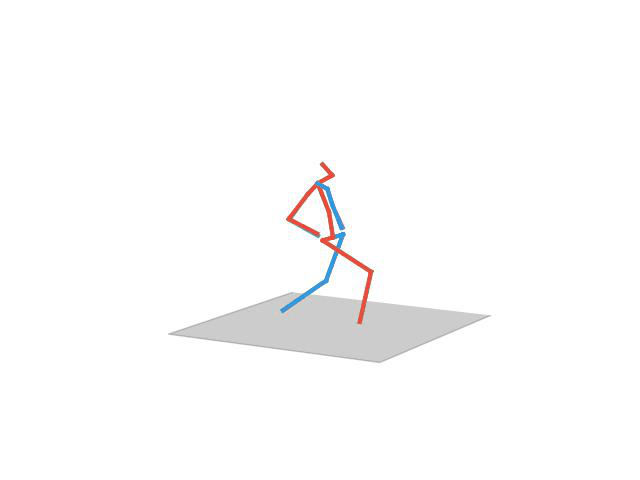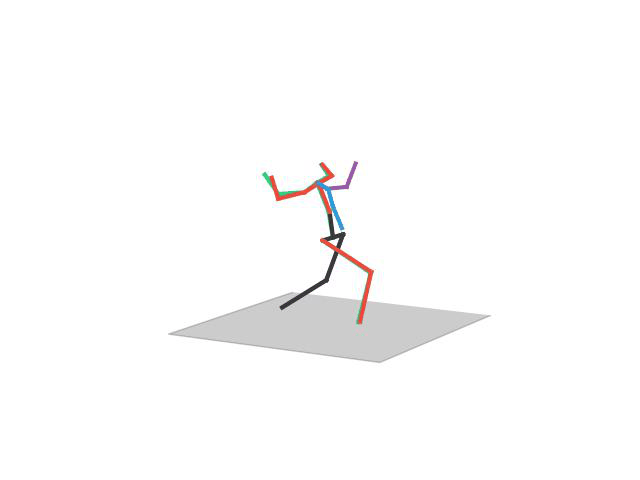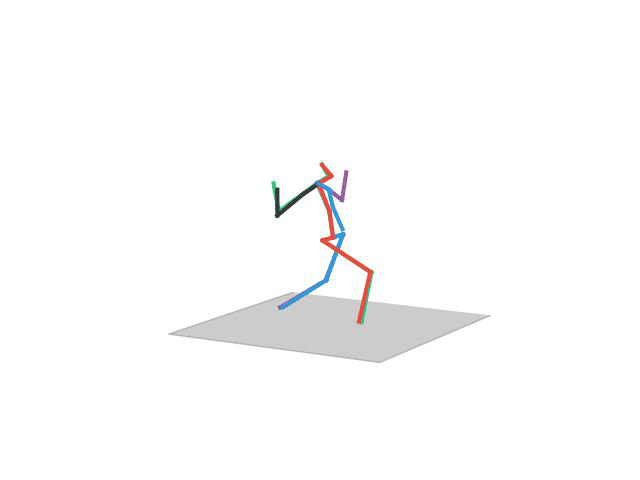
“ Sitting1”
“ Sitting1”
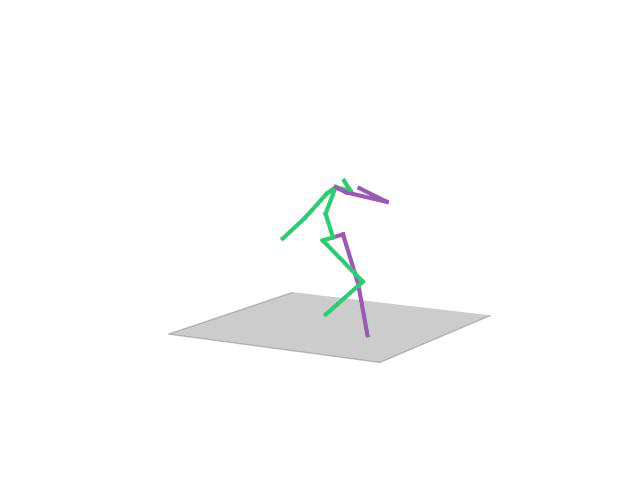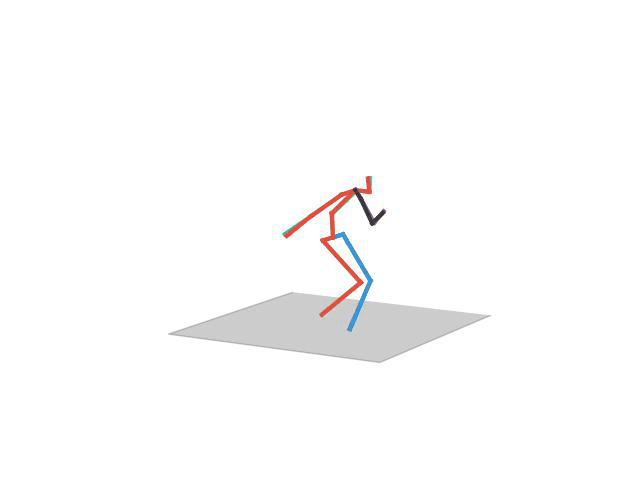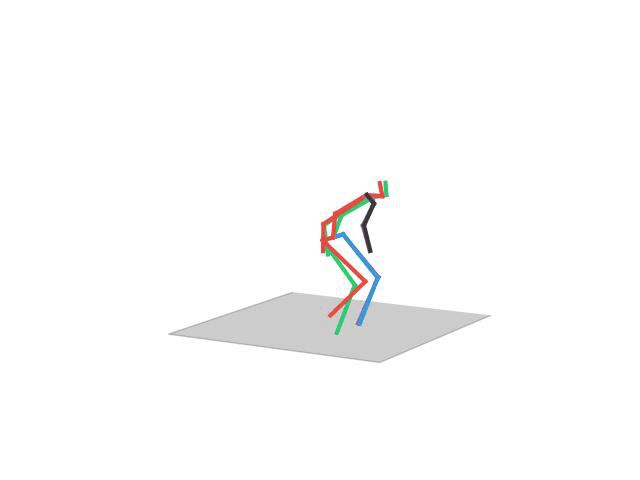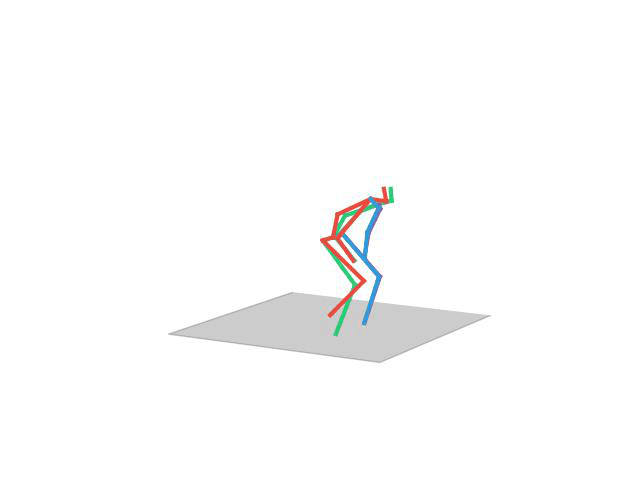
“ Posing2”
“ Posing2”
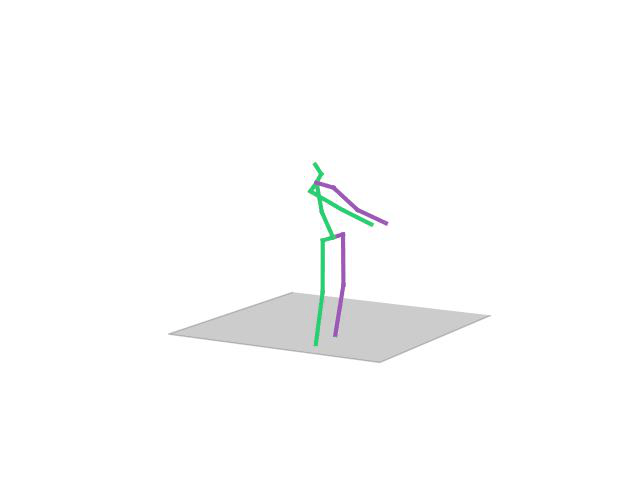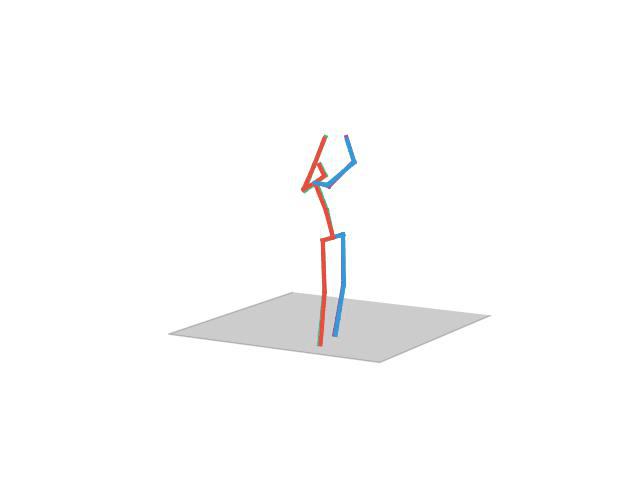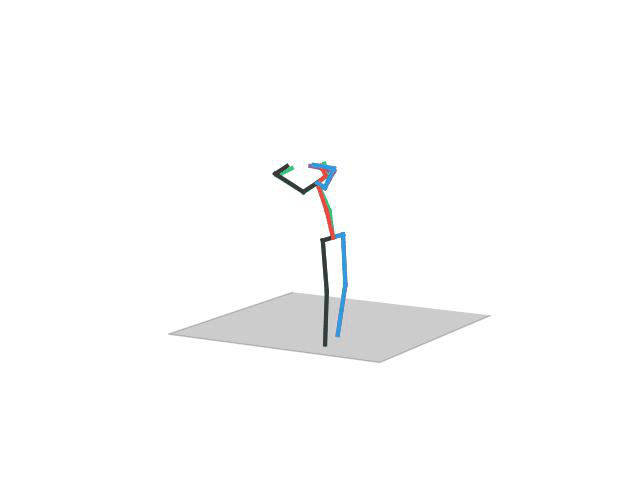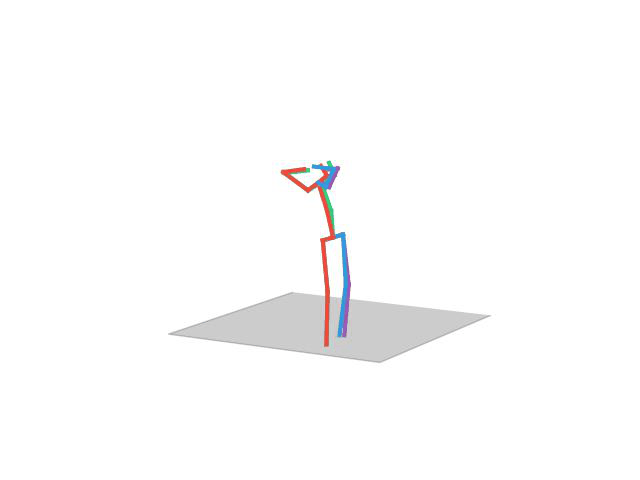
“ Walking Dog1”
“ Walking Dog1”
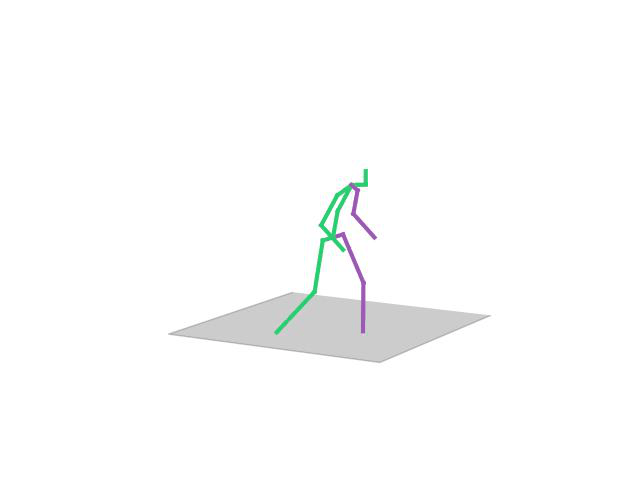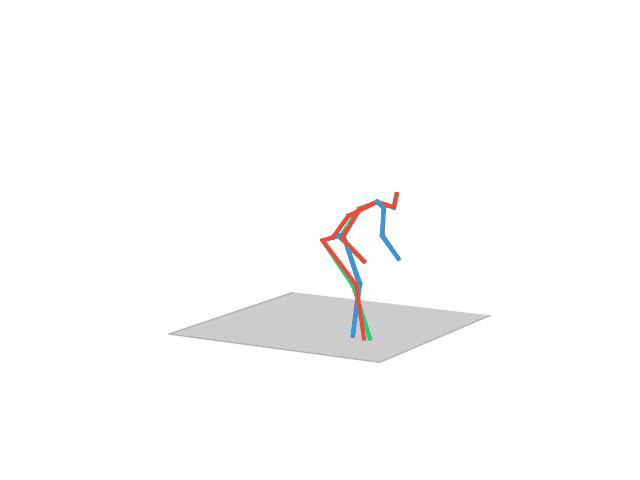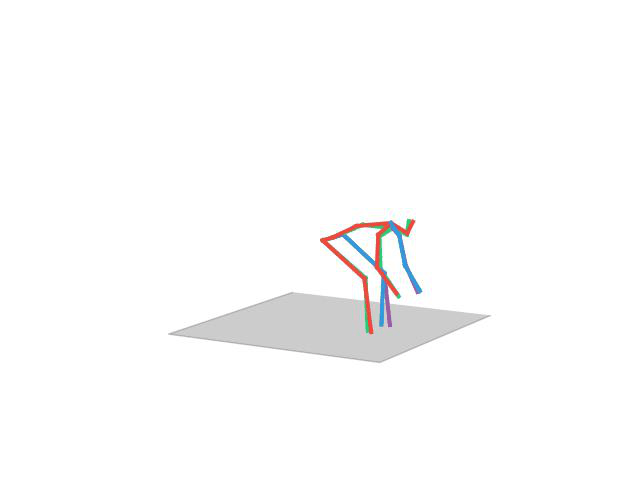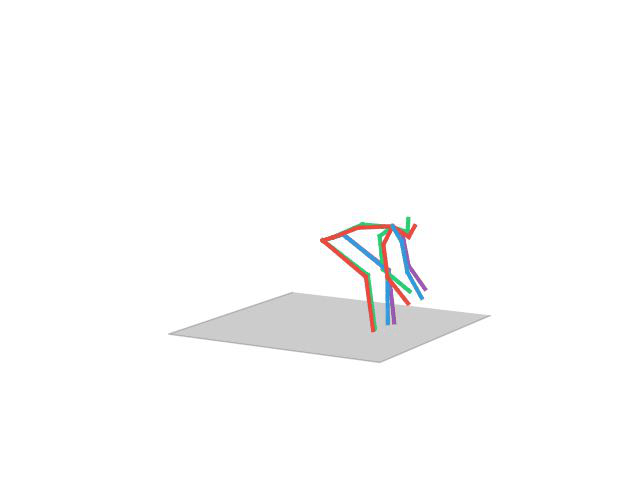
“ Sitting”
“ Sitting”
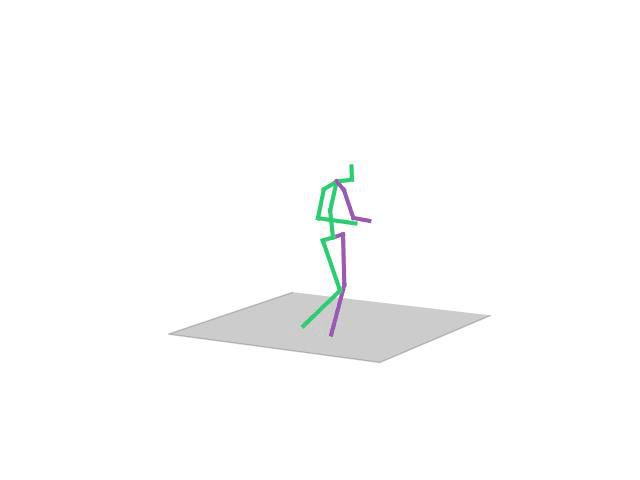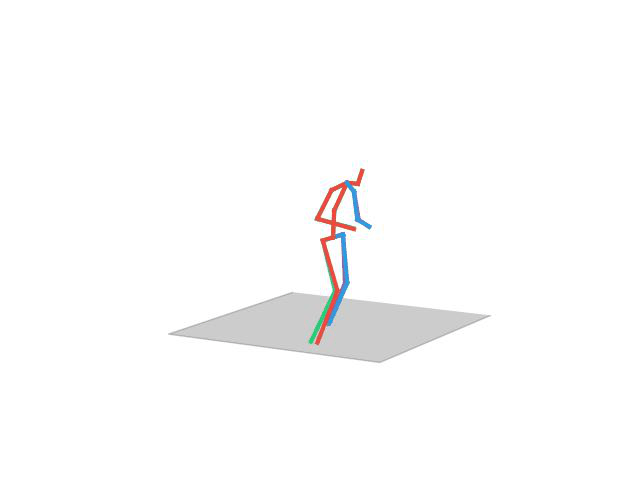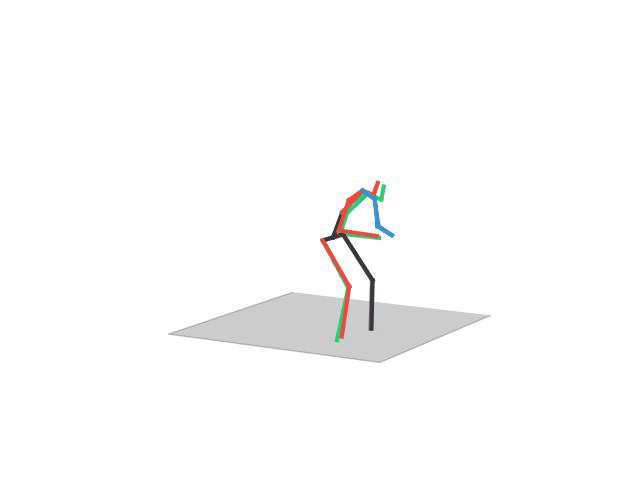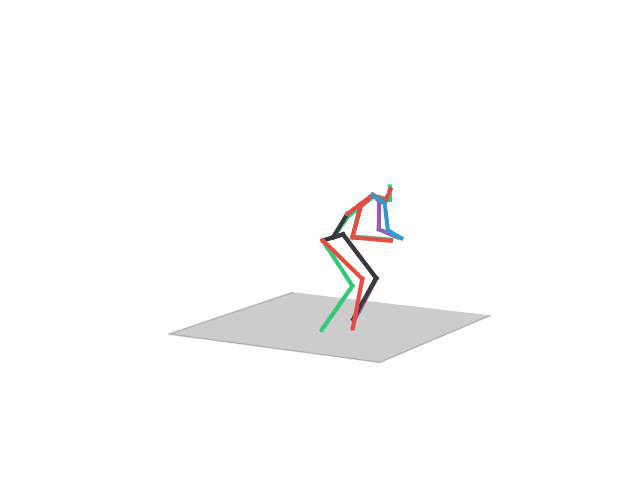
“ Walking Dog”
“ Walking Dog”
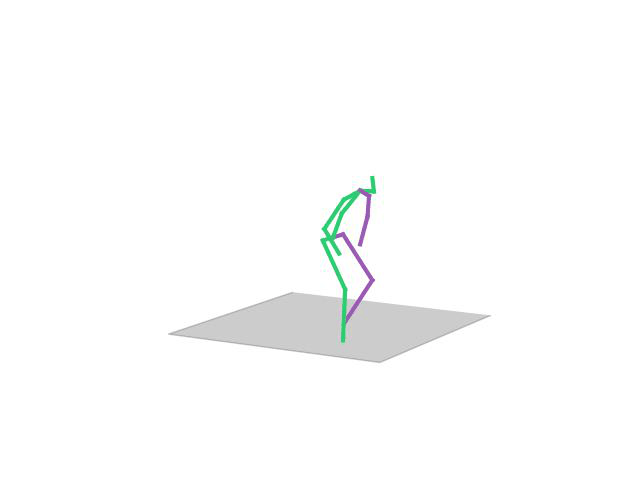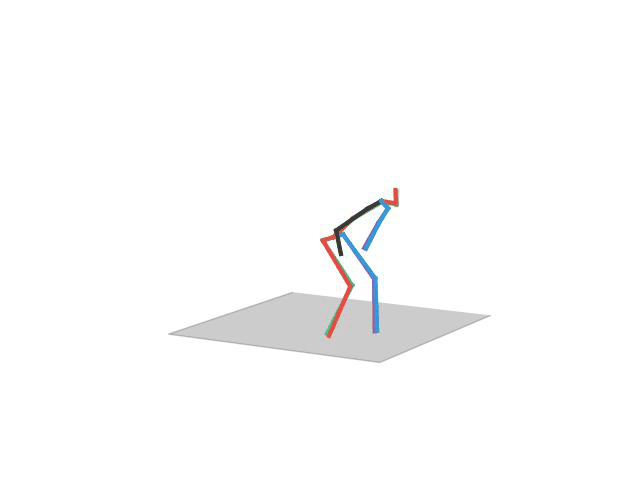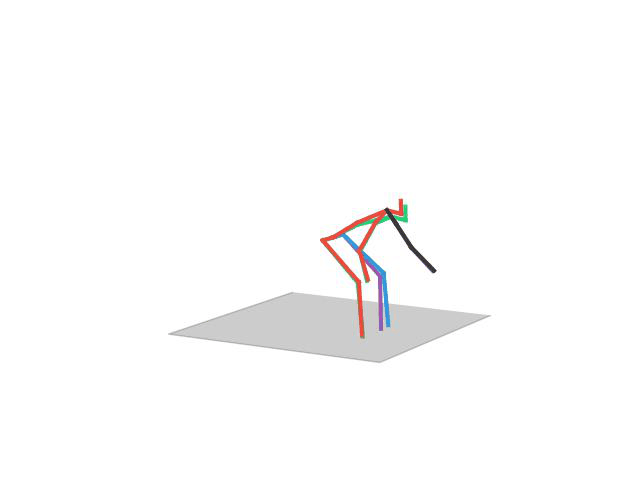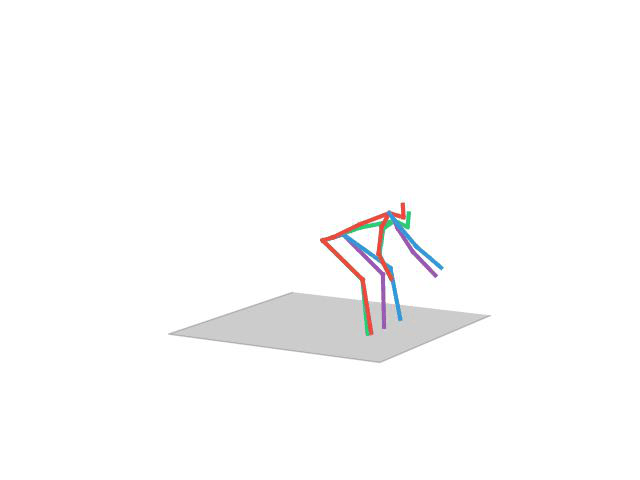
BibTeX
@article{
EsteveVallsMaskM,
title={A Unified Masked Autoencoder with Patchified Skeletons for Motion Synthesis},
author={Esteve Valls Mascaro and Hyemin Ahn and Dongheui Lee},
journal={The 38th Annual AAAI Conference on Artificial Intelligence},
year={2024},
}