Abstract
Understanding the human–object interactions (HOIs) from a video is essential to fully comprehending a visual scene. This line of research has been addressed by detecting HOIs from images and lately from videos. However, the video-based HOI anticipation task in the third-person view remains understudied. In this paper, we design a framework to detect current HOIs and anticipate future HOIs in videos. We propose to leverage human gaze information since people often fixate on an object before interacting with it. These gaze features together with the scene contexts and the visual appearances of human–object pairs are fused through a spatio-temporal transformer. To evaluate the model in the HOI anticipation task in a multi-person scenario, we propose a set of person-wise multi-label metrics. Our model is trained and validated on the VidHOI dataset, which contains videos capturing daily life and is currently the largest video HOI dataset. Experimental results in the HOI detection task show that our approach improves the baseline by a great margin of 36.3% relatively. Moreover, We conducted an extensive ablation study to demonstrate the effectiveness of our modifications and extensions to the spatio-temporal transformer.
How does it work?
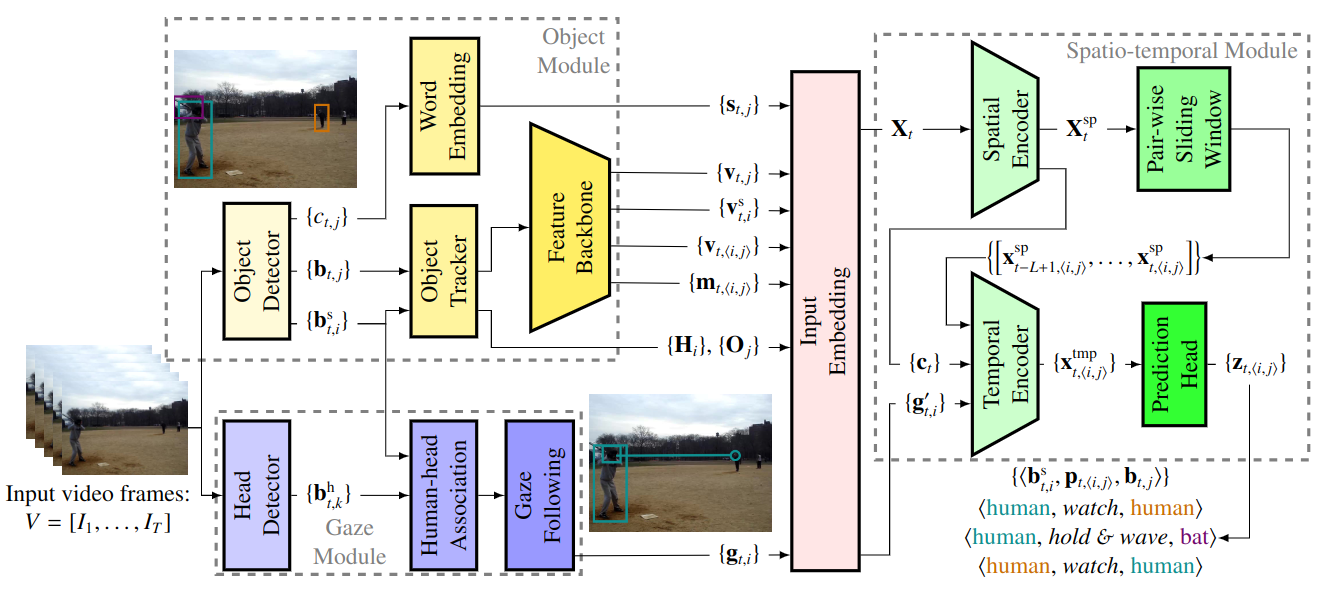
Overview of our video-based HOI detection and anticipation framework. The framework consists of three modules. The object module detects bounding boxes of humans {𝐛 s 𝑡,𝑖 } and objects {𝐛 𝑡,𝑗 }, and recognizes object classes {𝑐 𝑡,𝑗 }. An object tracker obtains human and object trajectories ({𝐇 𝑖 } and {𝐎 𝑗 }) in the video. Then, the human visual features {𝐯 s 𝑡,𝑖 }, object visual features {𝐯 𝑡,𝑗 }, visual relation features {𝐯 𝑡,⟨𝑖,𝑗⟩ }, and spatial relation features {𝐦 𝑡,⟨𝑖,𝑗⟩ } are extracted through a feature backbone. In addition, a word embedding model (Pennington et al., 2014) is applied to generate semantic features {𝐬 𝑡,𝑗 } of the object class. Meanwhile, the gaze module detects heads {𝐛 h 𝑡,𝑘 } in RGB frames, assigns them to detected humans, and generates gaze feature maps for each human {𝐠 𝑡,𝑖 } using a gaze-following model. Next, all features in a frame are projected by an input embedding sp block. The human–object pair features are concatenated to a sequence of pair representations 𝐗 𝑡 , which are refined to 𝐗 𝑡 by a spatial encoder. The spatial encoder also extracts a global context feature 𝐜 𝑡 from each frame. Then, the global features {𝐜 𝑡 } and projected human gaze features {𝐠 ′ 𝑡,𝑖 } are concatenated to build the person-wise sliding windows of context features. Meanwhile, several instance-level sliding windows are constructed, each only containing refined pair representations of one unique human–object pair across 𝐱 𝑡−𝐿+1,⟨𝑖,𝑗⟩ , … , 𝐱 𝑡,⟨𝑖,𝑗⟩ . A temporal encoder fuses context knowledge into the pair representations by the cross-attention mechanism. Finally, the prediction heads estimate the tmp probability distribution 𝐳 𝑡,⟨𝑖,𝑗⟩ of interactions for each human–object pair based on the last occurrence 𝐱 𝑡,⟨𝑖,𝑗⟩ in the temporal encoder output.
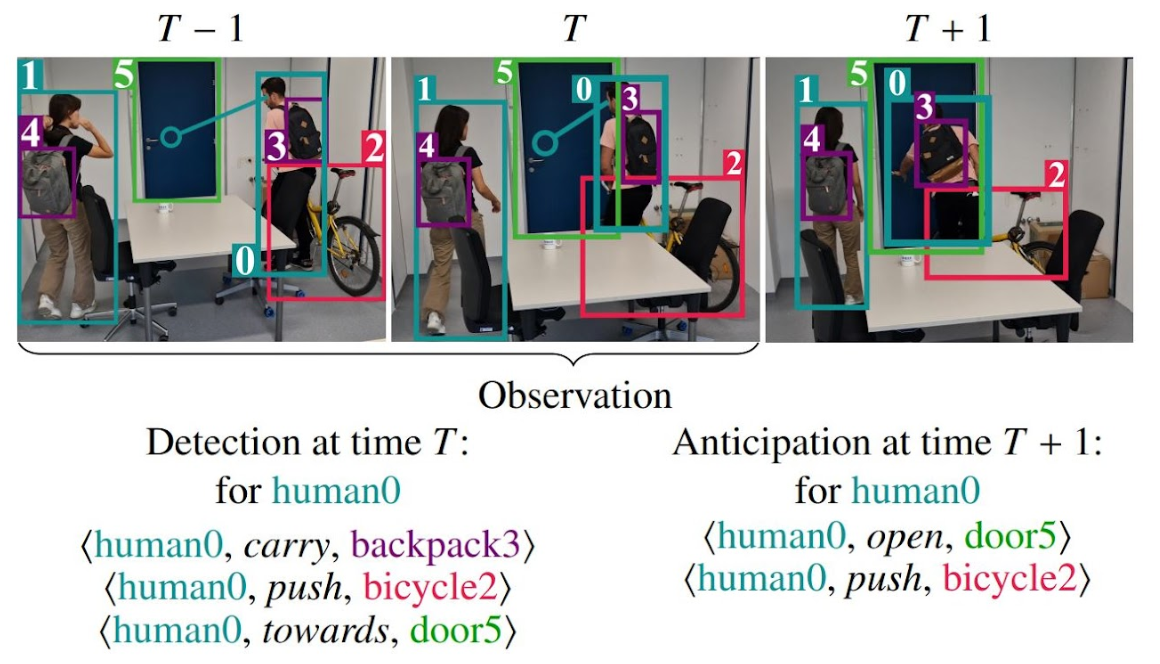
Qualitative Results

BibTeX
@article{NI2023103741,
title = {Human–Object Interaction Prediction in Videos through Gaze Following},
journal = {Computer Vision and Image Understanding},
volume = {233},
pages = {103741},
year = {2023},
issn = {1077-3142},
doi = {https://doi.org/10.1016/j.cviu.2023.103741},
url = {https://www.sciencedirect.com/science/article/pii/S1077314223001212},
author = {Zhifan Ni and Esteve {Valls Mascar\'o} and Hyemin Ahn and Dongheui Lee},
}
}