Abstract
Robots are becoming increasingly integrated into our lives, assisting us in various tasks. To ensure effective collaboration between humans and robots, it is essential that they understand our intentions and anticipate our actions. In this paper, we propose a Human-Object Interaction (HOI) anticipation framework for Assistive Robots. We propose an efficient and robust transformer-based model to detect and anticipate HOIs from videos. This enhanced anticipation empowers robots to proactively assist humans, resulting in more efficient and intuitive collaborations. Our model outperforms state-of-the-art results in HOI detection and anticipation in VidHOI dataset with an increase of 1.76% and 1.04% in mAP respectively while being 15.4 times faster. We showcase the effectiveness of our approach through experimental results in a real robot, demonstrating that the robot’s ability to anticipate HOIs is key for better Human-Robot Interaction
How does it work?
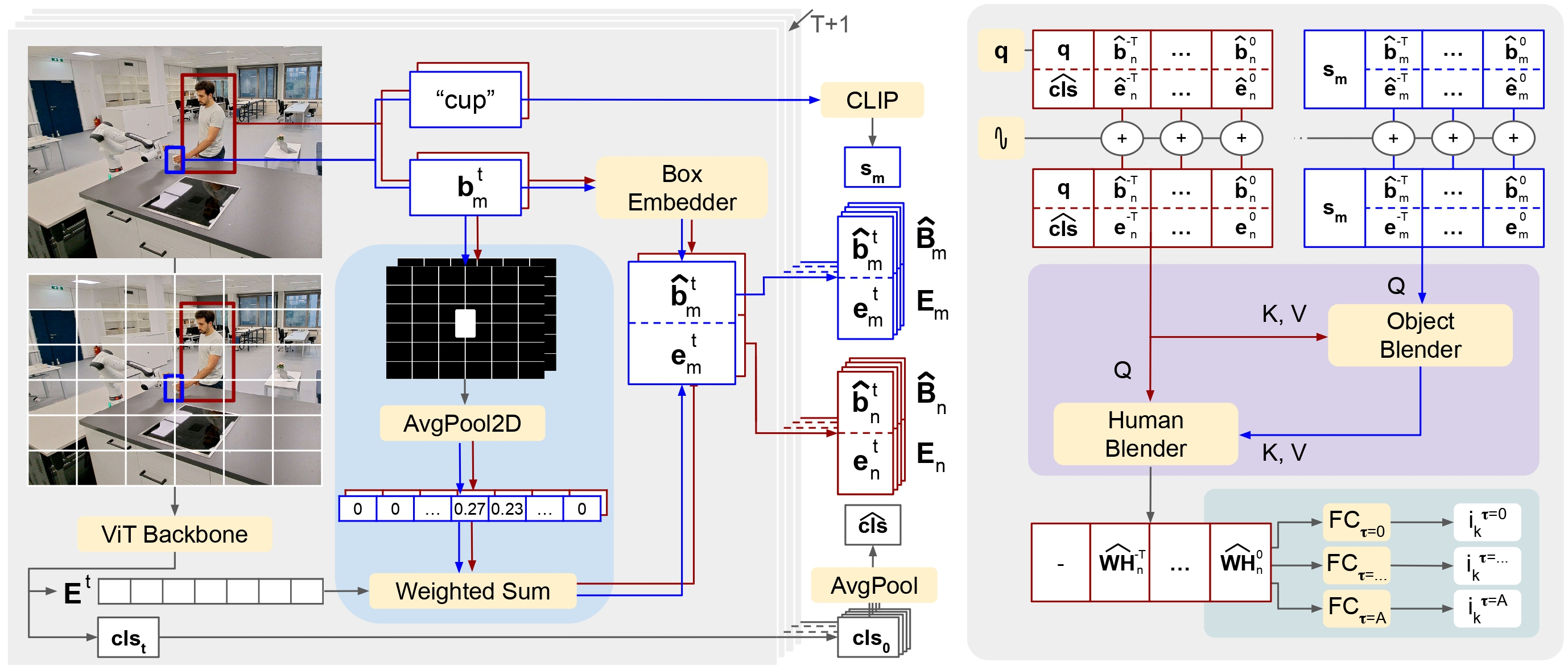
Our two-stage model predicts HOI in videos. Here, we consider a video of T + 1 frames with the pre-extracted object and human bounding boxes. Our module initially extracts relevant features per frame (left) to later on detect and anticipate HOIs (right). First, we leverage a pre-trained ViT architecture [45] to extract patch-based local features Et and also global context features clst per each frame. Then, we obtain individual features per human et n and object et m by aligning Et to their bounding boxes through our Patch Merger strategy, shown in blue. We also project each bounding box Bt to ˆBt using a box embedder [46], and the object category to a semantic feature using CLIP [47]. We finalize the feature extraction by averaging all clst in time. Our Dual Transformer module, shown in purple, leverages the human and object-constructed windows (sequences in red and blue respectively) through two cross-attention transformers. Finally, we project the enhanced last feature from the Human Blender to detect and anticipate HOIs at several time horizons iτ k in the future through our Hydra head (shown in green)
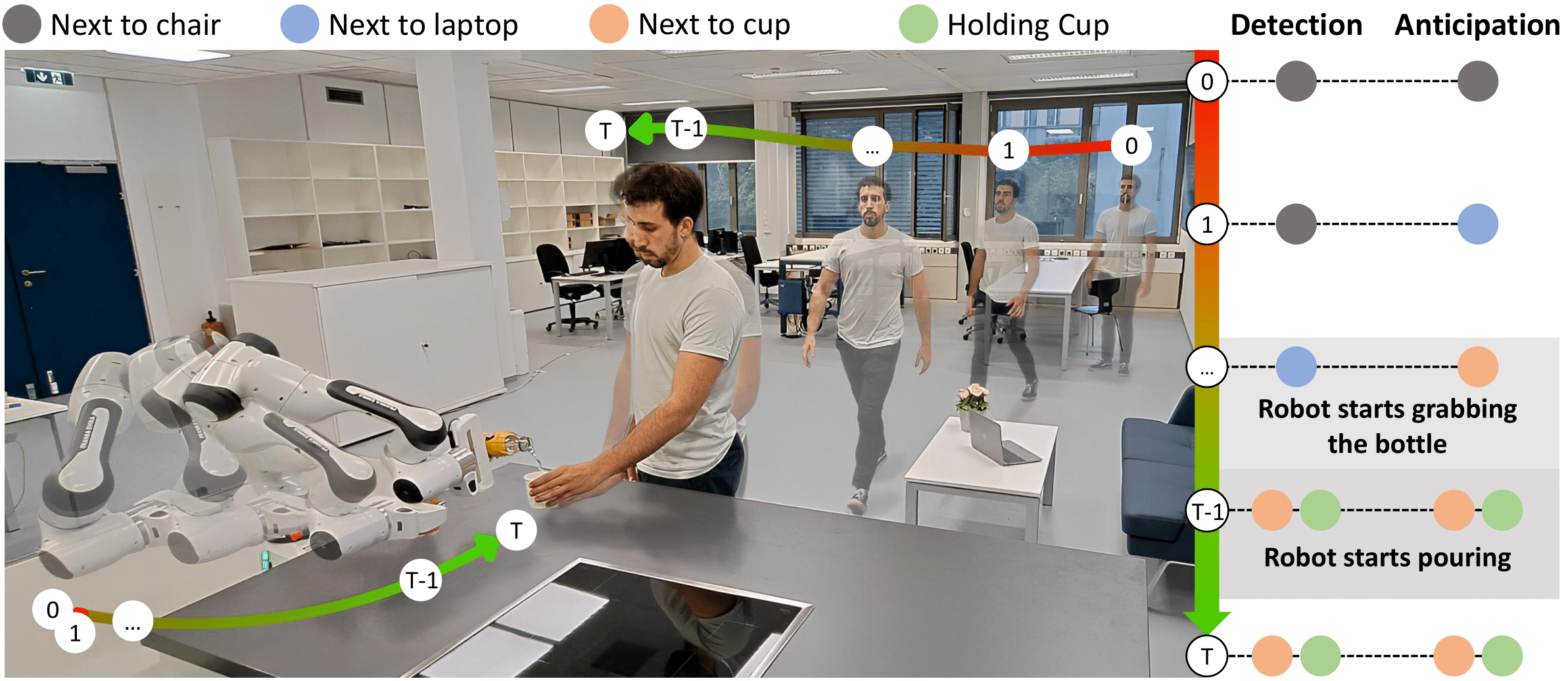
Qualitative Results
HOI detection and anticipation are essential for robots to comprehend the surrounding humans and better predict their needs, so the robot can assist in a timely manner. We conduct real experiments with a Franka Emika Panda robot to showcase the benefit of our approach in assistive robots beyond the offline VidHOI dataset. We consider the ‘pouring task’ in a kitchen scenario where the robot assumes the role of a bartender with the goal of pouring a beverage for the human. Next we showcase different experiments to demonstrate the robustness of our HOI4ABOT to detecting and anticipating HOIs for multiple people and multiple objects, in a cluttered scenario and also with more complex robot tasks.
“Complex scenario”
“Different robot actions: object handover”
“Distinguishing between multiple objects and people”
BibTeX
@inproceedings{
mascaro2023hoiabot,
title={{HOI}4{ABOT}: Human-Object Interaction Anticipation for Human Intention Reading Assistive ro{BOT}s},
author={Esteve Valls Mascaro and Daniel Sliwowski and Dongheui Lee},
booktitle={7th Annual Conference on Robot Learning},
year={2023},
url={https://openreview.net/forum?id=rYZBdBytxBx}
}