Abstract
This paper introduces a novel deep-learning approach for human-to-robot motion retargeting, enabling robots to mimic human poses accurately. Contrary to prior deep-learning-based works, our method does not require paired human-to-robot data, which facilitates its translation to new robots. First, we construct a shared latent space between humans and robots via adaptive contrastive learning that takes advantage of a proposed cross-domain similarity metric between the human and robot poses. Additionally, we propose a consistency term to build a common latent space that captures the similarity of the poses with precision while allowing direct robot motion control from the latent space. For instance, we can generate in-between motion through simple linear interpolation between two projected human poses. We conduct a comprehensive evaluation of robot control from diverse modalities (i.e., texts, RGB videos, and key poses), which facilitates robot control for non-expert users. Our model outperforms existing works regarding human-to-robot retargeting in terms of efficiency and precision. Finally, we implemented our method in a real robot with self-collision avoidance through a whole-body controller to showcase the effectiveness of our approach.
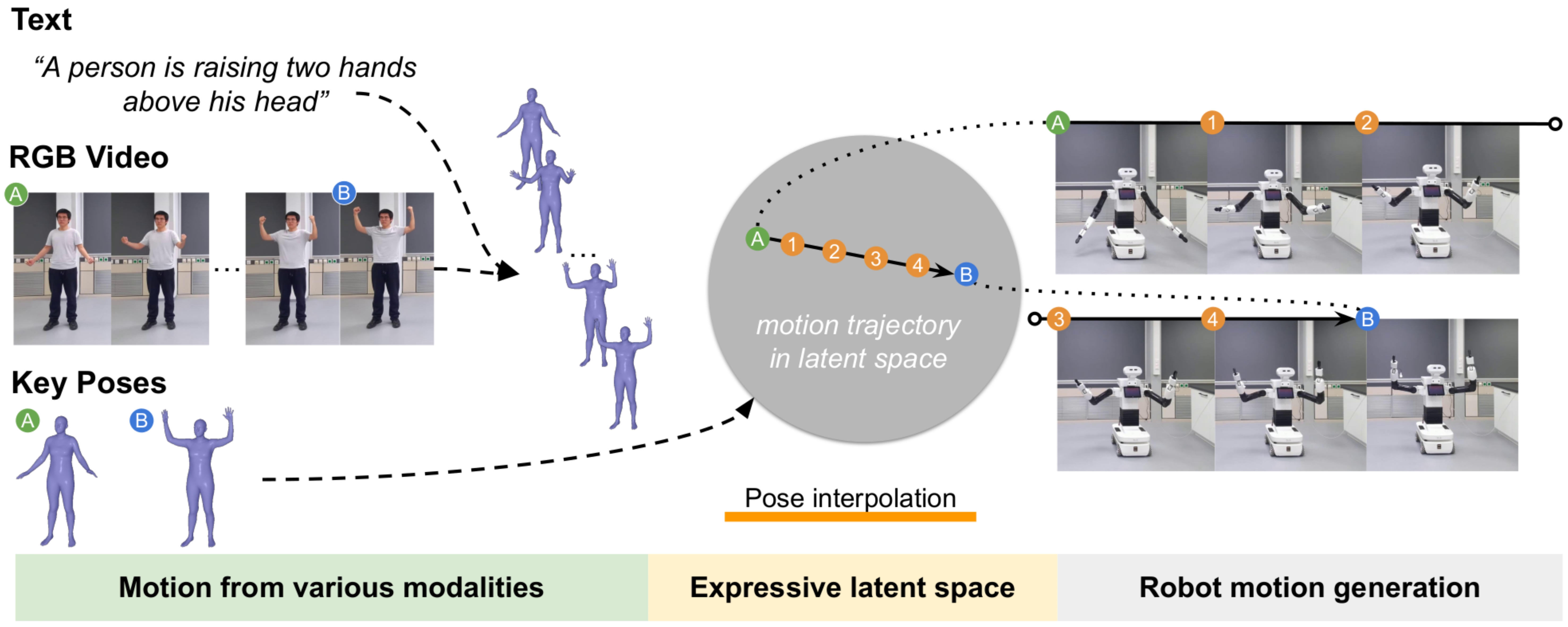
How does it work?
Our human-to-robot motion retargeting connects robot control with diverse source modalities, such as a text description, an RGB video, or key poses. Our approach can encode human skeletons into a shared latent space between humans and robots, and subsequently decode these latent variables into the robot’s joint space, enabling direct robot control. Additionally, our approach facilitates the generation of smooth robot motions between human key poses (represented as green and blue dots) through interpolation within the latent space (indicated by the orange dots).
Human Motion Retargeting From Videos
We estimate the human pose from RGB images using an off-the-shelf pose estimator and we feed our ImitationNet model with the predicted human pose. Our model can control the real TiaGo robot in real-time thanks to its light-weight design with a high-accuracy in the retargeting.
“A human and TiaGo are moving among obstacles”
“A human and TiaGo are moving among obstacles”
“A human and TiaGo are moving among obstacles”
“A human is performing random movements, which TiaGo imitates.”
Human Motion Retargeting From Text commands
We use off-the-shelf text-to-motion models to generate a human motion from textual commands, which we then feed to our ImitationNet model. Our model allows therefore the control of the real TiaGo robot from text commands, which facilitates the deployment of natural human-like movements to robots just using text and without any experts demonstrations or robot data.
“A man touches his head with his right arm”
“A person is dancing by moving the arms”
“A person is performing a handshake”
“A person waves with his two hands.”
Human Motion Retgareting with different robots from textual commands
To showcase the effectiveness of our approach in retargeting more complex robots, we showcase the Nao, Atlas, and JVRC humanoid robots in simulation imitating any human motion provided. Our framework can learn this retargeting with only 40 minutes of training and only using the robot URDF, without any robot annotated data.
Human Motion Retargeting From Key Poses
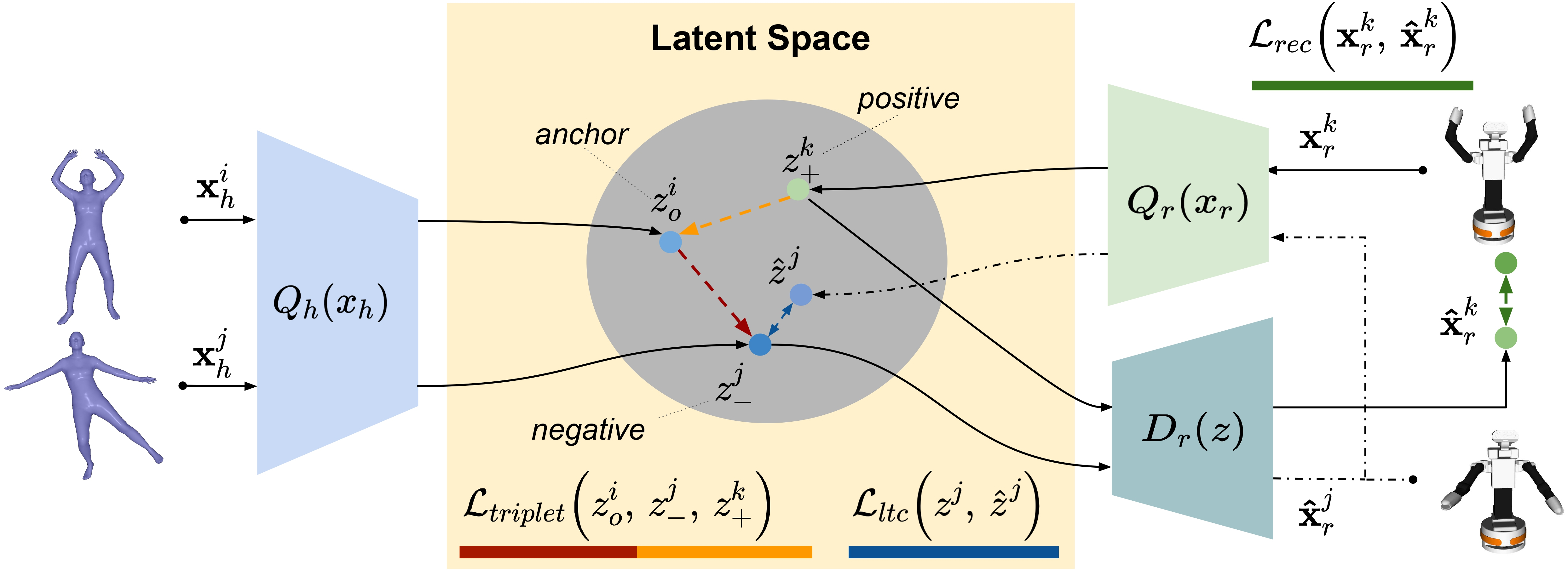
Thanks to our training contrastive learning approach, ImitationNet builts a tractable latent space where similar poses are pushed together while dissimilar are pushed apart. Our model is then able to generate movements between key poses by uniquely interpolating the representation space of two given poses in the latent space.
“From both hands in the floor to the arm span”
“From arm span to placing the left arm to the floor”
“Changing the arm which is closer to the floor”
“From arms on the upper position to bottom position”
Comparison with the baseline
We compare our ImitationNet (TiaGo robot on the left of the simulation) with the previous baseline model (located on the right). Our results shows the smooth and accuracy of the pose retargeting, which outperforms previous state-of-the-art.
BibTeX
@INPROCEEDINGS{10375150,
author={Yan, Yashuai and Mascaro, Esteve Valls and Lee, Dongheui},
booktitle={2023 IEEE-RAS 22nd International Conference on Humanoid Robots (Humanoids)},
title={ImitationNet: Unsupervised Human-to-Robot Motion Retargeting via Shared Latent Space},
year={2023},
volume={},
number={},
pages={1-8},
keywords={Robot motion;Measurement;Interpolation;Three-dimensional displays;Humanoid robots;Aerospace electronics;Skeleton},
doi={10.1109/Humanoids57100.2023.10375150}}