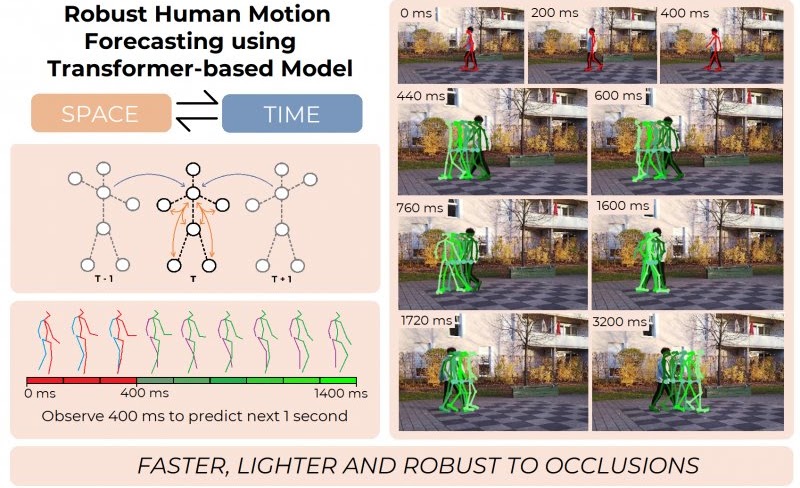
Abstract
Comprehending human motion is a fundamental challenge for developing Human-Robot Collaborative applications. Computer vision researchers have addressed this field by only focusing on reducing error in predictions, but not taking into account the requirements to facilitate its implementation in robots. In this paper, we propose a new model based on Transformer that simultaneously deals with the real time 3D human motion forecasting in the short and long term. Our 2-Channel Transformer (2CH-TR) is able to efficiently exploit the spatio-temporal information of a shortly observed sequence (400ms) and generates a competitive accuracy against the current state-of-the-art. 2CH-TR stands out for the efficient performance of the Transformer, being lighter and faster than its competitors. In addition, our model is tested in conditions where the human motion is severely occluded, demonstrating its robustness in reconstructing and predicting 3D human motion in a highly noisy environment. Our experiment results show that the proposed 2CH-TR outperforms the ST-Transformer, which is another state-of-the-art model based on the Transformer, in terms of reconstruction and prediction under the same conditions of input prefix. Our model reduces in 8.89% the mean squared error of ST-Transformer in short-term prediction, and 2.57% in long-term prediction in Human3.6M dataset with 400ms input prefix.
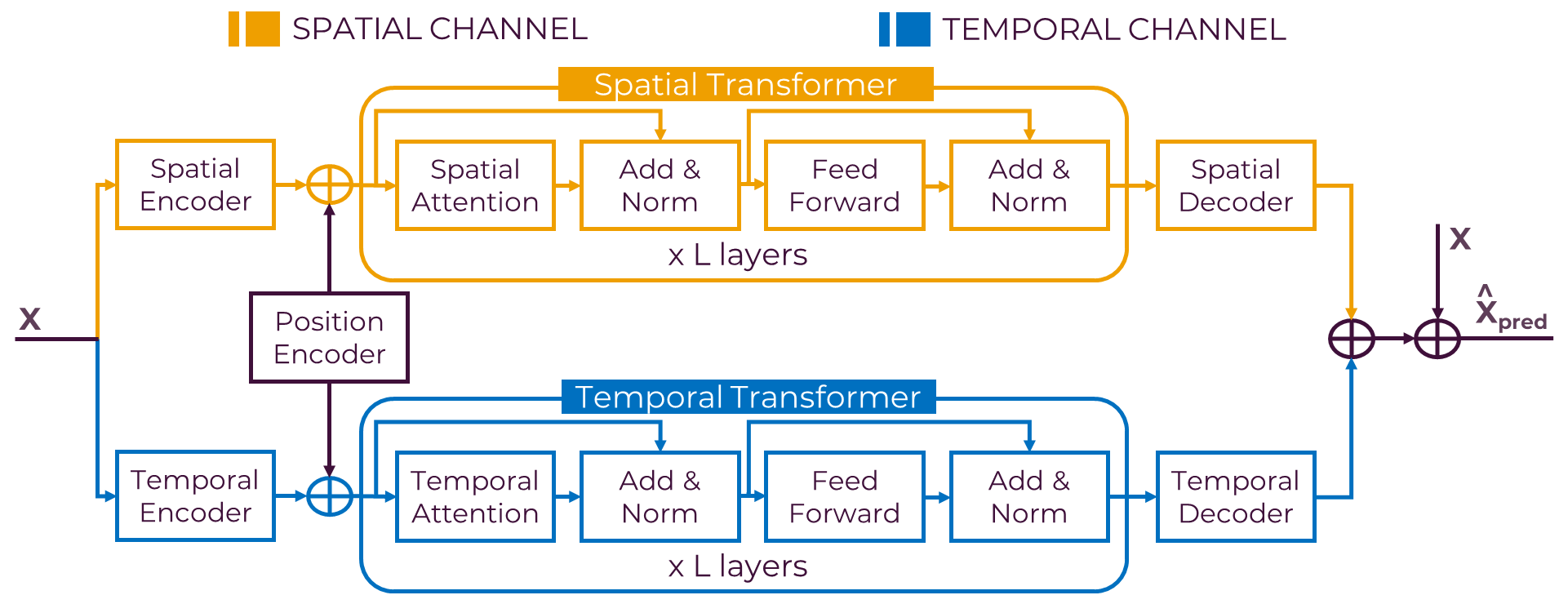
How does it work?
The observed skeleton motion sequence X is projected independently for each channel into an embedding space (ES and ET ) and then positional encoding is injected. Each embedding is fed into L stacked attention layers that extracts dependencies between the sequence using multi-head attention. Finally, each embedding (EˆS and EˆT ) is decoded and projected back to skeleton sequences. Future poses (Xˆpred) are then the result of summing the output of each channel (XˆS and XˆT ) with the residual connection X from input to output.
Human Motion Forecasting
In this task, the aim is to predict future human motion based on past observations in the Human3.6M dataset. Our model is able to obtain competitive results while being more robust and efficient, ideal for its implementation in robotic applications.
“Ground-Truth: Eating”
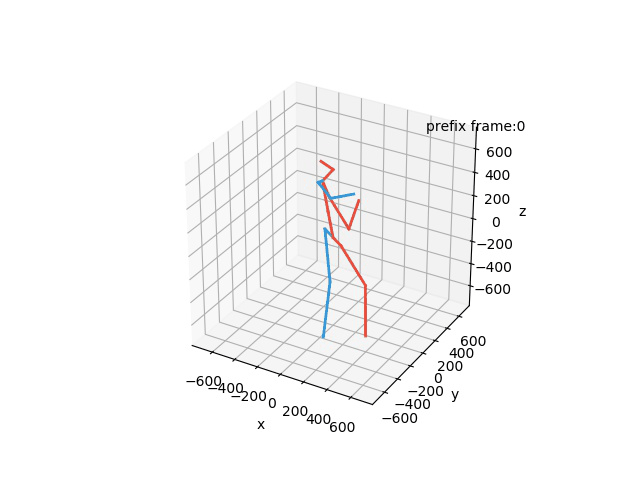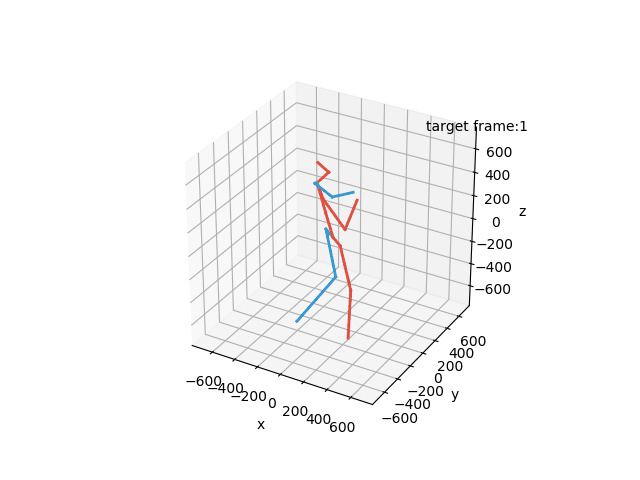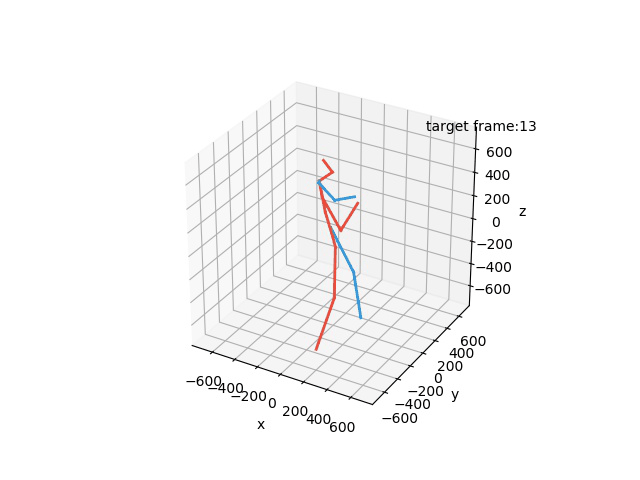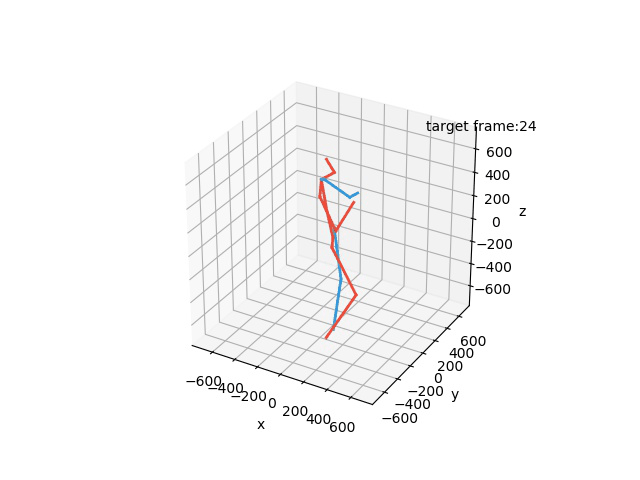
“Prediction: Eating”
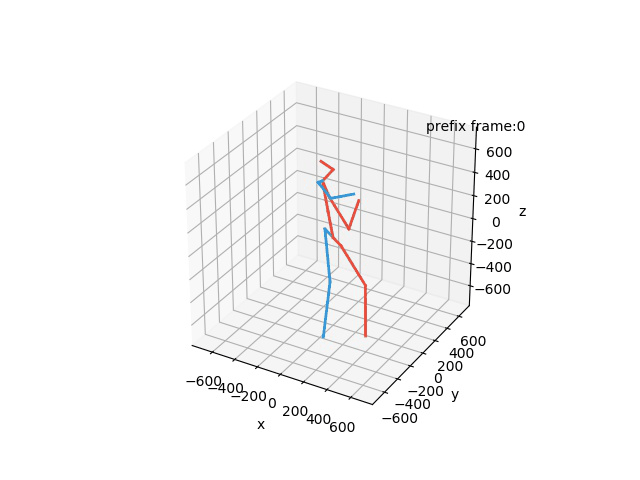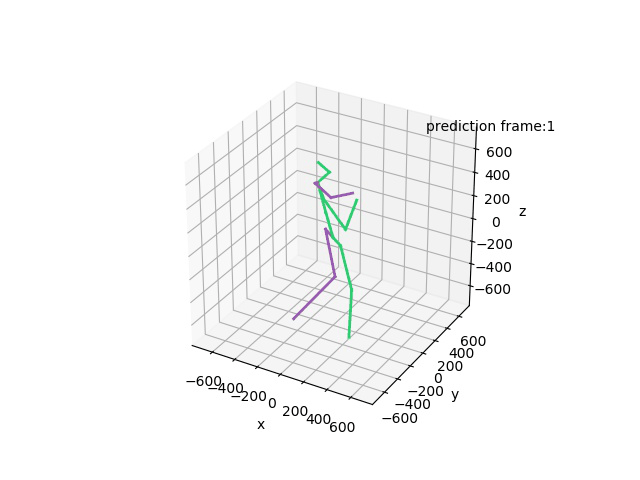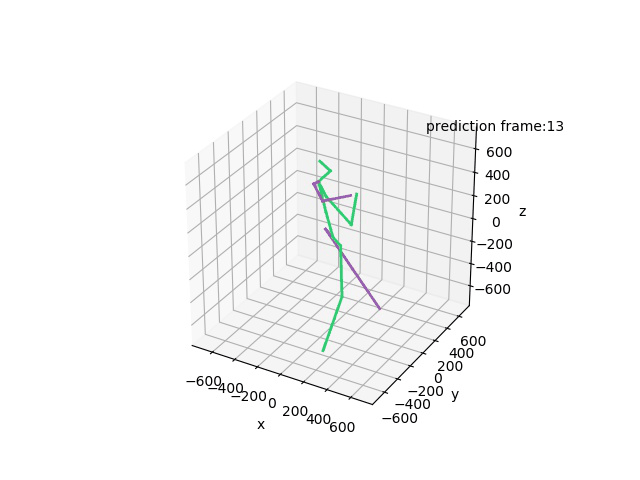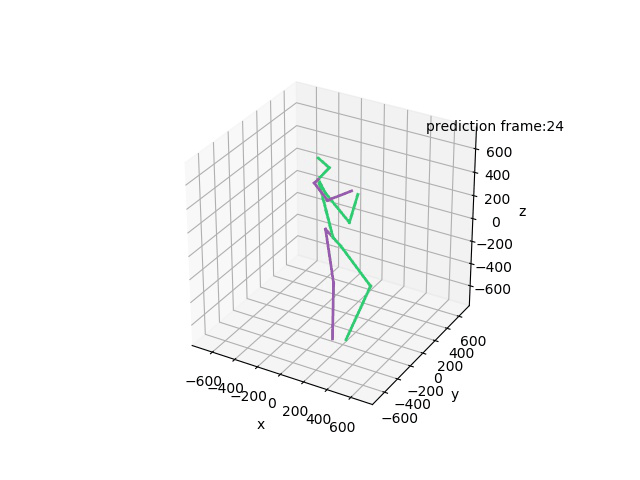
“Ground-Truth: Phoning”
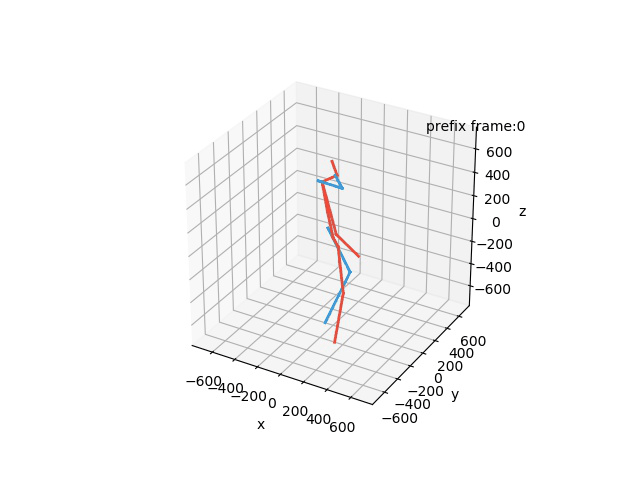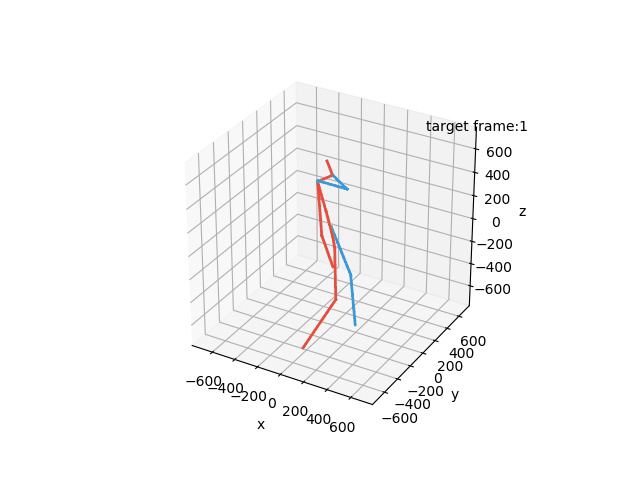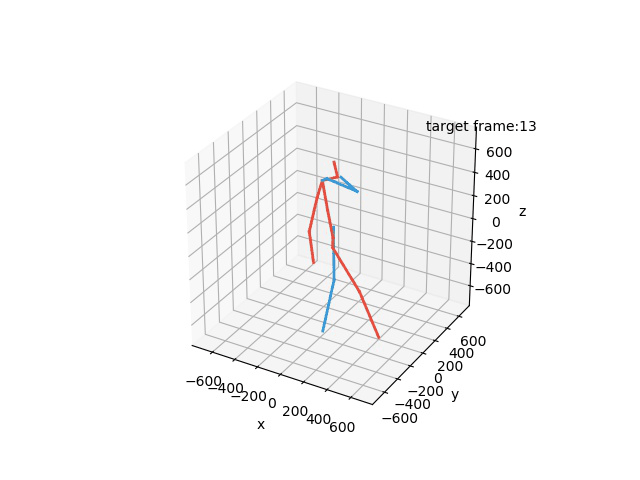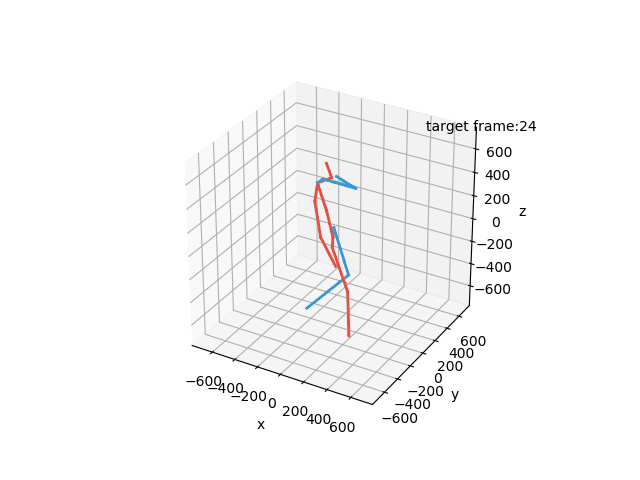
“Prediction: Phoning”
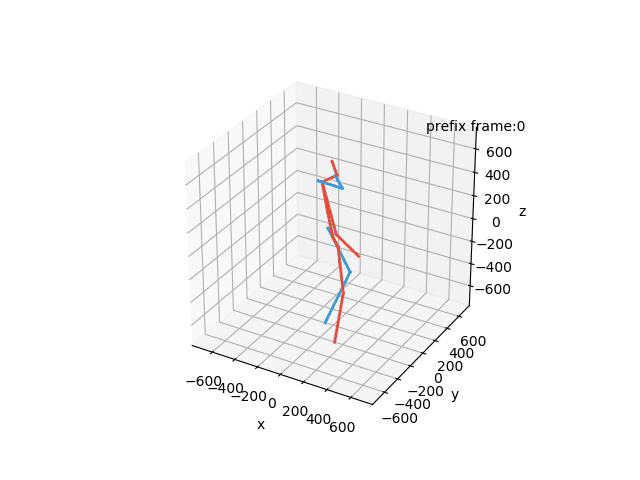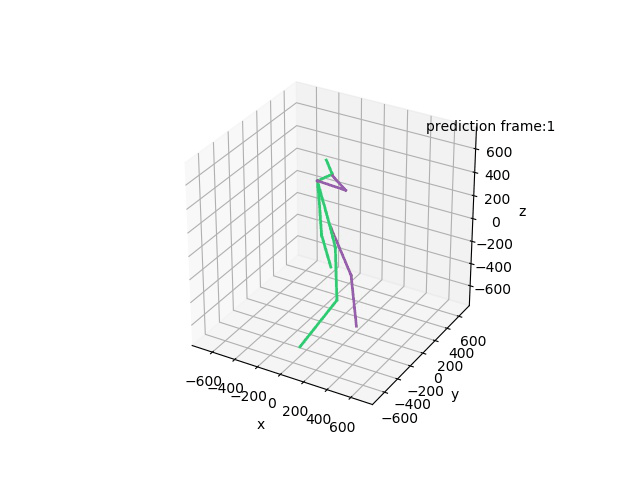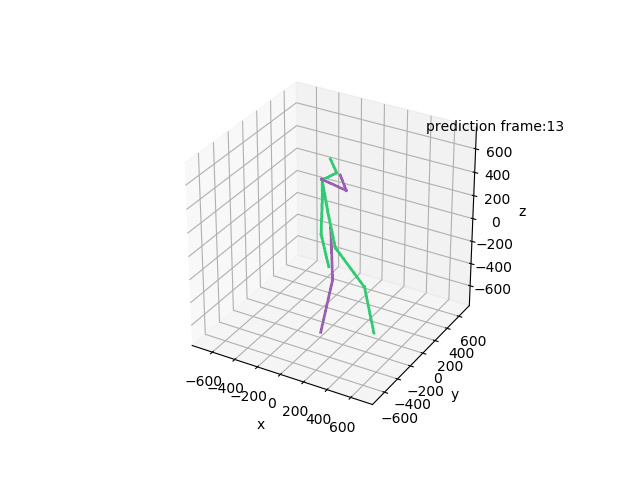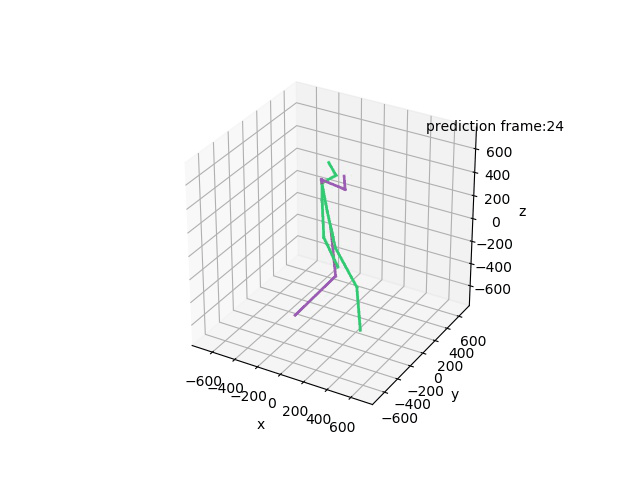
“Ground-Truth: Walking a dog”
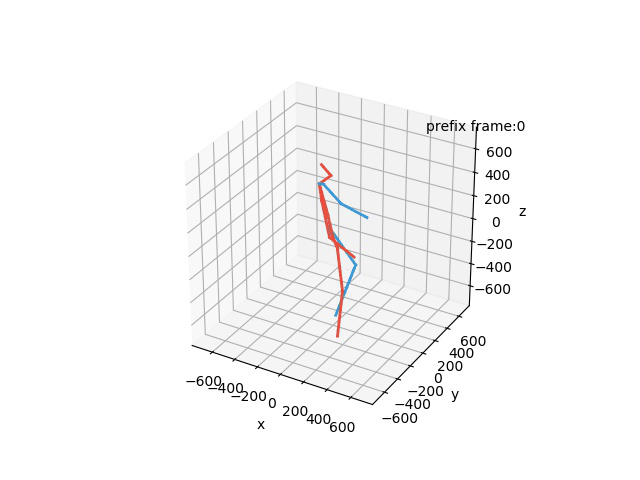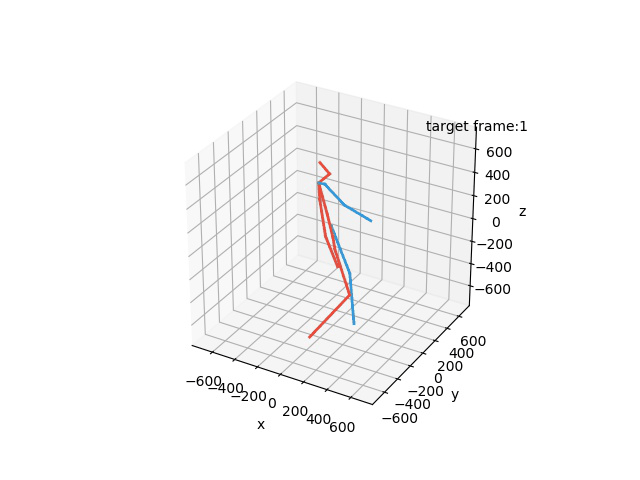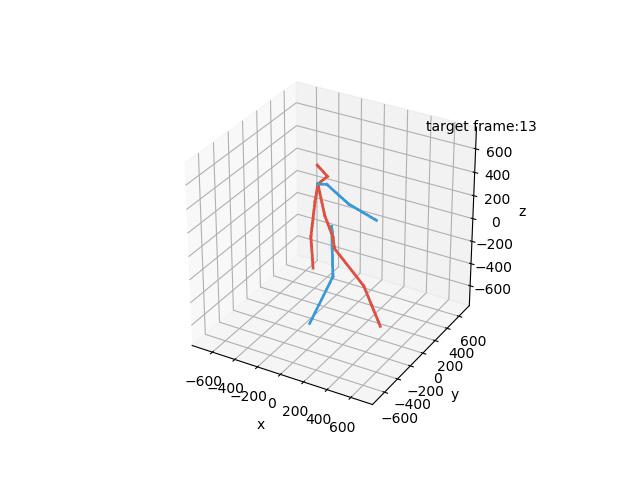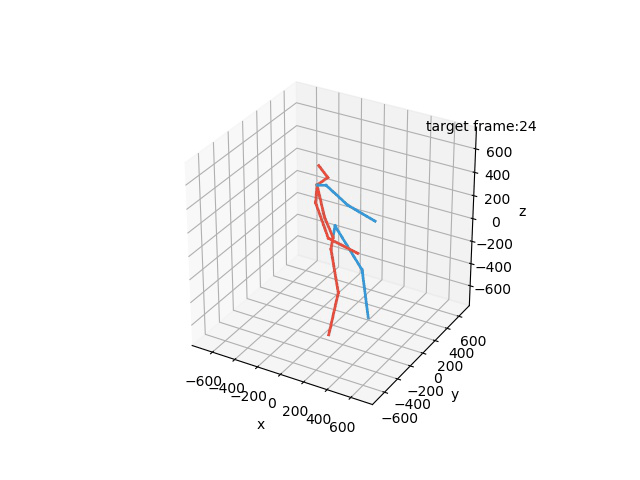
“Prediction: Walking a dog”
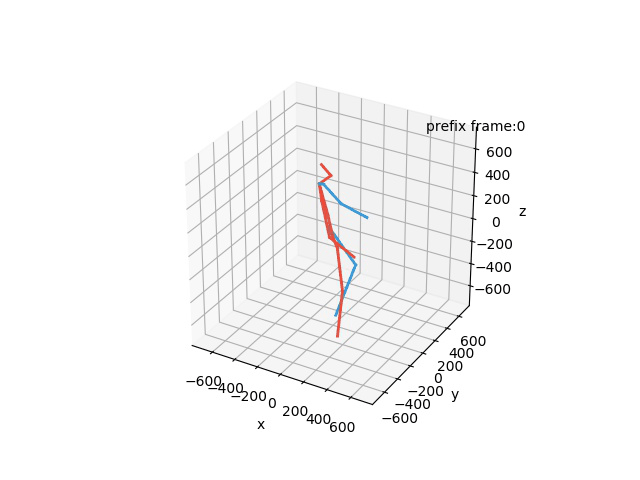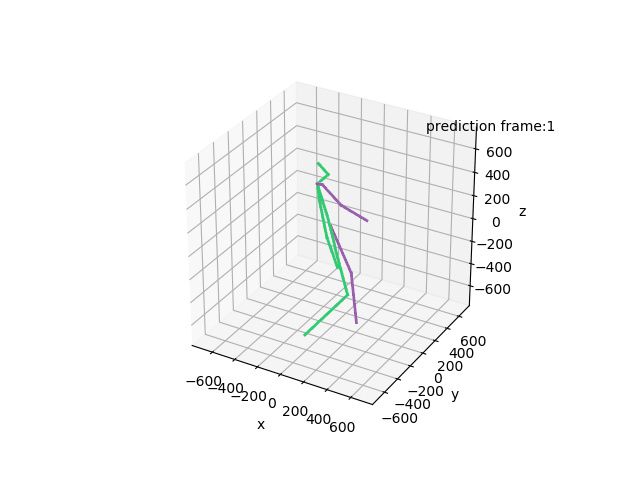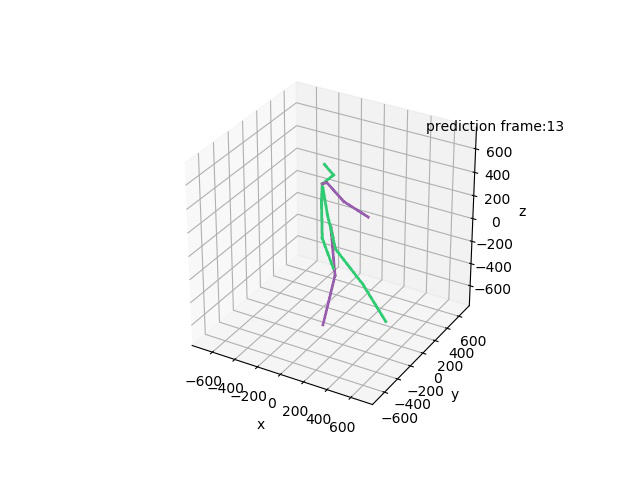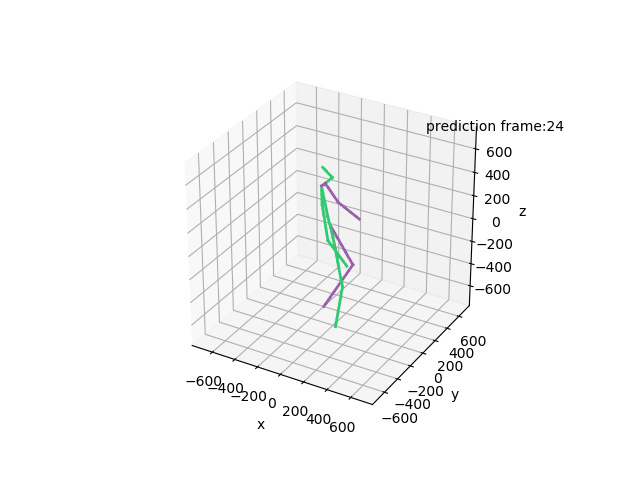
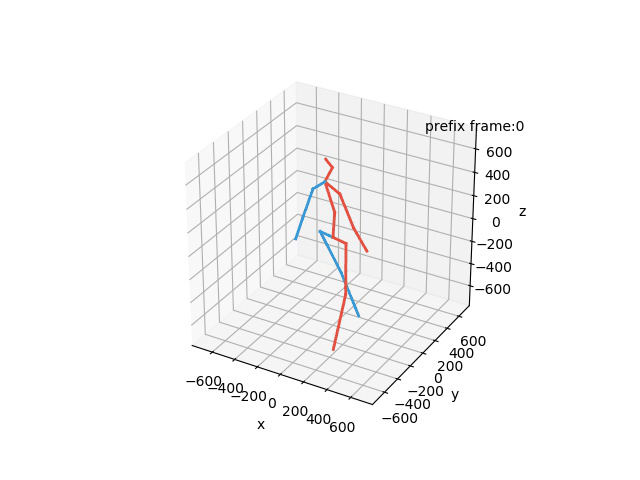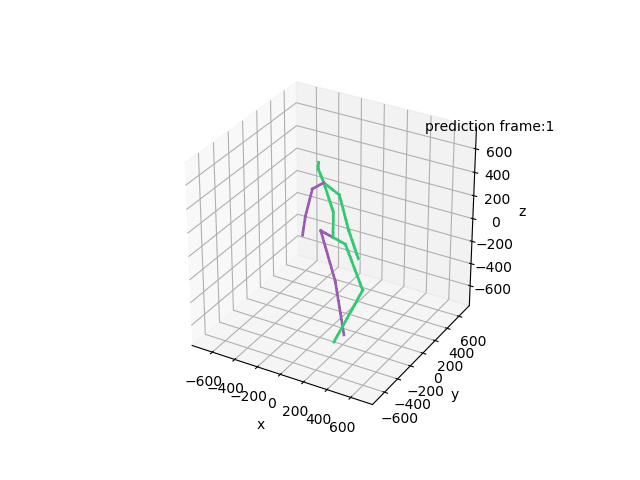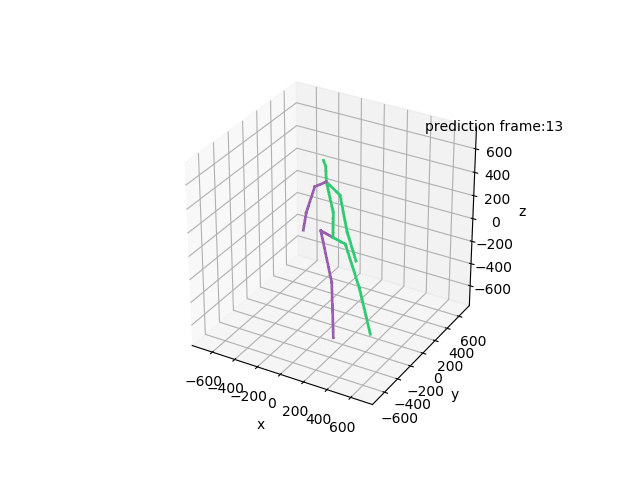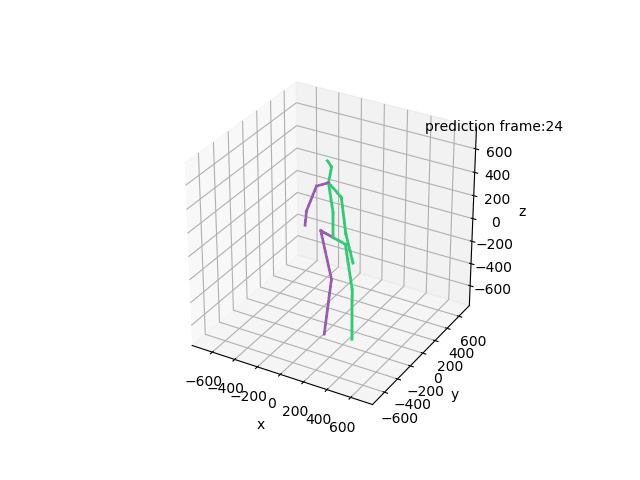
“Ground-Truth: Walking together”
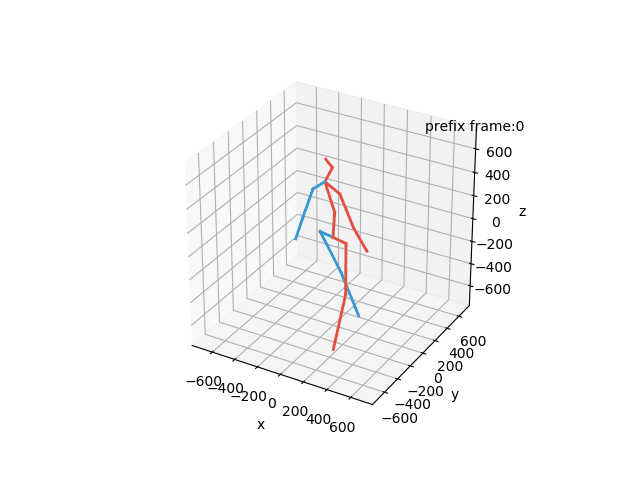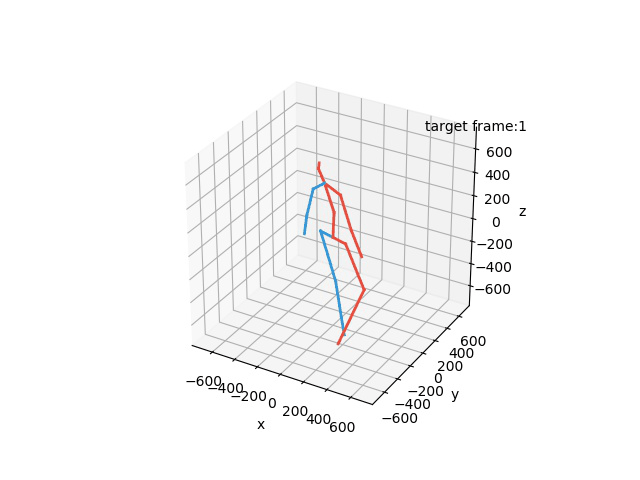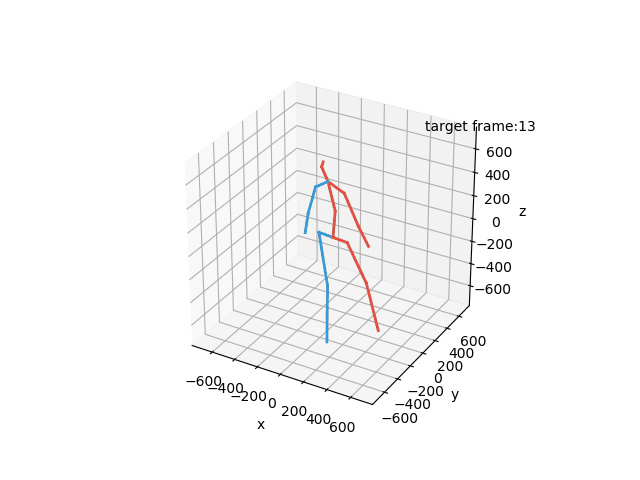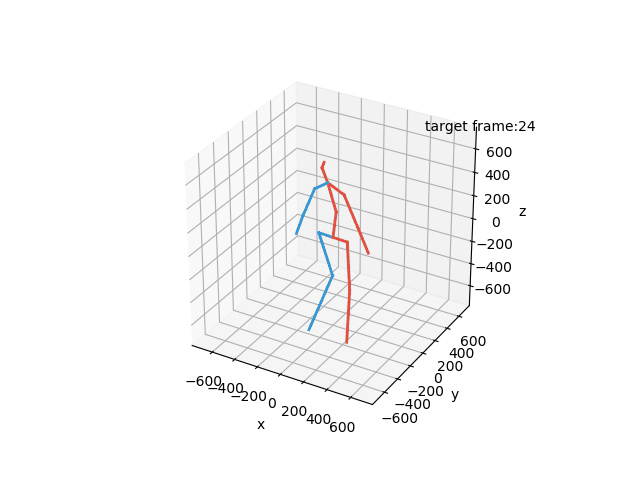
“Prediction: Walking together”
Human Motion Forecasting in the wild
We showcase the robustness of our model by adopting our 2CHTR model in real-world videos. For that, we first estimate the human pose using state-of-the-art pose estimators. We use these estimations to predict the subsequent 1 second of poses. Contrary to prior models, we propose to also synthesize the global rotation of the person, which is essential in this case to determine that the person is turning and therefore better detecting the human intention.

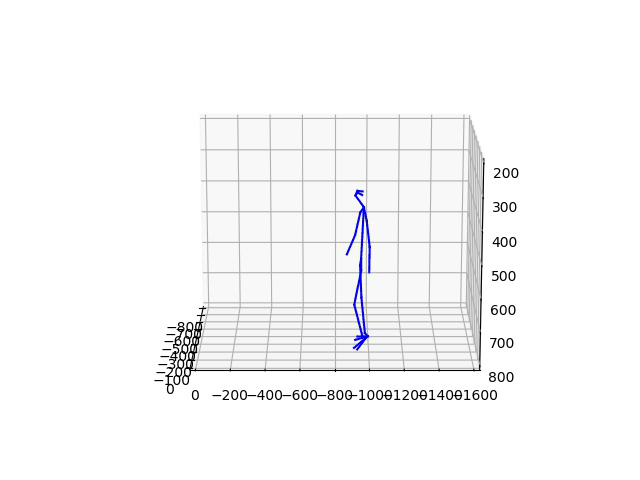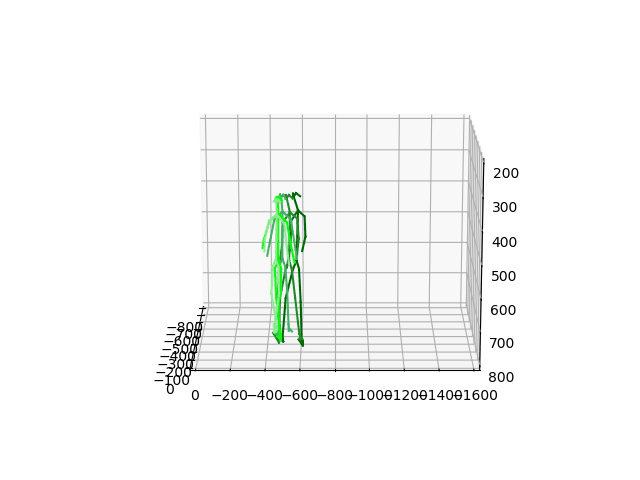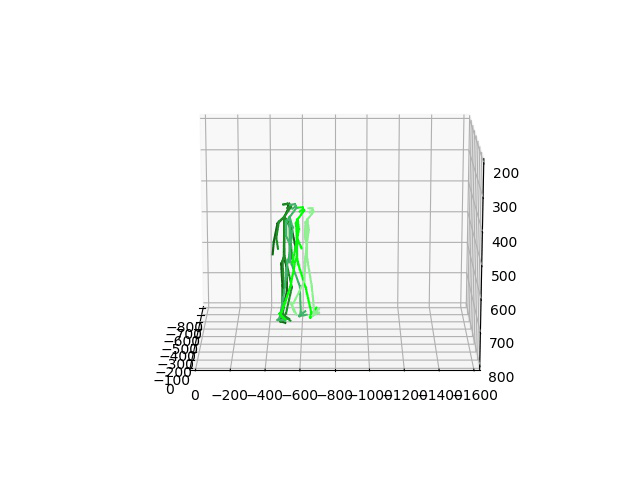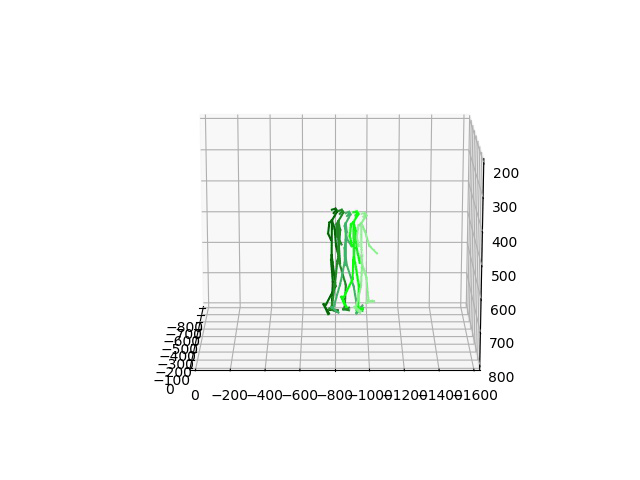
BibTeX
@INPROCEEDINGS{9981877,
author={Mascaro, Esteve Valls and Ma, Shuo and Ahn, Hyemin and Lee, Dongheui},
booktitle={2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
title={Robust Human Motion Forecasting using Transformer-based Model},
year={2022},
volume={},
number={},
pages={10674-10680},
doi={10.1109/IROS47612.2022.9981877}
}